一、前言
在《如何用几行代码打造应用程序热补丁?(一)》中,我们介绍了应用程序热补丁技术的基本原理,同时实现了一个简单的热补丁。但是无法对本地函数打热补丁,同时手动编写热补丁比较麻烦、可能非常复杂容易出错。
为了解决这些问题,本文将会介绍一种自动生成应用程序热补丁技术,可以生成应用程序和动态链接库中任意函数的热补丁。
二、自动生成热补丁综述
自动生成热补丁是利用热补丁生成工具,对现有的源代码和补丁文件进行处理,自动输出热补丁的技术。
我们知道,热补丁的基本原理是新函数替换旧函数,也就是完整的函数的替换。补丁中可能包含一个或多个函数的修改,这些被修改的函数都会被替换掉。上一篇文章介绍过,热补丁首先把新函数放入目标进程的内存中,然后修改旧函数的入口,使之跳转到新函数。
自动生成热补丁中最主要的部分是自动生成新函数的二进制代码,也称为是替换代码。在生成替换代码时,主要由以下部分组成:
- 自动生成替换代码。
- 解析替换代码中使用的符号。
接下来会对以上部分进行详细的介绍。在介绍之前,必须假设系统环境是Linux X86/X86_64,应用程序是C语言编译链接的ELF格式可执行文件,并且拥有原始程序的源代码。
三、前后代码比较生成替换代码
1. 动机与挑战
为了生成替换代码,首先需要知道代码修复之后,哪些函数发生了改变,然后根据这些改变,生成替换代码。使用一种二进制比较的方法,通过比较原始程序的二进制和修复后程序的二进制,提取出生成替换代码所需的全部信息。
我们选择在目标文件(object file)的级别,进行前后比较。这样做的好处是显而易见的:
- 首先,任何源代码的改变都会在目标文件的二进制代码中显示出来。举个例子,头文件.h文件中函数的参数如果从int变成了long long,调用这个函数的.c文件由于隐含的类型转换,并不发生改变。如果在前后代码对比发生在源代码级别,甚至预处理之后,也不能发现前后.c文件发生了改变。
- 其次,我们不需要处理语言级别的特性,比如inline关键字、隐含类型转换、宏等等。这些语言相关的特性可能随着语言的发展会愈发复杂,并且我们也不希望热补丁局限于某种语言。C语言、C++、汇编都是我们希望可以处理的语言。
- 最后,我们只关心代码的二进制表达。在目标文件的级别,二进制代码和代码组成信息是最完整的,在此进行前后代码比较也是最合理的。
所以,生成替换代码的思路是,通过比较前后编译的目标文件,提取出差异部分,组成替换代码。
比较目标文件也面临很多挑战,主要在于如何从提取出发生改变的函数。举个例子,由于目标文件中默认所有的函数代码都会放在.text段,同时.text段中的相对地址跳转都是相对于.text段的。也就是说,如果某个函数发生了改变,就算是一行代码的改变,后面的相对地址跳转也很可能会发生改变(由于符号位置发生了改变)。
2. 解决办法
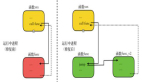
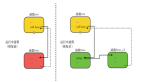
我们对目标应用程序代码和修复后代码分别编译,逐一比较两次编译产生的若干个目标文件。如图所示:

- 首先,我们编译原始源代码,保留所有中间过程中产生的目标文件。
- 然后,我们对原始源代码打上修复补丁,再次编译,构建系统(make)一般只会编译改变的源文件,保留新生成的目标文件。如果没有构建系统或者构建系统不如期工作,可以保留所有的目标文件。
- 最后,我们比较新生成的目标文件和对应的原始代码编译出来的目标文件,提取出差异部分,组成替换代码,生成热补丁。
在比较过程中,我们希望做到可以在函数级别上进行比较,这样可以只提取出发生改变的函数,并且我们也希望生成的替换代码是地址无关的,因为替换代码可能被加载到任意的内存地址。
GCC编译器提供了-ffunciton-sections和-fdata-section的编译选项,作用是把函数和变量放入目标文件中独立的段(每个函数代码都由独立的段来表示)。这样编译出的函数代码都是地址无关的、更加通用的二进制,可以提取到替换代码中被加载到内存的任意位置运行。
在对前后目标文件比较的时候,我们在ELF段的级别进行比较(也就是函数的级别,因为函数都在自己独立的段中)。因为目标文件是ELF文件,遵守通用的标准。我们可以解析目标文件的ELF Header,找到段的开头(Section Header),由此找到所有的段。这里我们建议使用一些ELF解析库,如libelf、libbfd等。
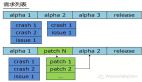
逐一比较前后目标文件中的表示代码的段,段的内容就是函数的代码,找到发生改变的函数:
- 首先,比较段的大小,如果大小不同,说明函数发生了改变。
- 接着,对段的内容进行比较,如果某个字节不同,而且字节不属于重定向的一部分,说明函数发生了改变。如果是重定向,检查重定向计算之后的指令内容是否相同,如果不同,说明函数发生了改变(引用了与之前不同的函数或者变量)。
