一般说来,训练深度学习网络的方式主要有四种:监督、无监督、半监督和强化学习。在接下来的文章中,计算机视觉战队将逐个解释这些方法背后所蕴含的理论知识。除此之外,计算机视觉战队将分享文献中经常碰到的术语,并提供与数学相关的更多资源。
监督学习(Supervised Learning)
监督学习是使用已知正确答案的示例来训练网络的。想象一下,我们可以训练一个网络,让其从照片库中(其中包含你父母的照片)识别出你父母的照片。以下就是我们在这个假设场景中所要采取的步骤。
步骤1:数据集的创建和分类
首先,我们要浏览你的照片(数据集),确定所有有你父母的照片,并对其进行标注,从而开始此过程。然后我们将把整堆照片分成两堆。我们将使用第一堆来训练网络(训练数据),而通过第二堆来查看模型在选择我们父母照片操作上的准确程度(验证数据)。
等到数据集准备就绪后,我们就会将照片提供给模型。在数学上,我们的目标就是在深度网络中找到一个函数,这个函数的输入是一张照片,而当你的父母不在照片中时,其输出为0,否则输出为1。
此步骤通常称为 分类任务 。在这种情况下,我们进行的通常是一个结果为yes or no的训练,但事实是,监督学习也可以用于输出一组值,而不仅仅是0或1。例如,我们可以训练一个网络,用它来输出一个人偿还信用卡贷款的概率,那么在这种情况下,输出值就是0到100之间的任意值。这些任务我们称之为 回归 。
步骤2:训练
为了继续该过程,模型可通过以下规则(激活函数)对每张照片进行预测,从而决定是否点亮工作中的特定节点。这个模型每次从左到右在一个层上操作——现在我们将更复杂的网络忽略掉。当网络为网络中的每个节点计算好这一点后,我们将到达亮起(或未亮起)的最右边的节点(输出节点)。
既然我们已经知道有你父母的照片是哪些图片,那么我们就可以告诉模型它的预测是对还是错。然后我们会将这些信息反馈(feed back)给网络。
该算法使用的这种反馈,就是一个量化“真实答案与模型预测有多少偏差”的函数的结果。这个函数被称为成本函数(cost function),也称为目标函数(objective function),效用函数(utility function)或适应度函数(fitness function)。然后,该函数的结果用于修改一个称为 反向传播 (backpropagation)过程中节点之间的连接强度和偏差,因为信息从结果节点“向后”传播。
我们会为每个图片都重复一遍此操作,而在每种情况下,算法都在尽量最小化成本函数。
其实,我们有多种数学技术可以用来验证这个模型是正确还是错误的,但我们常用的是一个非常常见的方法,我们称之为 梯度下降 (gradient descent)。Algobeans上有一个 “门外汉”理论可以很好地解释它是如何工作的。迈克尔•尼尔森(Michael Nielsen) 用 数学知识完善 了这个方法 ,其中包括微积分和线性代数。
http://neuralnetworksanddeeplearning.com/chap2.html
步骤3:验证
一旦我们处理了第一个堆栈中的所有照片,我们就应该准备去测试该模型。我们应充分利用好第二堆照片,并使用它们来验证训练有素的模型是否可以准确地挑选出含有你父母在内的照片。
我们通常会通过调整和模型相关的各种事物(超参数)来重复步骤2和3,诸如里面有多少个节点,有多少层,哪些数学函数用于决定节点是否亮起,如何在反向传播阶段积极有效地训练权值,等等。而你可以通过浏览Quora上的相关介绍来理解这一点,它会给你一个很好的解释。
步骤4:使用
最后,一旦你有了一个准确的模型,你就可以将该模型部署到你的应用程序中。你可以将模型定义为API调用,例如ParentsInPicture(photo),并且你可以从软件中调用该方法,从而导致模型进行推理并给出相应的结果。
稍后我们将详细介绍一下这个确切的过程,编写一个识别名片的iPhone应用程序。
得到一个标注好的数据集可能会很难(也就是很昂贵),所以你需要确保预测的价值能够证明获得标记数据的成本是值得的,并且我们首先要对模型进行训练。例如,获得可能患有癌症的人的标签X射线是非常昂贵的,但是获得产生少量假阳性和少量假阴性的准确模型的值,这种可能性显然是非常高的。
无监督学习(Unsupervised Learning)
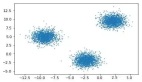
无监督学习适用于你具有数据集但无标签的情况。无监督学习采用输入集,并尝试查找数据中的模式。比如,将其组织成群(聚类)或查找异常值(异常检测)。例如:
•想像一下,如果你是一个T恤制造商,拥有一堆人的身体测量值。那么你可能就会想要有一个聚类算法,以便将这些测量组合成一组集群,从而决定你生产的XS,S,M,L和XL号衬衫该有多大。
你将在文献中阅读到的一些无监督的学习技术包括:
•自编码(Autoencoding)
http://ufldl.stanford.edu/tutorial/unsupervised/Autoencoders/
