最近,Jeff Leek 在 Simply Stats 上发表了一篇题为「如果你的数据量不够大就不要使用深度学习」(Don't use deep learning your data isn't that big)的文章(链接见文末),认为只有获得了谷歌、Facebook 这样规模的数据才有资格做深度学习。对于这点 Andrew L. Beam(本文作者)并不反对,他认为这使我们清楚地意识到深度学习并不是一种***的灵药;但是,虽然 Beam 同意其核心观点,但是其还有很多不明确或不清晰的地方,并且 Beam 认为只要小心地训练模型,就能在小数据设置中使用深度学习。机器之心对该文进行了编译,原文链接请见文末。
Jeff Leek 采用两种方法基于 MNIST 数据集对手写字体进行分类。他对比了五层神经网络(激活函数使用的是 hyperbolic tangent)的系统和 Leekasso,Leekasso 仅仅使用了带最小边际 p-value 的 10 块像素。他惊讶地表明,在使用少量样本时,Leekasso 要比神经网络性能更加出色。
的系统和 Leekasso")
难道如果你的样本量小于 100,就因为模型会过拟合并且会得出较差的性能而不能使用深度学习?可能情况就是如此,深度学习模型十分复杂,并且有许多训练的技巧,我总感觉缺乏模型收敛性/复杂度训练也许才是性能较差的原因,而不是过拟合。
深度学习 VS. Leekasso Redux
首先***件事就是建立一个使用该数据集的深度学习模型,也就是现代版的多层感知机(MLP)和卷积神经网络(CNN)。如果 Leek 的文章是正确的话,那么当只有少量样本时,这些模型应该会产生严重的过拟合。
我们构建了一个激活函数为 RELU 的简单 MLP 和一个像 VGG 那样的卷积模型,然后我们再比较它们和 Leekasso 性能的差异。
所有的代码都可下载:https://github.com/beamandrew/deep_learning_works/blob/master/mnist.py
多层感知机模型是非常标准的:

CNN 模型也和以前的十分相似:

作为参考,MLP 大约有 12 万个参数,而 CNN 大约有 20 万个参数。根据原文的假设,当我们有这么多的参数和少量样本时,模型好像真的会出错。
我们尽可能地靠近原始分析,我们使用了 5 层交叉验证(5-fold cross validation),但使用了标准 MNIST 测试集进行评估(大约有 2000 张测试样本)。我们将测试集分为两部分,上半部分用于评估训练过程的收敛,而下半部分用于测量样本预测的准确度。我们甚至没有调整这些模型,对于大多数超参数,仅仅只是使用合理的默认值。
我们尽可能地重新构建了原文中 Leekasso 和 MLP 的 Python 版本。代码可以在此处下载:
https://github.com/beamandrew/deep_learning_works/blob/master/mnist.py
以下是每个模型的样本精度:

这两个模型的精度和原来的分析有很大的不同,原始分析中对小样本使用 MLP 仍然有很差的效果,但我们的神经网络在各种样本大小的情况下都可以达到非常***的精度。
为什么会这样?
众所周知,深度学习模型的训练往往对细节要求极高,而知道如何「调参」是一件非常重要的技能。许多超参数的调整是非常具体的问题(特别是关于 SGD 的超参数),而错误地调参会导致整个模型的性能大幅度下降。如果你在构建深度学习模型,那么就一定要记住:模型的细节是十分重要的,你需要当心任何看起来像深度学习那样的黑箱模型。
下面是我对原文模型出现问题的猜测:
- 激活函数是十分重要的,而 tanh 神经网络又难以训练。这也就是为什么激活函数已经大量转而使用类似「RELU」这样的函数。
- 确保随机梯度下降是收敛的。在原始比较中,模型只训练了 20 个 epoch,这可能是不够的。因为当 n=10 个样本时,20 个 epochs 仅仅只有 20∗10=200 次的梯度迭代更新。而遍历全部的 MNIST 数据集大概相当于 6 万次梯度更新,并且更常见的是遍历数百到数千次(大约百万次梯度更新)。如果我们仅仅执行 200 次梯度更新,那么我们需要比较大的学习率,否则模型就不会收敛。h2o.deeplearning() 的默认学习率是 0.005,这对于少量的更新次数来说太小了。而我们使用的模型需要训练 200 个 epoch,并且在前 50 次 epoch 中,我们能看到样本精度有很大的一个提高。因此我猜测模型不收敛可以解释两者样本精度的巨大差别。
- 经常检查超参数的默认值。Keras 之所以这么优秀,是因为其默认参数值通常反映了当前的***训练,但同时我们也需要确保选择的参数符合我们的问题。
- 不同的框架可能得出很不一样的结果。我尝试使用原 R 代码去观察能不能得到相似的结果。然而,我并不能使用 h2o.deeplearning() 函数得出一个优异的结果。我猜测可能是和其使用的优化过程有关,其好像使用的是弹性均值 SGD 以计算多个结点而加速训练。我不知道当你仅有少量样本数据时会不会出现故障,但我认为可能性是很大的。
幸好,RStudio 那些人太好了,他们刚刚发布了 Keras 的 R 接口:https://rstudio.github.io/keras/,这样我就可以完全用 R 语言重建我的 Python 代码了。我们之前使用 MLP 用 R 实现了就是这样:
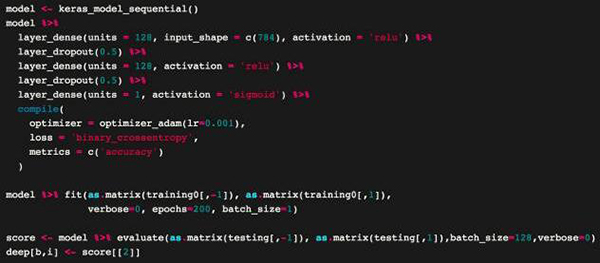
我将这个放进了 Jeff 的 R 代码中,并重新生成了原来的图表。我对 Leekasso 进行了一点修改。原来的代码使用了 lm()(即线性回归),我觉得很奇怪,所以我切换成了 glm()(即 logistic 回归)。新的图表如下所示:

