在实际开发过程中,笔者见过太多故障是因为超时没有设置或者设置的不对而造成的。而这些故障都是因为没有意识到超时设置的重要性而造成的。如果应用不设置超时,则可能会导致请求响应慢,慢请求累积导致连锁反应,甚至应用雪崩。而有些中间件或者框架在超时后会进行重试(如设置超时重试两次),读服务天然适合重试,但写服务大多不能重试(如写订单,如果写服务是幂等,则重试是允许的),重试次数太多会导致多倍请求流量,即模拟了DDoS攻击,后果可能是灾难,因此,务必设置合理的重试机制,并且应该和熔断、快速失败机制配合。在进行代码Review时,一定记得Review超时与重试机制。
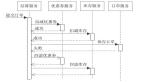
本文主要从Web应用/服务化应用的角度出发介绍如何设置超时与重试(系统层面的超时设置本文没有涉及),而Web应用需要在如下链条中设置超时与重试机制。

从上图来看,在整个链条中的每一个点都要考虑设置超时与重试机制。而其中最重要的超时设置是网络连接/读/写的超时时间设置。
本文将按照如下分类进行超时与重试机制的讲解。
- 代理层超时与重试:如Haproxy、Nginx、Twemproxy,这些组件实现代理功能,如Haproxy和Nginx可以实现请求的负载均衡。而Twemproxy可以实现Redis的分片代理。需要设置代理与后端真实服务器之间的网络连接/读/写超时时间。
- Web容器超时:如Tomcat、Jetty等,提供HTTP服务运行环境的。需要设置客户端与容器之间的网络连接/读/写超时时间,和在此容器中默认Socket网络连接/读/写超时时间。
- 中间件客户端超时与重试:如JSF(京东SOA框架)、Dubbo、JMQ(京东消息中间件)、CXF、Httpclient等,需要设置客户的网络连接/读/写超时时间与失败重试机制。
- 数据库客户端超时:如Mysql、Oracle,需要分别设置JDBC Connection、Statement的网络连接/读/写超时时间。事务超时时间,获取连接池连接等待时间。
- NoSQL客户端超时:如Mongo、Redis,需要设置其网络连接/读/写超时时间,获取连接池连接等待时间。
- 业务超时:如订单取消任务、超时活动关闭。还有如通过Future#get(timeout,unit)限制某个接口的超时时间。
- 前端Ajax超时:浏览器通过Ajax访问时的网络连接/读/写超时时间。
从如上分类可以看出,其中最重要的超时设置是网络相关的超时设置。
一、代理层超时与重试
对于代理层我们以Nginx和Twemproxy案例来讲解。首先,看下Nginx的相关超时设置。
1. Nginx
Nginx主要有四类超时设置:客户端超时设置、DNS解析超时设置、代理超时设置,如果使用ngx_lua,则还有lua相关的超时设置。
(1) 客户端超时设置
对于客户端超时主要设置有读取请求头超时时间、读取请求体超时时间、发送响应超时时间、长连接超时时间。通过客户端超时设置避免客户端恶意或者网络状况不佳造成连接长期占用,影响服务端的可处理的能力。
- client_header_timeout time:设置读取客户端请求头超时时间,默认为60s,如果在此超时时间内客户端没有发送完请求头,则响应408(RequestTime-out)状态码给客户端。
- client_body_timeout time:设置读取客户端内容体超时时间,默认为60s,此超时时间指的是两次成功读操作间隔时间,而不是发送整个请求体的超时时间,如果在此超时时间内客户端没有发送任何请求体,则响应408(RequestTime-out)状态码给客户端。
- send_timeout time:设置发送响应到客户端的超时时间,默认为60s,此超时时间指的也是两次成功写操作间隔时间,而不是发送整个响应的超时时间。如果在此超时时间内客户端没有接收任何响应,则Nginx关闭此连接。
- keepalive_timeout timeout [header_timeout]:设置HTTP长连接超时时间,其中,第一个参数timeout是告诉Nginx长连接超时时间是多少,默认为75s。第二个参数header_timeout是用于设置响应头“Keep-Alive: timeout=time”,即告知客户端长连接超时时间。两个参数可以不一样,“Keep-Alive:timeout=time”响应头可以在Mozilla和Konqueror系列浏览器起作用,而MSIE长连接默认大约为60s,而不会使用“Keep-Alive: timeout=time”。如Httpclient框架会使用“Keep-Alive: timeout=time”响应头的超时(如果不设置默认,则认为是永久)。如果timeout设置为0,则表示禁用长连接。
此参数要配合keepalive_disable 和keepalive_requests一起使用。keepalive_disable 表示禁用哪些浏览器的长连接,默认值为msie6,即禁用一些老版本的MSIE的长连接支持。keepalive_requests参数作用是一个客户端可以通过此长连接的请求次数,默认为100。