- 最后,如果段的大小和段的内容都没有改变,说明函数没有改变。
需要注意的是,如果补丁中修改的是宏或inline函数,我们无法做到只提取宏或者inline函数的差异,因为宏和inline函数会在编译过程中被放置在其调用函数中,所有调用函数都会改变,所以提取的是所有调用的函数。
此时的替换代码还不能直接运行,因为替换代码中还可能包含对其他符号的引用,我们需要在运行替换代码之前解析这些符号。
四、替换代码中的符号解析
1. 动机与挑战
我们的替换代码中只包含改变的函数代码,这些函数中可能会引用其他没有改变的符号(函数或变量),所以我们需要根据符号引用的规则(一般为相对PC地址的相对地址),对引用符号手动重定向。
解析符号地址面临的挑战主要有两个:
- 找到运行中的程序的符号所在的地址。
- 如果存在两个或者以上相同名字的符号,找到正确符号。
2. 解决方法
符号的地址是在最终链接的时候决定的,如果可执行文件是pie(position independent executable)或者是动态链接库,符号的地址是一个相对地址,是相对于可执行文件或者动态链接库的代码段在内存中地址的偏移,计算公式Addr = Base + Offset。其他情况,符号的地址是一个绝对地址,无需计算。
同样名称的符号在可执行文件中可能出现多次(例如两个文件中定义了名字相同的static变量),我们需要从中找到正确的符号。在链接之后,可执行文件中的符号表会遵守一些固定的规则,相同源文件中符号会一起连续地记录,并且在记录的开头会有类型为STT_FILE的符号,名字为源文件的名字。
举个例子,我们在1.c和2.c中同时定义了static int a,最终可执行文件中的符号表如下所示:
- # readelf -s exe
- …
- Symbol table '.symtab' contains 73 entries:
- …
- 41: 0000000000000000 0 FILE LOCAL DEFAULT ABS 1.c
- 42: 0000000000601038 4 OBJECT LOCAL DEFAULT 25 a
- 43: 0000000000000000 0 FILE LOCAL DEFAULT ABS 2.c
- 44: 000000000060103c 4 OBJECT LOCAL DEFAULT 25 a
因此我们可以通过file+sym规则找到正确的符号位置。假设函数引用变量a,并且函数在2.c源文件中,我们首先找到类型为STT_FILE的2.c这个符号,然后找到符号a就可以了。
我们知道符号的地址后可以对替换代码中的引用进行手动重定向编写,将编译时符号引用的重定向转换为我们自己在运行时可以识别的重定向(self relocation)。
- 首先,根据重定向类型和计算公式,计算出引用的符号,记录符号的信息,其中符号的地址在运行时可以得到。
- 然后,记录原有的重定向信息,其中重定向的地址在运行时可以得到。
- 最后,在替换代码(热补丁)被加载到目标程序的内存中时,通过之前记录的重定向内容,修改替换代码符号引用位置的内容,内容由重定向的类型、重定向的地址、符号的地址计算得到。
举个例子,替换代码中包含函数x,函数x会在地址P引用正在运行的程序中的函数y。当替换代码被加载到程序的地址空间时,地址P可以被确定,函数y的符号地址S可以被确定,根据替换代码中记录的重定向信息(假设重定向类型是R_X86_64_PC32,Addend是A),那么地址P的内容需要被修改为S+A-P。这样当函数x执行时才能引用到函数y的位置。
五、POC:生成替换代码、符号解析
本章节利用objdump等工具,对生成替换代码中的关键步骤进行POC验证。
假设我们有目标程序T(修复后名为T-patched),包含如下代码:
- void print(int i)
- {
- while (i) {
- printf("%d ", i--);
- }
- printf("\n");
- }
- void func()
- {
- print(4);
- }
patch文件如下:
- void func()
- {
- - print(4);
- + print(6);
- }
分别将源代码和修复后的源代码编译,生成T.o和T-patched.o。
通过objdump我们可以发现func函数前后发生了改变,地址0x4的指令不同。(其他函数不变,省略)。如下所示:
- # objdump -hdr -j .text.func T.o
- …
- Disassembly of section .text.func:
- 0000000000000000 <func>:
- 0: 55 push %rbp
- 1: 48 89 e5 mov %rsp,%rbp
- 4: bf 04 00 00 00 mov $0x4,%edi
- 9: e8 00 00 00 00 callq e <func+0xe>
