长期以来,人脑一直给研究者们提供着灵感,因为它从某种程度上以有效的生物能量支持我们的计算能力,并且以神经元作为基础激发单位。受人脑的低功耗和快速计算特点启发的神经形态芯片在计算界已经不是一个新鲜主题了。由于复杂算法和架构的快速发展,散热已经成为了一个重大挑战。神经形态计算或许会是超大规模机器和人工智能应用(例如自动驾驶)未来的基石。机器之心在这篇文章中对神经形态计算进行了解读介绍。

神经形态芯片——硅脑
| 「不知为何,人脑——我们自己的生物体——已经弄清楚了如何让人脑在传递 AI 操作上比传统的超级计算机快一百万倍」神经形态是一次机会,它尝试提出一个基于 CMOS 的架构,它能够模仿人脑,从人脑模型中获益,保持能效和成本效益。
——Mark Seager, Intel Fellow,可扩展数据中心 HPC 生态系统的 CTO |
神经形态芯片的最初思想可以追溯到加州理工学院的 Carver Mead 教授在 1990 年发表的一篇论文。Mead 在论文中提出,模拟芯片能够模仿人脑神经元和突触的活动,与模拟芯片的二进制本质不同,模拟芯片是一种输出可以变化的芯片。模仿人脑活动的意义在于我们可以通过它们来学习。传统的芯片在每一次传输中都会保持固定的特定电压。正如 Mead 在 2013 年的对话中提到的一样,当遇到在今天的机器学习任务中被使用的复杂算法和架构的时候,散热就成了芯片行业中***的挑战。
相反,神经形态芯片只需要一个低水平的能耗,因为它的类生物本质。人脑非常节能的一个原因就是,神经冲动在传递的过程中只会放掉一小部分的电量。只有当积累的电量超过一个设定的界限时,信号才会通过。这意味着神经形态芯片是事件驱动的,并且只有在需要的时候才会运作,这就导致了一个更好的运行环境以及更低的能耗。

图片来自 Matt 的「Brain-Inspired-Computing,脑启发计算」,由高通提供
几家公司已经投资了在脑启发计算中的研究。无线技术公司高通在 2014 年的时候展示了引人入目的基于神经形态芯片的机器人。这款机器人能够在智能手机芯片上用修改过的软件实现通常需要专门编程的计算机才能实现的任务。IBM 2014 年生产的 SyNAPSE 芯片也是用脑启发计算架构构建的,它有着难以置信的低功耗,在实时运行中只有 70mW。最近,神经形态再次引起了 IBM 和英特尔这些公司的兴趣。与之前 2013、2014 年那时候意欲制造市场化的产品不同,这次他们希望以研究的目的进行探索。
英特尔在 2012 年就作为***批原型之一提出过一种类似于生物神经网络的自旋—CMOS 混合人工神经网络(spin-CMOS Hybrid ANN)的设计样例。在这个设计中,神经元磁体构成了触发部位。磁隧道结(MTJ)类似于神经元的细胞体,域墙磁体(domain wall magnets,DWM)类似于突触。通道中央区域的自旋势能等于控制激活/非激活状态的细胞体的电势能。CMOS 的检测和传输单元可以被比作传输电信号到接受神经元的突触(如图 1 所示)。

图 1:模拟生物神经网络的自旋—CMOS 示意图
除了低功耗方面的优势,神经形态设备还比较擅长在那些除了超级计算之外的需要模式匹配的任务,例如自动驾驶和实时传感馈送神经网络。换句话说,就是那些需要模拟人脑思考或者「认知计算」的应用,而不是简单的更强能力的复杂计算。正如 Mark Seager 所建议的,神经形态的发展应该聚焦于具有大量浮点向量单元和更高并行度的架构,并且能够以相当统一的方式去处理高度分层记忆。更具体的,关于神经网络,研究的重点是如何通过互联来并行化机器学习的任务,例如英特尔开发的 OmniPath,来解决更大、更复杂的机器学习问题,从而在多节点上进行扩展。目前扩展性限制在数十个到数百个节点之间,这让神经形态芯片的潜能受到了限制。然而,有一件事是合理的,即随着计算神经网络算法和模型的进步,可扩展性可以大幅增加,这会允许神经形态芯片有着更多的进步空间。