首先,浏览器在请求时会通过如下请求头告知服务器是否支持长连接。
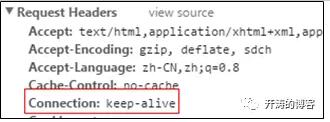
http/1.0默认是关闭长连接的,需要添加HTTP请求头“Connection:Keep-Alive”才能启用。而http/1.1默认启用长连接,需要添加HTTP请求头“Connection: close”才关闭。
接着,如果Nginx设置keepalive_timeout 5s,则浏览器会收到如下响应头。
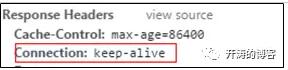
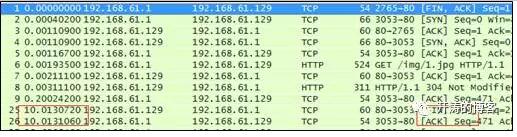
下图是wireshark抓包,可以看到后两次请求没有三次握手。

如果Nginx设置keepalive_timeout 10s 10s,则浏览器会收到如下响应头。
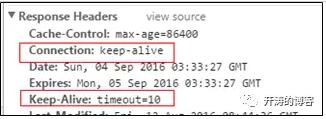
服务器端会在10s后发送FIN主动关闭连接。
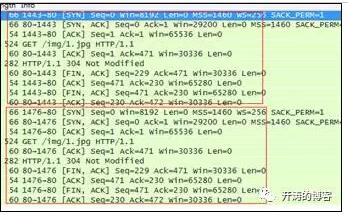
如果Nginx设置keepalive_timeout为75s 30s。
如下是Chrome浏览器的Wireshark抓包,在45秒时,Chrome发送了TCPKeep-Alive来保活TCP连接,在第57秒时,浏览器又发出了一次请求。而132秒时,Nginx发出了FIN来关闭连接(75秒连接没活跃了)。

如下是IE浏览器抓包数据,在请求后第65秒左右时,浏览器重置了连接。
![]()
可以看出不同浏览器超时处理方式不一样,而HTTP响应头“Keep-Alive: timeout=30”对Chrome和IE都没有起作用。
接着,如果keepalive_timeout 0,则浏览器会收到如下响应头。
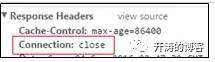
对于客户端超时设置,要根据实际场景来决定,如果是短连接服务,则可以考虑设置的短一些,如果是文件上传,则需要考虑设置的时间长一些。另外,笔者见过很多人长连接并没有配置正确,建议配置完成后通过抓包查看长连接是否起作用了。keepalive_timeout和keepalive_requests是控制长连接的两个维度,只要其中一个到达设置的阈值连接就会被关闭。
(2) DNS解析超时设置
resolver_timeout 30s:设置DNS解析超时时间,默认为30s。其配合resolver address ... [valid=time]进行DNS域名解析。当在Nginx中使用域名时,就需要考虑设置这两个参数。在社区版Nginx中采用如下配置。
upstream backend {
server c0.3.cn;
server c1.3.cn;
}
- 1.
- 2.
- 3.
- 4.
如上两个域名会在Nginx解析配置文件的阶段被解析成IP地址并记录到upstream上,当这两个域名对应的IP地址发生变化时,该upstream不会更新。Nginx商业版是支持动态更新的。
一种简单办法是使用如下方式,每次都会动态解析域名,这种情况在多域名情况下比较麻烦,实现就不优雅了。
location /test {
proxy_pass http://c0.3.cn;
}
- 1.
- 2.
- 3.
如果使用Openresty,则可以通过Lua库lua-resty-dns进行DNS解析。
localresolver = require "resty.dns.resolver"
local r, err = resolver:new{
nameservers = {"8.8.8.8",{"8.8.4.4", 53} },
retrans = 5, -- 5 retransmissions on receive timeout
timeout = 2000, -- 2 sec
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
当使用Nginx 1.5.8、1.7.4及遇到
could not be resolved(110:Operation timed out);
- 1.
或者
wrong ident 37278 response for ***.jd.local, expected 33517
unexpected response for ***.jd.local
- 1.
- 2.
可能是遇到了如下BUG(http://nginx.org/en/CHANGES-1.6、http://nginx.org/ en/CHANGES-1.8)。
Bugfix: requests might hang if resolver was usedand a timeout
occurred during a DNS request.
- 1.
- 2.
