












一. 概念
关联分析用于发现隐藏在大型数据集中的有意义的联系。所发现的联系可以用关联规则(association rule)或频繁项集的形式表示。
项集:在关联分析中,包含0个或多个项的集合被称为项集(itemset)。如果一个项集包含k个项,则称它为k-项集。例如:{啤酒,尿布,牛奶,花生} 是一个4-项集。空集是指不包含任何项的项集。
关联规则(association rule):是形如 X → Y 的蕴含表达式,其中X和Y是不相交的项集,即:X∩Y=∅。关联规则的强度可以用它的支持度(support)和置信度(confidence)来度量。
支持度:一个项集或者规则在所有事物中出现的频率,确定规则可以用于给定数据集的频繁程度。σ(X):表示项集X的支持度计数
项集X的支持度:s(X)=σ(X)/N;规则X → Y的支持度:s(X → Y) = σ(X∪Y) / N
置信度:确定Y在包含X的事务中出现的频繁程度。c(X → Y) = σ(X∪Y)/σ(X)
支持度是一种重要的度量,因为支持度很低的规则可能只是偶然出现,低支持度的规则多半也是无意义的。因此,支持度通常用来删去那些无意义的规则;
置信度度量是通过规则进行推理具有可靠性。对于给定的规则X → Y,置信度越高,Y在包含X的事物中出现的可能性就越大。即Y在给定X下的条件概率P(Y|X)越大。
二. R语言中实现Apriori算法应用
R语言中的Apriori算法实现包含在arules包中,本文不涉及算法的实现,只是应用arules该包实现关联规则的挖掘。
1.数据源:利用arules包中自带的Groceries数据集,该数据集是来自一个现实世界中的超市经营一个月的购物数据,包含了9835次交易。我们按照超市一天12个小时的工作时间计算,大约每小时的交易次数为9835/30/12=27.3,表明该超市规模属于中等。
- > library(arules) #加载 arules 包
- > data(Groceries)
- > Groceries
- transactions in sparse format with
- 9835 transactions (rows) and
- 169 items (columns)
2.探索和准备数据:
(1)事务型数据每一行指定一个单一的实例,每条记录包括用逗号隔开的任意数量的产品清单,通过inspect()函数可以看到超市的交易记录,每次交易的商品名称;通过summary()函数可以查看该数据集的一些基本 信息。
- > inspect(Groceries[1:5]) #通过inspect函数查看Groceries数据集的前5次交易记录
- items
- 1 {citrus fruit,semi-finished bread,margarine,ready soups}
- 2 {tropical fruit,yogurt,coffee}
- 3 {whole milk}
- 4 {pip fruit,yogurt,cream cheese ,meat spreads}
- 5 {other vegetables,whole milk,condensed milk,long life bakery product}
- <br>> summary(Groceries)
- transactions as itemMatrix in sparse format with
- 9835 rows (elements/itemsets/transactions) and
- 169 columns (items) and a density of 0.02609146
- most frequent items:
- whole milk other vegetables rolls/buns soda yogurt (Other)
- 2513 1903 1809 1715 1372 34055
- element (itemset/transaction) length distribution:
- sizes
- 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 26 27 28 29
- 2159 1643 1299 1005 855 645 545 438 350 246 182 117 78 77 55 46 29 14 14 9 11 4 6 1 1 1 1 3
- 32
- 1
- Min. 1st Qu. Median Mean 3rd Qu. Max.
- 1.000 2.000 3.000 4.409 6.000 32.000
- includes extended item information - examples:
- labels level2 level1
- 1 frankfurter sausage meat and sausage
- 2 sausage sausage meat and sausage
- 3 liver loaf sausage meat and sausage
- > itemFrequency(Groceries[,1:3]) #itemFrequency()函数可以查看商品的交易比例<br>frankfurter sausage liver loaf <br>0.058973055 0.093950178 0.005083884
分析:
①密度值0.02609146(2.6%)指的是非零矩阵单元格的比例。
