1. 软件项目的套路
如果你平时的工作是做各种项目(而不是产品),而且你工作的时间足够长,那么自然见识过很多不同类型的项目。在切换过多次上下文之后,作为程序员的你,自然而然的会感到一定程度的重复,稍加抽象,你会发现所有的业务系统都几乎做着同样的事情:
- 从某种渠道与用户交互,从而接受输入(Native App,Mobile Site,Web Site,桌面应用等等)
- 将用户输入的数据按照一定规则进行转换,然后保存起来(通常是关系型数据库)
- 将业务数据以某种形式展现(列表,卡片,地图上的Marker,时间线等)
稍加简化,你会发现大部分业务系统其实就是对某种形式的资源进行管理。所谓管理,也无非是增删查改(CRUD)操作。比如知乎是对“问题”这种资源的管理,LinkedIn是对“Profile”的管理,Jenkins对构建任务的管理等等,粗略的看起来都是这一个套路(当然,每个系统管理的资源类型可能不止一种,比如知乎还有时间线,Live,动态等等资源的管理)。
这些情况甚至会给开发者一种错觉:世界上所有的信息管理系统都是一样的,不同的仅仅是技术栈和操作的业务对象而已。如果写好一个模板,几乎都可以将开发过程自动化起来。事实上,有一些工具已经支持通过配置文件(比如yaml或者json/XML)的描述来生成对应的代码的功能。
如果真是这样的话,软件开发就简单多了,只需要知道客户业务的资源,然后写写配置文件,***执行了一个命令来生成应用程序就好了。不过如果你和我一样生活在现实世界的话,还是趁早放弃这种完全自动化的想法吧。
2. 复杂的业务
现实世界的软件开发是复杂的,复杂性并不体现在具体的技术栈上。如Java,Spring,Docker,MySQL等等具体的技术是可以学习很快就熟练掌握的。软件真正复杂的部分,往往是业务本身,比如航空公司的超售策略,在超售之后Remove乘客的策略等;比如亚马逊的打折策略,物流策略等。
用软件模型如何优雅而合理的反应复杂的业务(以便在未来业务发生变化时可以更快速,更低错误的作出响应)本身也是复杂的。要将复杂的业务规则转换成软件模型是软件活动中非常重要的一环,也是信息传递往往会失真的一环。业务人员说的A可能被软件开发者理解成Z,反过来也一样。
举个例子,我给租来的房子买了1年的联通宽带。可是过了6个月后,房东想要卖房子把我赶了出来,在搬家之后,我需要通知联通公司帮我做移机服务。
如果纯粹从开发者的角度出发,写出来的代码可能看起来是这样的:
- public class Customer {
- private String address;
- public void setAddress(String address) {
- this.address = address;
- }
- public String getAddress() {
- return this.address;
- }
- }
中规中矩,一个简单的值对象。作为对比,通过与领域专家的交流之后,写出来的代码会是这样:
- public class Customer {
- private String address;
- public void movingHome(String address) {
- this.address = address;
- }
- }
通过引入业务场景中的概念movingHome,代码就变得有了业务含义,除了可读性变强之外,这样的代码也便于和领域专家进行交流和讨论。Eric在领域驱动设计(Domain Drvien Design)中将统一语言视为实施DDD的先决条件。
3. 层次架构(三明治)
All problems in computer science can be solved by another level of indirection, except of course for the problem of too many indirections.