图片来自 Matt 的「Brain-Inspired-Computing,脑启发计算」,由高通提供
然而,我们必需承认,尽管神经形态在未来的计算方向上是很有前途的,但是它们仍然处于理论水平,并且还没有被大量地生产。有几种设备据说有神经形态芯片的元素,尚且存在争议,例如 Audience 生产的噪声抑制器,但是它们还未向目前大量的要获得其性能评估的刺激低头。正在进行的研究已经被证明有了克服实现神经形态芯片所遇到的困难的进展性工作,并且给神经形态计算许诺了一个美好的未来。
实验
| 「这个架构能够解决从视觉、声音以到多场景融合的很广泛的问题,并且有潜力通过在计算受到功率和速度限制的设备中集成类脑性能来革新计算机产业。」
—Dharmendra Modha, IBM Fellow |
神经形态的目标是将神经科学作为算法的灵感来从中抽象出关键思想来指导神经形态计算架构的未来发展方向。然而,将我们的生物结构转换为振荡器(oscillators)和半导体的电气设备并不是一件容易的事情。
为了获得神经形态芯片的优势,需要大量的振荡器来进行模仿。今天的深度神经网络早已拥有数百万个节点,更别提朝着拥有更多节点的更复杂的神经网络的努力正在进行。为了达到和人脑相当的能力,需要数十亿个振荡器。使用软件来激发如此巨大的神经网络是特别耗能的,但是用硬件来处理的话就会好很多。为了将所有的节点都布置在指尖大小的芯片上,纳米级的振荡器是必不可少的。
那么问题来了,因为纳米级的振荡器很容易受到噪声的影响。这类振荡器在热扰动下会改变行为,并且它们的特性会随着时间的变化而发生漂移。神经形态计算在对付处理电路中的噪声方面做得不是很好,尽管它可以容忍输入的不可靠性。以分类任务为例,当提供相似的输入时,每次都需要相同的神经网络分类。由于噪声原因,只存在用纳米级振荡器实现神经形态芯片的理论方案,而不是实证实现。然而,一篇最近的文章提出了能够克服这个困难的解决方案,并且成功地模拟了使用专用纳米磁振荡器的神经元集合的振荡行为。

图 2 左边:自旋矩纳米振荡器示意图;中间:振荡器的测量电压随着时间的变化;右边:电压幅值随着电流的变化
研究者已经发现,在特定的动力学条件下,使用自旋矩振荡器可以高信噪比地同义地实现***的分类结果。如图 2 所示,自旋振荡器包括两个题词曾和一个夹在中间的正常间隔组件,和当前磁存储器单元有着完全相同的结构。如上图所示,由充电电流产生的磁化振荡被转换成了电压振荡。之后关于语音数字识别的实验证明自旋矩振荡器在神经形态任务上可以达到当前***的表现。
一个比较简单的波形识别任务被用来研究自旋振荡器在模式识别中的作用。每一个正弦波或者方波都被标记了 8 个离散的红点,任务要求在红点处区分正弦波和方波。图 3b 表明为了创建空间神经网络中蓝色部分所描述的路径,需要很多非线性神经元。如图 3c 所示,路径也可以根据时间来定义,例如根据每一个振荡器幅值的非线性轨迹。每一个输入将会触发振荡器幅值的特定路径,并且,如果时间步长被设定为振荡器松弛时间(relaxation time)的一部分,这将会生成一个瞬态的动态状态。这意味着,与传统的神经元空间分离的神经网络相比,单个振荡器作为在时间上相连的一组虚拟神经元。这个功能创建了一个关于过去事件的记忆池,并且,如果之前的输入有所不同,这会让振荡器在面对相同的输入时有着不同的响应。由于振荡器的松弛时间有限,所以对正弦波和方波的***分离也是可能的。

图 3. 正弦波和方波分类
在硬件上模拟神经网络的迭代训练也能够补偿处理过程中存在的异常。正如上面提到的一样,在模拟硬件的情形下,失真可能在动力学中起到重要的作用。控制这些异常是很重要的,因为网络的性能基本上要依靠对精确参数的训练。
使用由软件训练的深层神经网络转换的 BrainScaleS 晶圆级神经元系统上的尖峰网络来证明在线训练所提供的补偿。然后在每个训练阶段进行一次循环训练,然后记录活动。网络活动首先记录在硬件中,并使用反向传播算法进行处理,以更新参数。研究人员发现,参数更新在训练步骤中不一定要精确,而只需要大致遵循正确的渐变趋势。因此,可以简化该模型中更新的计算。尽管模拟基板的固有变化,这种方法允许快速学习,只需几十次迭代即可达到接近理想软件仿真原型的精度。