请考虑升级到Nginx 1.6.2、1.7.5或者在Nginx本机部署dnsmasq提升DNS解析性能。
(3) 代理超时设置
Nginx配置如下所示。
upstream backend_server {
server 192.168.61.1:9080 max_fails=2 fail_timeout=10s weight=1;
server 192.168.61.1:9090 max_fails=2 fail_timeout=10s weight=1;
}
server {
……
location /test {
proxy_connect_timeout 5s;
proxy_read_timeout 5s;
proxy_send_timeout 5s;
proxy_next_upstream error timeout;
proxy_next_upstream_timeout 0;
proxy_next_upstream_tries 0;
proxy_pass http://backend_server;
add_header upstream_addr $upstream_addr;
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
backend_server定义了两个上游服务器192.168.61.1:9080(返回hello)和192.168.61.1:9090(返回hello2)。
如上指令主要有三组配置:网络连接/读/写超时设置、失败重试机制设置、upstream存活超时设置。
网络连接/读/写超时设置。
- proxy_connect_timeout time:与后端/上游服务器建立连接的超时时间,默认为60s,此时间不超过75s。
- proxy_read_timeout time:设置从后端/上游服务器读取响应的超时时间,默认为60s,此超时时间指的是两次成功读操作间隔时间,而不是读取整个响应体的超时时间,如果在此超时时间内上游服务器没有发送任何响应,则Nginx关闭此连接。
- proxy_send_timeout time:设置往后端/上游服务器发送请求的超时时间,默认为60s,此超时时间指的是两次成功写操作间隔时间,而不是发送整个请求的超时时间,如果在此超时时间内上游服务器没有接收任何响应,则Nginx关闭此连接。
对于内网高并发服务,请根据需要调整这几个参数,比如内网服务TP999为1s,可以将连接超时设置为100~500毫秒,而读超时可以为1.5~3秒左右。
失败重试机制设置。
proxy_next_upstream error | timeout | invalid_header | http_500 | http_502 | http_503 | http_504 |http_403 | http_404 | non_idempotent | off ...:
- 1.
配置什么情况下需要请求下一台上游服务器进行重试。默认为“errortimeout”。error表示与上游服务器建立连接、写请求或者读响应头出错。timeout表示与上游服务器建立连接、写请求或者读响应头超时。invalid_header表示上游服务器返回空的或错误的响应头。http_XXX表示上游服务器返回特定的状态码。non_idempotent表示RFC-2616定义的非幂等HTTP方法(POST、LOCK、PATCH),也可以在失败后重试下一台上游服务器(即默认幂等方法GET、HEAD、PUT、DELETE、OPTIONS、TRACE才可以重试)。off表示禁用重试。
重试不能无限制进行,因此,需要如下两个指令控制重试次数和重试超时时间。
- proxy_next_upstream_tries number:设置重试次数,默认0表示不限制,注意此重试次数指的是所有请求次数(包括第一次和之后的重试次数之和)。
- proxy_next_upstream_timeout time:设置重试最大超时时间,默认0表示不限制。
即在proxy_next_upstream_timeout时间内允许proxy_next_upstream_tries次重试。如果超过了其中一个设置,则Nginx也会结束重试并返回客户端响应(可能是错误码)。
如下配置表示当error/timeout时重试upstream中的下一台上游服务器,如果重试的总时间超出了6s或者重试了1次,则表示重试失败(因为之前已经请求一次了,所以还能重试一次),Nginx结束重试并返回客户端响应。
proxy_next_upstream error timeout;
proxy_next_upstream_timeout 6s;
proxy_next_upstream_tries 2;
- 1.
- 2.
- 3.
(4) upstream存活超时设置
max_fails和fail_timeout:配置什么时候Nginx将上游服务器认定为不可用/不存活。当上游服务器在fail_timeout时间内失败了max_fails次,则认为该上游服务器不可用/不存活。并在接下来的fail_timeout时间内从upstream摘掉该节点(即请求不会转发到该上游服务器)。
什么情况下被认定为失败呢?其由 proxy_next_upstream定义,不过,不管 proxy_next_upstream如何配置,error, timeout and invalid_header 都将被认为是失败。
如server 192.168.61.1:9090max_fails=2 fail_timeout=10s;表示在10s内如果失败了2次,则在接下来的10s内认定该节点不可用/不存活。这种存活检测机制是只有当访问该上游服务器时,采取惰性检查,可以使用ngx_http_upstream_check_module配置主动检查。
max_fails设置为0表示不检查服务器是否可用(即认为一直可用),如果upstream中仅剩一台上游服务器时,则该服务器是不会被摘除的,将从不被认为不可用。
(5) ngx_lua超时设置
当我们使用ngx_lua时,也请考虑设置如下网络连接/读/写超时。
lua_socket_connect_timeout 100ms;
lua_socket_send_timeout 200ms;
lua_socket_read_timeout 500ms;
- 1.