-- David Wheeler
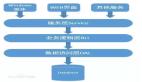
上文提到,业务系统对外的呈现是对某种资源的管理,而且,现实世界里的业务系统往往要对多种资源进行管理。这些资源还会互相引用,互相交织。比如一个看板系统中的泳道、价值流、卡片等;LinkedIn中的公司,学校,个人,研究机构,项目,项目成员等,它们往往会有嵌套、依赖等关系。
为了管理庞大的资源种类和繁复的引用关系,人们自然而然的将做同样事情的代码放在了统一的地方。将不同职责的事物分类是人类在处理复杂问题时自然使用的一种方式,将复杂的、庞大的问题分解、降级成可以解决的问题,然后分而治之。
")
(图片来自:http://t.cn/RSNienv)
比如在实践中 ,展现部分的代码只负责将数据渲染出来,应用部分的代码只负责序列化/反序列化、组织并协调对业务服务的调用,数据访问层则负责屏蔽底层关系型数据库的差异,为上层提供数据。
这就是层级架构的由来:上层的代码直接依赖于临近的下层,一般不对间接的下层产生依赖,层次之间通过精心设计的API来通信(依赖通常也是单向的)。
以现代的眼光来看,层次架构的出现似乎理所应当、自然而然,其实它也是经过了很多次的演进而来的。以JavaEE世界为例,早期人们会把应用程序中负责请求处理、文件IO、业务逻辑、结果生成都放在servlet中;后来发明了可以被Web容器翻译成servlet的JSP,这样数据和展现可以得到比较好的分离(当然中间还有一些迂回,比如JSTL、taglib的滥用又导致很多逻辑被泄露到了展现层);数据存储则从JDBC演化到了各种ORM框架,***再到JPA的大一统。
如果现在把一个Spring-Boot写的RESTful后端,和SSH(Spring-Struts-Hibernate)流行的年代的后端来做对比,除了代码量上会少很多以外,层次结构上基本上并无太大区别。不过当年在SSH中复杂的配置,比如大量的XML变成了代码中的注解,容器被内置到应用中,一些配置演变成了惯例,大致来看,应用的层次基本还是保留了:
- 展现层
- 应用层
- 数据访问层
在有些场景下,应用层内还可能划分出一个服务层。

4. 前后端分离
随着智能设备的大爆发,移动端变成了展现层的主力,如何让应用程序很容易的适配新的展现层变成了新的挑战。这个新的挑战驱动出了前后端分离方式,即后端只提供数据(JSON或者XML),前端应用来展现这些数据。甚至很多时候,前端会成为一个独立的应用程序,有自己的MVC/MVP,只需要有一个HTTP后端就可以独立工作。

前后端分离可以很好的解决多端消费者的问题,后端应用现在不区分前端的消费者到底是谁,它既可以是通过4G网络连接的iOS上的Native App,也可以是iMac桌面上的Chrome浏览器,还可以是Android上的猎豹浏览器。甚至它还可以是另一个后台的应用程序:总之,只要可以消费HTTP协议的文本就可以了!
这不得不说是一个非常大的进步,一旦后端应用基本稳定,频繁改变的用户界面不会影响后端的发布计划,手机用户的体验改进也与后端的API设计没有任何关系,似乎一切都变的美好起来了。
5. 业务与基础设施分离
不过,如果有一个消费者(一个业务系统),它根本不使用HTTP协议怎么办?比如使用消息队列,或者自定义的Socket协议来进行通信,应用程序如何处理这种场景? 这种情况就好比你看到了这样一个函数:
- httpService(request, response);
作为程序员,自然会做一次抽象,将协议作为参数传入:
- service(request, response, protocol);
更进一步,protocol可以在service之外构造,并注入到应用中,这样代码就可以适配很多种协议(比如消息队列,或者其他自定义的Socket协议)。 比如:
- public interface Protocol {
- void transform(Request request, Response response);
- }
- public class HTTP implements Protocol {
- }
- public class MyProtocol implements Protocol {
- }
- public class Service {
- public Service(Protocol protocol) {
- this.protocol = protocol;
- }
- public void service(request, response) {
- //business logic here
- protocol.transfrom(request, response);