该数据集一共有9835行(交易记录),169列(所有交易的商品种类),因此,矩阵中共有9835*169=1662115个位置,我们可以得出,在30天内共有1662115*0.02609146=43367件商品被购买。进一步可以得出在每次交易中包含了43367/9835=4.409件商品被购买,在均值那一列可以看出(Mean=4.409)我们的计算是正确的;
②most frequent items:列出了事务型数据中最常购买的商品。whole milk 在9835次交易中被购买了2513次,因此,我们可以得出结论:whole milk有2513/9835=25.6%的概率出现在所有的交易中;
③element (itemset/transaction) length distribution:呈现了一组关于交易规模的统计,总共有2159次交易中包含一件商品,有1次交易中包含了32件商品.从分位数分布情况可以看出,25%的交易中包含了两件或者更少的商品,大约一半的交易中商品数量为3件;
(2)可视化商品的支持度——商品的频率图
为了直观地呈现统计数据,可以使用itemFrequenctyPlot()函数生成一个用于描绘所包含的特定商品的交易比例的柱状图。因为包含很多种商品,不可能同时展现出来,因此可以通过support或者topN参数进行排除一部分商品进行展示
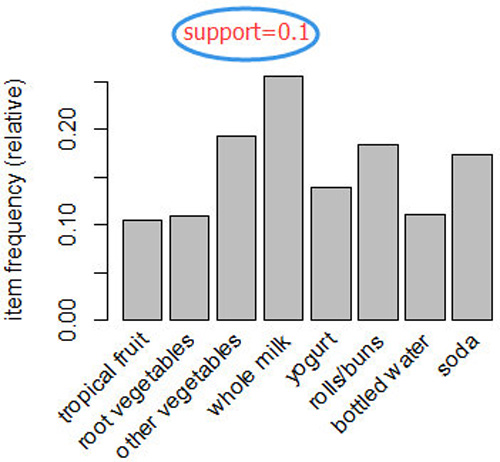
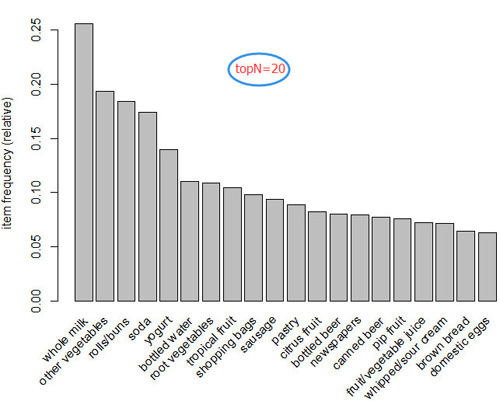
(3)可视化交易数据——绘制稀疏矩阵
通过使用image()函数可以可视化整个稀疏矩阵。
- image(Groceries[1:5]) # 生成一个5行169列的矩阵,矩阵中填充有黑色的单元表示在此次交易(行)中,该商品(列)被购买了

从上图可以看出,***行记录(交易)包含了四种商品(黑色的方块),这种可视化的图是用于数据探索的一种很有用的工具。它可能有助于识别潜在的数据问题,比如:由于列表示的是商品名称,如果列从上往下一直被填充表明这个商品在每一次交易中都被购买了;另一方面,图中的模式可能有助于揭示交易或者商品的有趣部分,特别是当数据以有趣的方式排序后,比如,如果交易按照日期进行排序,那么黑色方块图案可能会揭示人们购买商品的数量或者类型受季节性的影响。这种可视化对于超大型的交易数据集是没有意义的,因为单元太小会很难发现有趣的模式。
3.训练模型
- grocery_rules <- apriori(data=Groceries,parameter=list(support =,confidence =,minlen =))
运行apriori()函数很简单,但是找到支持度和置信度参数来产生合理数量的关联规则时,可能需要进行大量的试验与误差评估。
如果参数设置过高,那么结果可能是没有规则或者规则过于普通而不是非常有用的规则;另一方面如果阈值太低,可能会导致规则数量很多,甚至需要运行很长的时间或者在学习阶段耗尽内存。
aprior()函数默认设置 support = 0.1 和 confidence = 0.8,然而使用默认的设置,不能得到任何规则
- > apriori(Groceries)
- set of 0 rules # 因为support = 0.1,则意味着该商品必须至少出现在 0.1 * 9835 = 983.5次交易中,在前面的分析中,我们发现只有8种商品的 support >= 0.1,因此使用默认的设置没有产生任何规则也不足为奇
解决支持度设定问题的一种方法是考虑一个有趣的模式之前,事先想好需要的最小交易数量,例如:我们可以认为如果一种商品一天被购买了2次,一个月也就是60次交易记录,这或许是我们所感兴趣的,据此,可以计算所需要的支持度support=60/9835=0.006;
关于置信度:设置太低,可能会被大量不可靠的规则淹没,设置过高,可能会出现很多显而易见的规则致使我们不能发现有趣的模式;一个合适的置信度水平的选取,取决于我们的分析目标,我们可以尝试以一个保守的值开始,如果发现没有具有可行性的规则,可以降低置信度以拓宽规则的搜索范围。
在此例中,我们将从置信度0.25开始,这意味着为了将规则包含在结果中,此时规则的正确率至少为25%,这将排除最不可靠的规则
minlen = 2 表示规则中至少包含两种商品,这可以防止仅仅是由于某种商品被频繁购买而创建的无用规则,比如在上面的分析中,我们发现whole milk出现的概率(支持度)为25.6%,很可能出现如下规则:{}=>whole milk,这种规则是没有意义的。
最终,根据上面的分析我们确定如下参数设置:
- > grocery_rules <- apriori(data = Groceries,parameter = list(support = 0.006,confidence = 0.25,minlen = 2))
- > grocery_rules
- set of 463 rules
4.评估模型的性能
- > summary(grocery_rules)
- set of 463 rules
- rule length distribution (lhs + rhs):sizes # 前件+后件 的规则长度分布
- 2 3 4
- 150 297 16 #有150个规则只包含2种商品,297个规则包含3种商品,16个规则包含4种商品
- Min. 1st Qu. Median Mean 3rd Qu. Max.