•主成分分析(Principal components analysis)
https://www.quora.com/What-is-an-intuitive-explanation-for-PCA
•随机森林(Random forests)
https://en.wikipedia.org/wiki/Random_forest
•K均值聚类(K-means clustering)
https://www.youtube.com/watch?v=RD0nNK51Fp8
无监督学习中最有前景的最新发展之一是Ian Goodfellow(当时在Yoshua Bengio的实验室工作时提出)的一个想法,称为“ 生成对抗网络 (generative adversarial networks)”,其中我们将两个神经网络相互联系:一个网络,我们称之为生成器,负责生成旨在尝试欺骗另一个网络的数据,而这个网络,我们称为鉴别器。这种方法实现了一些令人惊奇的结果,例如可以从文本字符串或手绘草图生成如照片版逼真图片的AI技术。
半监督学习(Semi-supervised Learning)
半监督学习在训练阶段结合了大量未标记的数据和少量标签数据。与使用所有标签数据的模型相比,使用训练集的训练模型在训练时可以更为准确,而且训练成本更低。
为什么使用未标记数据有时可以帮助模型更准确,关于这一点的体会就是:即使你不知道答案,但你也可以通过学习来知晓,有关可能的值是多少以及特定值出现的频率。
数学爱好者的福利:如果你对半监督学习很感兴趣的话,可以来阅读这个朱小津教授的 幻灯片教程 和2008年回顾的 文献随笔文章 。 (我们会把这两个共享在平台的共享文件专栏)
强化学习(Reinforcement Learning)
强化学习是针对你再次没有标注数据集的情况而言的,但你还是有办法来区分是否越来越接近目标(回报函数(reward function))。经典的儿童游戏——“hotter or colder”。 ( Huckle Buckle Beanstalk 的一个变体 )是这个概念的一个很好的例证。你的任务是找到一个隐藏的目标物件,然后你的朋友会喊出你是否越来越hotter(更接近)或colder(远离)目标物件。“Hotter/colder”就是回报函数,而算法的目标就是最大化回报函数。你可以把回报函数当做是一种延迟和稀疏的标签数据形式:而不是在每个数据点中获得特定的“right/wrong”答案,你会得到一个延迟的反应,而它只会提示你是否在朝着目标方向前进。
•DeepMind在Nature上发表了一篇文章,描述了一个将强化学习与深度学习结合起来的系统,该系统学会该如何去玩一套Atari视频游戏,一些取得了巨大成功(如Breakout),而另一些就没那么幸运了(如Montezuma’s Revenge(蒙特祖玛的复仇))。
•Nervana团队(现在在英特尔) 发表了一个很好的 解惑性博客文章 , 对这些技术进行了详细介绍,大家有兴趣可以阅读一番。
https://www.nervanasys.com/demystifying-deep-reinforcement-learning/
•Russell Kaplan,Christopher Sauer和Alexander Sosa举办的一个非常有创意的斯坦福学生项目说明了强化学习的挑战之一,并提出了一个聪明的解决方案。正如你在DeepMind论文中看到的那样,算法未能学习如何去玩Montezuma’s Revenge。其原因是什么呢?正如斯坦福大学生所描述的那样,“在稀缺回报函数的环境中,强化学习agent仍然在努力学习”。当你没有得到足够的“hotter”或者“colder”的提示时,你是很难找到隐藏的“钥匙”的。斯坦福大学的学生基础性地教导系统去了解和回应自然语言提示,例如“climb down the ladder”或“get the key”,从而使该系统成为OpenAI gym中的最高评分算法。 可以点击 算法视频 观看算法演示。
(http://mp.weixinbridge.com/mp/wapredirect?url=https%3A%2F%2Fdrive.google.com%2Ffile%2Fd%2F0B2ZTvWzKa5PHSkJvQVlsb0FLYzQ%2Fview&action=appmsg_redirect&uin=Nzk3MTk3MzIw&biz=MzA5MzQwMDk4Mg==&mid=2651042109&idx=1&type=1&scene=0)
•观看这个关于强化学习的算法,好好学习,然后像一个大boss一样去玩超级马里奥吧。
理查德•萨顿和安德鲁•巴托写了关于强化学习的书。你也可以点击查看第二版草稿。 http://incompleteideas.net/sutton/book/the-book-1st.html