- }
- }
类似的,对于数据的持久化,也可以使用同样的原则。对于代码中诸如这样的代码:
- persisteToDatabase(data);
在修改之后会变成:
- persistenceTo(data, repository);
应用依赖倒置原则,我们会写出这样的形式:
- public class DomainService {
- public BusinessLogic(Repository repository) {
- this.repository = repository
- }
- public void perform() {
- //perform business logic
- repository.save(record);
- }
- }
对于Repository可能会有多种实现。根据不同的需求,我们可以自由的在各种实现中切换:
- public class InMemoryRepository implements Repository {}
- public class RDBMSRepository implements Repository {}
这样业务逻辑和外围的传输协议、持久化机制、安全、审计等等都隔离开来了,应用程序不再依赖具体的传输细节,持久化细节,这些具体的实现细节反过来会依赖于应用程序。
通过将传统内置在层次架构中的数据库访问层、通信机制等部分的剥离,应用程序可以简单的分为内部和外部两大部分。内部是业务的核心,也就是DDD(Domain Driven Design)中强调的领域模型(其中包含领域服务,对业务概念的建立的模型等);外部则是类似RESTful API,SOAP,AMQP,或者数据库,内存,文件系统,以及自动化测试。
这种架构风格被称为六边形架构,也叫端口适配器架构。
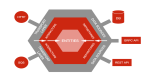
6. 六边形架构(端口适配器)
六边形架构最早由Alistair Cockburn提出。在DDD社区得到了发展和推广,然后IDDD(《实现领域驱动设计》)一书中,作者进行了比较深入的讨论。
")
(图片来自:slideshare.net )
简而言之,在六边形架构风格中,应用程序的内部(中间的橙色六边形)包含业务规则,基于业务规则的计算,领域对象,领域事件等。这部分是企业应用的核心:比如在线商店里什么样的商品可以打折,对那种类型的用户进行80%的折扣;取消一个正在执行的流水线会需要发生什么动作,删除一个已经被别的Job依赖的Stage又应该如何处理。
而外部的,也是我们平时最熟悉的诸如REST,SOAP,NoSQL,SQL,Message Queue等,都通过一个端口接入,然后在内外之间有一个适配器组成的层,它负责将不同端口来的数据进行转换,翻译成领域内部可以识别的概念(领域对象,领域事件等)。
内部不关心数据从何而来,不关心数据如何存储,不关心输出时JSON还是XML,事实上它对调用者一无所知,它可以处理的数据已经是经过适配器转换过的领域对象了。
六边形架构的优点:
- 业务领域的边界更加清晰
- 更好的可扩展性
- 对测试的友好支持
- 更容易实施DDD
要新添加一种数据库的支持,或者需要将RESTful的应用扩展为支持SOAP,我们只需要定义一组端口-适配器即可,对于业务逻辑部分无需触碰,而且对既有的端口-适配器也不会有影响。
由于业务之外的一切都属于外围,所以应用程序是真的跑在了Web容器中还是一个Java进程中其实是无所谓的,这时候自动化测试会容易很多,因为测试的重点:业务逻辑和复杂的计算都是简单对象,也无需容器,数据库之类的环境问题,单元级别的测试就可以覆盖大部分的业务场景。
这种架构模式甚至可能影响到团队的组成,对业务有深入理解的业务专家和技术专家一起来完成核心业务领域的建模及编码,而外围的则可以交给新人或者干脆外包出去。
在很多情况下,从开发者的角度进行的假设都会在事后被证明是错误的。人们在预测软件未来演进方向时往往会做很多错误的决定。比如对关系型数据库的选用,对前端框架的选用,对中间件的选用等等,六边形架构可以很好的帮助我们避免这一点。
7. 小结
软件的核心复杂度在于业务本身,我们需要对业务本身非常熟悉才可能正确的为业务建模。通过统一的语言我们可以编写出表意而且易于和业务人员交流的模型。
另一方面模型应该尽可能的和基础设施(比如JSON/XML的,数据库存储,通信机制等)分离开。这样一来可以很容易用mock的方式来解耦模型和基础设施,从而更容易测试和修改,二来我们的领域模型也更独立,更精简,在适应新的需求时修改也会更容易。
【本文是51CTO专栏作者“ThoughtWorks”的原创稿件,微信公众号:思特沃克,转载请联系原作者】