深度学习真是厉害了!一个类似的现象可能能够解释 Leekasso 的 Python 和 R 版本之间的不同。Python 版本的 logistic 回归使用了 liblinear 作为其解算器,我认为这比 R 默认的解算器更加可靠一点。这可能会有影响,因为 Leekasso 选择的变量是高度共线性的(collinear)。
这个问题太简单了,以致于不能说明什么有意义的东西。我重新运行了 Leekasso,但仅使用了***的预测器,其结果几乎完全等同于全 Leekasso。实际上,我确定我可以做出一个不使用数据的且具有高准确度的分类器。只需要取其中心像素,如果是黑色,则预测 1,否则就预测 0,正如 David Robinson 指出的那样:
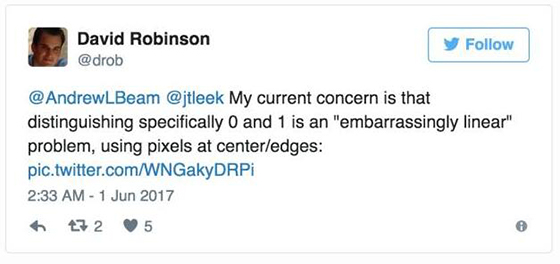
David 还指出,大多数数字对(pairs of numbers)都可以由单个像素进行分类。所以,这个问题很可能不能给我们带来任何关于「真实」小数据场景的见解,我们应当对其结论保持适当的怀疑。
关于深度学习为什么有效的误解
最终,我想要重新回到 Jeff 在文中所提出的观点,尤其是这个声明:
| 问题在于:实际上仅有少数几个企业有足够数据去做深度学习,[…] 但是我经常思考的是,在更简单的模型上使用深度学习的主要优势是如果你有大量数据就可以拟合大量的参数。 |
这篇文章,尤其是***一部分,在我看来并不完整。很多人似乎把深度学习看成一个巨大的黑箱,有大量可以学习任何函数的参数,只要你有足够的数据。神经网络当然是极其灵活的,这种灵活性正是其成功原因的一部分,但不是全部,不是吗?
毕竟,这种超级灵活的模型在机器学习和统计学中有着 70 多年的发展历史。我并不认为神经网络是先验(priori)的,我也不认为比同等复杂度的其他算法更灵活。
下面是我对其成功所作的原因总结:
- 在偏差/方差折衷中一切都是一个练习。更明白地讲,我认为 Jeff 真正在做的辩驳是关于模型复杂度和偏差/方差折衷。如果你没有很多数据,很可能训练一个简单模型(高偏差/低方差)要比复杂模型(低偏差/高方差)效果更好。客观来讲,在大多数情况下这是一个好建议,然而...
- 神经网络有很多技术来防范过拟合。神经网络有很多参数,按照 Jeff 的观点如果我们没有足够的数据去可靠地评估这些参数值,将会导致高方差。我们清楚地意识到了这个问题,并且开发了很多降低方差的技术。比如 dropout 结合随机梯度下降导致了一个像 bagging 一样糟糕的处理,但是这是发生在网络参数上,而不是输入变量。方差降低技术(比如 dropout)以其他模型难以复制的方式被加进了训练程序。这使得你可以真正训练大模型,即使没有太多数据。
- 深度学习允许你轻易地把问题的具体约束直接整合进模型以降低方差。这是我想说明的最重要的一点,也是我们以前经常忽视的一点。由于其模块化,神经网络使你可以真正整合,极大降低模型方差的强约束(先验)。***的一个实例是卷积神经网络。在 CNN 中,我们实际上把图像的属性编码进模型本身。例如,当我们指定一个大小为 3x3 的过滤器时,实际上是在直接告诉网络本地连接的像素的小集群将包含有用的信息。此外,我们还可以把图像的平移和旋转不变性直接编码进模型。所有这些都将模型偏差至图像属性,以极大地降低方差,提升预测性能。
- 你并不需要拥有谷歌量级的数据。以上所述意味着即使人均 100 到 1000 个样本也能从深度学习中受益。通过所有这些技术,我们可以改善方差问题,而且依然可以从其灵活性中受益。你甚至可以通过迁移学习来创建其他工作。
总结一下,我认为上述原因很好地解释了为什么深度学习在实践中奏效,打破了深度学习需要大量参数和数据的假设。***,本文并不是想说 Jeff 的观点错了,而是旨在提供一个不同的新视角,为读者带来启发。
原文:http://beamandrew.github.io/deeplearning/2017/06/04/deep_learning_works.html
【本文是51CTO专栏机构“机器之心”的原创译文,微信公众号“机器之心( id: almosthuman2014)”】