你开发了一个 R/Python/Java 模型。它运行得很好。然后呢?
首先你的 CEO 要听闻机器学习,并且知道数据是新的石油。数据仓库团队中有个人刚提交了他 1PB Teradata 系统的预算,而 CIO 听说 FB 正在用 Hadoop 驱动商用存储服务,还超级便宜。这掀起了一场***的风暴,你被指派去组建一个数据优先(data-first)的创新团队。于是你聘请了一个数据科学家团队,突然间所有人都很兴奋,都想从你那里得到一点数字魔法去谷歌化(Googlify)他们的生意。但你的数据科学家们并没有基础设施可用,只能把时间都花在构建执行程序的项目表上,所以投资回报率并不看好,这下大家又都来怪你没有对他们的商业盈亏(P&L)投入足够的核心技术了。- Vish Nandlall
在 PB 级尺度上分享、复用和运行模型并不属于数据科学家工作流的一部分。在企业环境中,这种低效率更是显眼,因为数据科学家们的每一个工作步骤都需要和 IT 部门协作,导致连续部署流程的混乱(如果不是无法进行的话),可重用性也很低,并且这个痛点还会随着公司不同角落开始「谷歌化(Googlify)他们的业务」而滚雪球式地放大。
为了满足这种需求,数据科学和机器学习平台(Data Science & Machine Learning Platform)应运而生了。作为一个基础层,在它之上是三个内部利益相关体的合作:产品数据科学家、中心数据科学家和 IT 基础设施。

图 1:一个数据科学平台服务于三个利益相关体:产品、中心和基础设施
对于那些有着对机器学习不断增长的依赖性的复杂大型企业,图 1这个系统是非常有必要的。
在这篇博文中,我们将讨论以下几个问题:
- 谁需要一个数据科学和机器学习平台(Data Science & Machine Learning Platform,DS & ML)?
- 数据科学和机器学习平台(Data Science & Machine Learning Platform)是什么?
- 如何区别不同的平台?
- 平台的实例
一、你需要一个数据科学平台(Data Science Platform)吗?
它并不适用于所有人。对于只有一两个用例的小团队,***还是围绕共享和拓展来即兴创作自己的解决方案(或者使用私人托管方案)。但如果你是一个有很多内部客户的中心化团队,你很有可能面临着下面几种症状的困扰:
症状#1 你在分裂代码库
你的数据科学家构建出一个模型(比方说是基于 R 和 Python 的),想把它嵌入产品,用在一个网络或移动应用里。而你的后端功能是,本来用 Java 或 .NET 构建了基础架构,现在却只能用他们所选择的技术栈从头开始重写这个架构。结果你就有两个代码库要调适和同步。随着构建模型数量的增加,这种低效率会加倍放大。
症状#2 你正在重新造轮子
不论是小到一个预处理的函数还是大到一个成熟的训练模型。你的团队产出的东西越多,在现有成员和以前的成员间就越有可能出现系统性的成果复制,尤其是项目。
症状#3 你很难雇佣到***人才
你公司的每个角落都会产生要脱颖而出的数据科学或机器学习想法,但你只有少数几个真正出色的专家,他们一次也只能接受一项挑战。你本应雇佣更多的人,但数据科学家和机器学习天才是非常稀有的,而他们中的明***人物的薪水堪比一个***的美国国家橄榄球联盟(NFL)四分卫。
症状#4 你的云账单正在不断堆积(太多 P2 了!)
你在一个网络服务器后端部署了一个模型。在深度学习(deep learning)世界中你很可能想要一个配置好现成 GPU 的机器,比如说 AWS EC2(或着 Azure N-Series VM)上的 P2 实例。为每个产品化的深度学习模型来运行这些机器很容易就花费高昂,尤其对于棘手的工作任务或难以预测的模式。
二、数据科学和机器学习平台(Data Science & Machine Learning Platform)是什么?
它与所有事都相关,除了训练。一个数据科学和机器学习平台(Data Science & Machine Learning Platform)关注的是过了训练阶段后的模型的生命。这包括了:模型注册、展示它们如何从一个版本升级到两一个版本的传承、将它们中心化让其他用户能找到、并让它们转化为独立的人造产物,能嵌入到任何数据流程中。

1. 库 vs. 注册表
像是机器学习算法库(scikit-learn)和 Spark MLlib 这样的东西储存了一系列独特的算法。这是一个库。而数据科学和机器学习平台则是一个注册表。它包括了一个算法的多种执行方法,有不同的来源,而且每个算法都有自己的版本(或族系),这些版本的可发现性和可获取性是同等的。一个注册表用户能很容易找到并对比一个算法的不同执行方法的输出。
2. 训练 vs. 推理
数据科学家会用合适的工具来解决对应的问题。有时这些工具就是一种机器学习算法库(scikit-learn)和 Keras 的结合,或者 Caffe 和 Tensorflow 的结合体,又或者是一个用 R 语言写的 H2O 脚本。一个平台不会对这门技艺的工具发出指令,但能够注册并运营这些模型,这个过程独立于模型训练和实现的方式。
3. 人工 vs. 自动部署
把一个模型部署到生产中的方式有很多,最终结果都会是一个 REST API。不同的部署途径会引发很多风险,包括前后不一致的 API 接口设计、不一致的认证和登录,以及逐渐枯竭的开发资源。一个平台应该能够用最少的步骤自动完成这个工作,通过一致的 API 和授权来提供模型,并降低开发运营的执行压力。
三、如何区别不同的数据科学和机器学习平台?