- 2.
- 3.
在使用lua时,我们会按照如下策略进行重试。
if (status == 502 or status == 503 or status ==504) and request_time < 200 then
resp =capture(proxy_uri)
status =resp.status
body =resp.body
request_timerequest_time = request_time + tonumber(var.request_time) * 1000
end
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
即如果状态码是500/502/503/504时,并且该次请求耗时在200毫秒以内,则我们进行一次重试。
2. Twemproxy
Twemproxy是Twitter开源的Redis和Memcache代理中间件,其目的是减少与后端缓存服务器的连接数。
- timeout:表示与后端服务器建立连接、接收响应的超时时间,默认永不超时。
- server_retry_timeout和server_failure_limit:当开启auto_eject_hosts,即当后端服务器不可用时自动摘除这些节点并在一定时间后进行重试。server_failure_limit设置连续失败多少次后将节点临时摘除,server_retry_timeout设置摘除节点后等待多久进行重试,从而保证不永久性的将节点摘除。
二、Web容器超时
笔者生产环境用的Java Web容器是Tomcat,本部分将以Tomcat8.5作为例子进行讲解。
- connectionTimeout:配置与客户端建立连接超时时间,从接收到连接后在配置的时间内还没有接收到客户端请求行时,将被认定为连接超时,默认为60000(60s)。
- socket.soTimeout:从客户端读取请求数据的超时时间,默认同connectionTimeout,NIO and NIO2 支持该配置。
- asyncTimeout:Servlet 3异步请求的超时时间,默认为30000(30s)。
- disableUploadTimeout 和connectionUploadTimeout:当配置disableUploadTimeout为false时(默认为true,和connectionTimeout一样),文件上传将使用connectionUploadTimeout作为超时时间。
- keepAliveTimeout和maxKeepAliveRequests:和Nginx配置类似。keepAliveTimeout默认为connectionTimeout,配置-1表示永不超时。maxKeepAliveRequests默认为100。
三、中间件客户端超时与重试
JSF是京东自研的SOA框架,主要有三个组件:注册中心、服务提供端、服务消费端。
- 首先是服务提供端/消费端与注册中心之间的进行服务注册/发现时可以配置timeout(调用注册中心超时时间,默认为5s)和connectTimeout(连接注册中心的超时时间,默认为20s)。
- 服务提供端可以配置timeout(服务端调用超时,默认为5s)。
- 服务消费端可以配置timeout(调用端调用超时时间,默认为5s),connectTimeout(建立连接超时时间,默认为5s),disconnectTimeout(断开连接/等待结果超时时间,默认为10s),reconnect(调用端重连死亡服务端的间隔,配置小于0表示不重连,默认为10s),heartbeat(调用端往服务端发心跳包间隔,配置小于0代表不发送,默认为30s),retries(失败后重试次数,默认0不重试)。
Dubbo也有类似的配置,在此就不阐述了。
JMQ是京东消息中间件,主要有四个组件:注册中心、Broker(JMQ的服务端实例,生产和消费消息都跟它交互)、生产者、消费者。
- 首先是生产者/消费者与Broker进行发送/接收消息时可以配置connectionTimeout(连接超时)、sendTimeout(发送超时)、soTimeout(读超时)。
- 生产者可以配置retryTimes(发送失败后的重试次数,默认为2次)。
- 消费者可以配置pullTimeout(长轮询超时时间,即拉取消息超时时间)、maxRetrys(最大重试次数,对于消费者要允许无限制重试,即一直拉取消息)、retryDelay(重试延迟,通过exponential配置延迟增加倍数一直增加到maxRetryDelay)、maxRetryDelay(最大重试延迟)。消费者还需要配置应答超时时间(服务端需要等待客户端返回应答才能移除消息,如果没有应答返回,则会等待应答超时,在这段时间内锁定的消息不能被消费,必须等待超时后才能被消费)。
对于消息中间件我们实际应用中关注超时配置会少一些,因为生产者默认配置了重试次数,可能会存在重复消息,消费者需要进行去重处理。
CXF可以通过如下方式配置CXF客户端连接超时、等待响应超时和长连接。
HTTPClientPolicy httpClientPolicy = new HTTPClientPolicy();
httpClientPolicy.setConnectionTimeout(30000);//默认为30s
httpClientPolicy.setReceiveTimeout(60000); //默认为60s
httpClientPolicy.setConnection(ConnectionType.KEEP_ALIVE);//默认为Keep- Alive
((HTTPConduit)client.getConduit()).setClient(httpClientPolicy);
- 1.