- 2.000 2.000 3.000 2.711 3.000 4.000
- summary of quality measures:
- support confidence lift
- Min. :0.006101 Min. :0.2500 Min. :0.9932
- 1st Qu.:0.007117 1st Qu.:0.2971 1st Qu.:1.6229
- Median :0.008744 Median :0.3554 Median :1.9332
- Mean :0.011539 Mean :0.3786 Mean :2.0351
- 3rd Qu.:0.012303 3rd Qu.:0.4495 3rd Qu.:2.3565
- Max. :0.074835 Max. :0.6600 Max. :3.9565
- mining info:
- data ntransactions support confidence
- Groceries 9835 0.006 0.25
- <br>> inspect(grocery_rules[1:5])
- lhs rhs support confidence lift
- 1 {pot plants} => {whole milk} 0.006914082 0.4000000 1.565460
- 2 {pasta} => {whole milk} 0.006100661 0.4054054 1.586614
- 3 {herbs} => {root vegetables} 0.007015760 0.4312500 3.956477
- 4 {herbs} => {other vegetables} 0.007727504 0.4750000 2.454874
- 5 {herbs} => {whole milk} 0.007727504 0.4750000 1.858983
这里需要解释一下lift(提升度),表示用来度量一类商品相对于它的一般购买率,此时被购买的可能性有多大。通俗的讲就是:比如***条规则{pot plants} => {whole milk},lift = 1.565,表明(购买pot plants 之后再购买 whole milk商品的可能性) 是 (没有购买pot plants 但是购买了whole milk 的可能性) 的 1.565倍;
***条规则解读:如果一个顾客购买了pot plants,那么他还会购买whole milk,支持度support为0.0070,置信度confidence为0.4000,我们可以确定该规则涵盖了大约0.7%的交易,而且在购买了pot plants后,他购买whole milk的概率为40%,提升度lift值为1.565,表明他相对于一般没有购买pot plant商品的顾客购买whole milk商品的概率提升了1.565倍,我们在上面的分析中知道,有25.6%的顾客购买了whole milk,因此计算提升度为0.40/0.256=1.56,这与显示的结果是一致的,注意:标有support的列表示规则的支持度,而不是前件(lhs)或者后件(rhs)的支持度。
提升度 lift(X → Y) = P (Y| X) / P (Y) , lift(X → Y) 与 lift(Y → X) 是相同的。
如果lift值>1,说明这两类商品在一起购买比只有一类商品被购买更常见。一个大的提升度值是一个重要的指标,它表明一个规则时很重要的,并反映了商品之间的真实联系。
5.提高模型的性能
(1)对关联规则集合排序
根据购物篮分析的目标,最有用的规则或许是那些具有高支持度、信度和提升度的规则。arules包中包含一个sort()函数,通过指定参数by为"support","confidence"或者"lift"对规则列表进行重新排序。 在默认的情况下,排序是降序排列,可以指定参数decreasing=FALSE反转排序方式。
- > inspect(sort(grocery_rules,by="lift")[1:10])
- lhs rhs support confidence lift
- 3 {herbs} => {root vegetables} 0.007015760 0.4312500 3.956477
- 57 {berries} => {whipped/sour cream} 0.009049314 0.2721713 3.796886
- 450 {tropical fruit,other vegetables,whole milk} => {root vegetables} 0.007015760 0.4107143 3.768074
- 174 {beef,other vegetables} => {root vegetables} 0.007930859 0.4020619 3.688692
- 285 {tropical fruit,other vegetables} => {pip fruit} 0.009456024 0.2634561 3.482649
- 176 {beef,whole milk} => {root vegetables} 0.008032537 0.3779904 3.467851
- 284 {pip fruit,other vegetables} => {tropical fruit} 0.009456024 0.3618677 3.448613
- 282 {pip fruit,yogurt} => {tropical fruit} 0.006405694 0.3559322 3.392048
- 319 {citrus fruit,other vegetables} => {root vegetables} 0.010371124 0.3591549 3.295045
- 455 {other vegetables,whole milk,yogurt} => {tropical fruit} 0.007625826 0.3424658 3.263712
(2)提取关联规则的子集:可以通过subset()函数提取我们感兴趣的规则
- > fruit_rules <- subset(grocery_rules,items %in% "pip fruit") # items 表明与出现在规则的任何位置的项进行匹配,为了将子集限制到匹配只发生在左侧或者右侧位置上,可以使用lhs或者rhs代替
- > fruit_rules
- set of 21 rules
- > inspect(fruit_rules[1:5])
- lhs rhs support confidence lift
- 127 {pip fruit} => {tropical fruit} 0.020437214 0.2701613 2.574648
- 128 {pip fruit} => {other vegetables} 0.026131164 0.3454301 1.785237
- 129 {pip fruit} => {whole milk} 0.030096594 0.3978495 1.557043
- 281 {tropical fruit,pip fruit} => {yogurt} 0.006405694 0.3134328 2.246802
- 282 {pip fruit,yogurt} => {tropical fruit} 0.006405694 0.3559322 3.392048
以上,就是应用R语言添加包arules中实现的apriori算法进行的关联规则挖掘的应用,欢迎大家进行交流!