从表面来看,所有的数据科学平台都差不多,但魔鬼隐藏在细节里。下面是一些可比较的数据点:
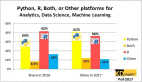
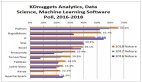
1. 支持的语言
R 语言和 Python 对绝大部分数据科学和机器学习项目都是标配。Java 是接近的第二选择,因为有着像 deeplearning4j 和 H2O 的 POJO 模型提取器这样的库。而 C++ 在科学计算或 HPC 的环境下尤其适用。其他执行时间则是可有可无的,这取决于你的用例和你的非数据科学同事所用的主要技术堆栈,比如 NodeJS/Ruby/.NET 这些。
2. CPU vs. GPU(深度学习)
随着这一领域的成熟和模型规模的增长,深度学习在数据科学和机器学习中的重要性会日益凸显。TensorFlow 虽然很受欢迎,但它并不能总是做到反向兼容,Caffe 则需要特定的编译器标识,cuDNN 只会给你的 GPU 簇增加一层管理的复杂度。在没有强制要求的情况下,完全容器化(containerizing)且产品化的异构模型(在代码、节点权重、框架和底层驱动方面),和在 GPU 架构上运行它们对一个平台来说是非常不同的。
3. 单一 vs. 多重的版本控制
版本化是指能够把模型的族系演变列出来并获取每个版本独立访问权限的能力。当模型被版本化以后,数据科学家就能测试模型随时间的变化规律。一个单一版本的架构只会显示出模型(目前稳定的那个版本)的单个 REST API 端点,而只有创作者能通过他们的控制面板在不同的模型间「切换」。一个多版本的架构除了显示「稳定」版本的一个 REST API 端点之外,还能显示以往每个版本的,使得它们都能同时可被获取,这能消除反向兼容困难,还能让后端工程师进行局部发布展示或实时 A/B 测试。
4. 垂直 vs. 水平扩展
仅仅让模型作为一个可获取的 REST API 是不够的。垂直拓展就是在一个更大型的机器上部署你的模型。水平扩展就是在多个机器上部署你的模型。而 Algorithmia Enterprise 所执行的无服务器扩展,这是应需求进行的垂直拓展,这里的需求是指把模型封装进一个专用容器中,把容器沿计算集群即时部署,并且在执行完成后将其消除以释放资源。无服务器计算带来了拓展和经济性方面的好处。
5. 单一 vs. 多个租户
当你在共享硬件资源时,处理敏感或保密性的模型是很有挑战的。单一租户的平台会在同样的资源(机器实例、虚拟内存等)上运行所有的产品模型。多租户平台把模型作为虚拟隔离的系统(给每个模型不同的容器或虚拟机)来部署,可能会提供额外的安全措施(比如防火墙规则和审计跟踪)。
6. 固定的 vs. 可交替的数据源
数据科学家可能需要在来自 S3 的模型上运行离线数据,而一个后端工程师则同时通过 HDFS 在同一个模型上运行产品数据。一个固定的数据源平台需要模型的作者安装两种数据连接器:HDFS 和 S3。而一个可交替的数据源则只需要作者安装一个通用的数据连接器,它可以作为多种数据源的适配器,同时也是一种让不会过时的模型与以后出现的任何数据源都能兼容的方式。
四、数据科学和机器学习平台的实例
这绝不是一个详尽的清单。
- Algorithmia Enterprise:http://algorithmia.com/enterprise
- Domino Data Lab:http://dominodatalab.com/
- yHat:https://www.yhat.com/
- Dataiku:https://www.dataiku.com/
- Cloudera Workbench:https://www.cloudera.com/products/data-science-and-engineering/data-science-workbench.html
- Alteryx:http://www.alteryx.com/
- RapidMiner:https://rapidminer.com/
本文作者为 Algorithmia 的 Ahmad AlNaimi。
【本文是51CTO专栏机构“机器之心”的原创译文,微信公众号“机器之心( id: almosthuman2014)”】