- 2.
- 3.
- 4.
- 5.
Httpclient 4.2.x可以通过如下代码配置网络连接、等待数据超时时间。
HttpParams params = new BasicHttpParams();
//设置连接超时时间
Integer CONNECTION_TIMEOUT = 2 * 1000; //设置请求超时2秒钟
Integer SO_TIMEOUT = 2 * 1000; //设置等待数据超时时间2秒钟
Long CONN_MANAGER_TIMEOUT = 1L * 1000; //定义了当从ClientConnectionManager中检索ManagedClientConnection实例时使用的毫秒级的超时时间
params.setIntParameter(CoreConnectionPNames.CONNECTION_TIMEOUT,CONNECTION_TIMEOUT);
params.setIntParameter(CoreConnectionPNames.SO_TIMEOUT,SO_TIMEOUT);
//在提交请求之前,测试连接是否可用
params.setBooleanParameter(CoreConnectionPNames.STALE_CONNECTION_CHECK,true);
//这个参数期望得到一个java.lang.Long类型的值。如果这个参数没有被设置,则连接请求就不会超时(无限大的超时时间)
params.setLongParameter(ClientPNames.CONN_MANAGER_TIMEOUT,CONN_MANAGER_TIMEOUT);
PoolingClientConnectionManager conMgr = new PoolingClientConnectionManager();
conMgr.setMaxTotal(200);//设置最大连接数
//是路由的默认最大连接(该值默认为2),限制数量实际使用DefaultMaxPerRoute并非MaxTotal
//设置过小,无法支持大并发(ConnectionPoolTimeoutException: Timeout waiting for connection frompool),路由是对maxTotal的细分
conMgr.setDefaultMaxPerRoute(conMgr.getMaxTotal());//(目前只有一个路由,因此让他等于最大值)
//设置访问协议
conMgr.getSchemeRegistry().register(new Scheme("http",80, PlainSocketFactory. getSocketFactory()));
conMgr.getSchemeRegistry().register(new Scheme("https",443, SSLSocketFactory. getSocketFactory()));
httpClient = newDefaultHttpClient(conMgr, params);
httpClient.setHttpRequestRetryHandler(newDefaultHttpRequestRetryHandler(0, false));
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
因为我们使用http connection连接池,所以需要配置CONN_MANAGER_TIMEOUT,表示从连接池获取http connection的超时时间。
此处还通过httpClient.setHttpRequestRetryHandler(newDefaultHttpRequestRetry Handler(0, false))配置了请求重试策略(默认重试3次)。当执行请求时遇到异常时会调用retryRequest来判断是否进行重试,而retryRequest在以下情况不会进行重试:达到重试次数、服务器不可达、连接被拒绝、连接终止、请求已发送。而幂等HTTP方法的请求、requestSentRetryEnabled=true且请求还未成功发送时可以重试。
如果响应是503错误状态码时,如上重试机制是不可用的,则可以考虑使用AutoRetryHttpClient客户端,其可以配置ServiceUnavailableRetryStrategy,默认实现为DefaultServiceUnavailableRetryStrategy,可以配置重试次数maxRetries和重试间隔retryInterval。每次重试之前都会等待retryInterval毫秒时间。
假设我们服务有多个机房提供,其中一个机房服务出现问题时应该自动切到另一个机房,可以考虑使用如下方法。
public static String get(List<String> apis, Object[] args, String encoding,Header[] headers, Integer timeout) throws Exception {
Stringresponse = null;
for(String api : apis) {
String uri =UriComponentsBuilder.fromHttpUrl(api).buildAndExpand(args). toUriString();
response = HttpClientUtils.getDataFromUri(uri, encoding, headers,timeout);
//如果失败了,重试一次
if(Objects.equal(response, HTTP_ERROR)){
continue;
}
//如果域名解析失败重试
if(Objects.equal(response,HTTP_UNKNOWN_HOST_ERROR)) {
response = HTTP_ERROR; //掉用方根据这个判断是否有问题
continue;
}
if(Objects.equal(response,HTTP_SOCKET_TIMEOUT_ERROR)) {
response = HTTP_ERROR; //调用方根据这个判断是否有问题
continue;
}
return response;
}
return response;
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
参数传入不同机房的API即可,当其中一个不可用自动重试另一个机房的API。
【本文是51CTO专栏作者“张开涛”的原创文章,作者微信公众号:开涛的博客( kaitao-1234567)】