图 4 左:软件模型每一批的分类精度随训练迭代步数的变化;右:硬件实施的时候 130 次运行过程中精度的变化
神经形态硬件实现通常会在系统精度上面临另外一个主要的挑战。突触权重的有限精度会降低系统精度,这阻碍了神经形态系统的广泛应用。
纳米级的振荡器应该获得连续的模拟电阻,但是在实际设备中仅仅能够实现几个稳定的电阻状态。一项最近的工作提出了三种校正方法,以学习一级精度(one-level precision)的突触:
- 分布感知量化(DQ/distribution-aware quantization)将不同层中的权重离散到不同的数值。这个方法是基于对网络不同层的权重的观测提出的。
- 量化正则化(QR/quantization regularization)直接在训练过程中学习网络的离散权重。正则化可以以一个固定的梯度来减小一个权重和离它最近的量化水平之间的距离。
- 动态的偏置调节(BT/bias tuning)可以学习***的偏置补偿以最小化对量化的影响。这还可以在基于神经形态系统中的忆阻器中的减轻突触变化的影响。
这三个方法让模型实现了和当前先进水平相当的图像分类精度。使用多层感知机和卷积神经网络分别在 MNIST 数据集和 CIFAR-10 数据集上进行了实验。
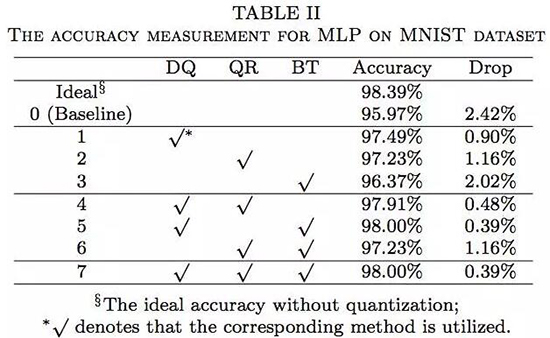
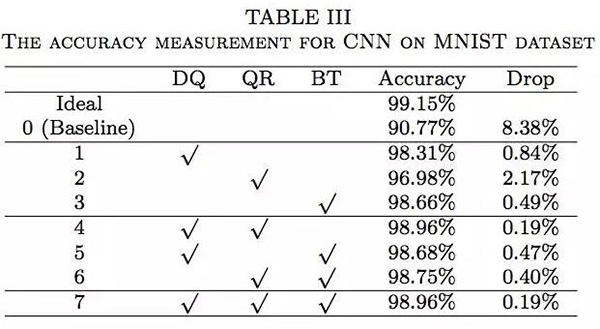
表 2 中的结果表明,与基准准确率相比,当仅仅使用三种精度改善方法中的一种时,准确度会有很大的提升(分别是 1.52%,1.26% 和 0.4%)。当两种或者三种方法被同时使用时,准确率还会更高,接近于理想值。在使用卷积神经网络的时候会有同样的发现。一些组合,例如 QR+BT,与仅仅使用 QR 相比,准确度并没有提升(如表 2 所示)。这很可能是因为 MNIST 是一个相对简单的数据库,而且这三种方法对准确度的改善已经快速地达到了饱和水平。在多层感知机和卷积神经网络中,准确度下降被控制在了 0.19%(MNIST 数据集)和 5.53%(CIFRAR-10 数据集),与未使用这三种方法的系统相比,准确度的下降明显要低很多。
结论
随着机器学习算法和模型的进步,新颖的架构将会变得迫切需要。由于低功耗和高度并行化的快速计算速度,神经形态设备在人工智能和认知计算的应用中有着巨大的潜能。尽管当前的神经形态芯片仍然处于理论水平,正在朝着实际应用和市场化产品进行,研究者已经展示了一些有前景的研究。这是未来的一个方向,一个能够大大地革新计算世界的有潜力的方向。
原文:https://syncedreview.com/2017/04/08/the-future-of-computing-neuromorphic/
【本文是51CTO专栏机构“机器之心”的原创文章,微信公众号“机器之心( id: almosthuman2014)”】