- a: R_X86_64_PLT32 print-0x4
- e: c9 leaveq
- f: c3 retq
- # objdump -hdr -j .text.func T-patched.o
- …
- Disassembly of section .text.func:
- 0000000000000000 <func>:
- 0: 55 push %rbp
- 1: 48 89 e5 mov %rsp,%rbp
- 4: bf 06 00 00 00 mov $0x6,%edi
- 9: e8 00 00 00 00 callq e <func+0xe>
- a: R_X86_64_PLT32 print-0x4
- e: c9 leaveq
- f: c3 retq
所以提取出T-patched.o中的.text.func段。这就完成了替换代码的提取。
因为T-patched.o中的func函数在0xa的位置上引用了print函数,我们需要对print符号进行解析,在替换代码(热补丁)被加载到目标进程内存时,对0xa-0xd的四个字节重定向。
我们记录下这个重定向,类型R_X86_64_PLT32,Addend -4,符号print。
在替换代码被加载到目标进程中时,我们可以确定替换代码加载的地址。假设替换代码中func地址为0x7fa357ed79b0,原程序中print地址为0x7fa358a9979c。那么我们根据之前记录的重定向信息进行计算(V = S + A - P),将func偏移0xa的位置(4字节)写入0xbc1dde,计算方法如下:
- 0x7fa358a9979c + (-4) - 0x7fa357ed79ba = 0xbc1dde
这样重定向之后,替换代码中的func函数就能正确引用到原程序中的print函数。
最后,我们通过GDB观察T程序打入热补丁之后的行为:
- (gdb) disas func
- Dump of assembler code for function func:
- 0x00007fa358a997d8 <+0>: movabs $0x7fa357ed79b0,%rax
- 0x00007fa358a997e2 <+10>: jmpq *%rax
- …
以上可以看出原程序的func函数会跳转到0x7fa357ed79b0执行。
- (gdb) disas 0x7fa357ed79b0
- Dump of assembler code for function func:
- 0x00007fa357ed79b0 <+0>: push %rbp
- 0x00007fa357ed79b1 <+1>: mov %rsp,%rbp
- 0x00007fa357ed79b4 <+4>: mov $0x6,%edi
- 0x00007fa357ed79b9 <+9>: callq 0x7fa358a9979c <print>
- 0x00007fa357ed79be <+14>: leaveq
- 0x00007fa357ed79bf <+15>: retq
- End of assembler dump.
以上可以看出0x7fa357ed79b0是热补丁中func函数的入口,也能看出0x00007fa357ed79b9地址的指令中引用了正确的print符号。
我们通过objdump、gdb验证了替换代码的静态和动态形式,展示了自动生成热补丁的具体细节,希望可以借此让读者对此有更清晰的理解。
六、其他注意事项
这种前后目标文件比较生成替换代码的方法,要求我们必须拥有正在运行的目标程序的源代码。同时,在编译目标文件时强烈建议使用和目标程序相同版本的gcc和编译选项,使用不同的gcc和不同的选项可能会导致目标文件和原始程序的二进制不匹配,导致不能生成正确的替换代码。不正确的替换代码可能会导致符号解析错误,进而是程序崩溃,这里需要特别注意。
七、写在最后
本文介绍了二进制比较方式的自动生成热补丁技术,相比于上一篇文章中介绍的简单热补丁技术,优势在于:
- 通过工具自动生成热补丁,无需手动编写热补丁,减少了人为出错的可能。
- 可以修复本地函数和全局函数,并且不需要引入函数的依赖链。
- 兼容多种编译型语言(C语言、C++、汇编等,具体实现不同,但是思路一致)。
使用这种热补丁生成技术,可以解决应用程序几乎所有的安全漏洞。例如最近出现的QEMU CVE-2017-2615(cirrus驱动内存越界访问),我们对有bug的函数都打上了热补丁,通过替换bug函数,实现了在线热修复。
生成热补丁是应用程序热补丁技术框架中非常关键的一个组件,本文介绍了一种自动生成热补丁的技术,但是完整、成熟的热补丁框架还包含了其他技术,例如多线程、管理多个热补丁、多版本管理、热补丁与程序之间的一致性检查等等。
【本文是51CTO专栏机构作者“大U的技术课堂”的原创文章,转载请通过微信公众号(ucloud2012)联系作者】