前言
在一个分布式系统中存在着各种各样的并发事件,对于某些存在内在因果关系的事件需要知道事件的先后顺序,并且能够按照正确的顺序处理这些事件,区分事件的先后顺序在单机系统中可以靠本地时钟来做到,但在分布式系统中如何做到呢,这就是分布式系统中的logical time问题。
本文为大家介绍logical time算法的鼻祖Lamport Clock。
为了形象地描述logical time问题,我们举个简单的例子,假设客户A下单购买了一本书,这时系统向订单系统提交a请求(客户买书的订单),然后购买该书还有个优惠活动,能够获得一本赠书,这时系统需要向优惠活动管理系统发送b请求(客户要求赠书x),优惠活动管理系统检查准许客户的赠书请求,于是将b请求转发给订单系统,在该例子中显然订单系统应该先收到买书的订单,然后是赠书的订单,但是由于网络延时的原因,可能存在赠书请求先于买书请求到达订单系统的情况,那么这种情况需要如何处理?
我们用简单的图来描述上面的过程,图中P0代表订单系统,P1代表客户,P2代表优惠活动管理系统,a请求就是买书请求,b请求就是赠书请求。

为了解决该问题比较容易想到的做法就是同步通信,发送a请求后等待P0处理完成并回复后再开始发送b请求,该方法简单易实现但是并不能发挥分布式系统的并发性能,效率低下,也不能简单地用给时间a和b打上本地时间戳的方式来处理,因为分布式系统中本地时钟是无法做到完全同步的,所以需要一种适用于分布式系统的能将事件的先后顺序信息也被称为“ happened before”信息识别出来的算法,本文主要介绍logical time算法的鼻祖Lamport clock。
Lamport clock算法
Lamport clock算法的思想很简单,主要有以下两个规则:
- 每个process在成功完成一个事件后都增加自己的时间戳,通常是加1;
- 如果process Pi通过消息m发送了事件a,那么该消息m中包含了当前pi的时间戳Ci(a);process Pj收到消息m后,取消息m中带的时间戳和Pj当前的时间戳Cj中的较大值然后加1;
例如一个较为复杂的例子,已经用Lamport clock算法为每个事件加了时间戳,如下图:
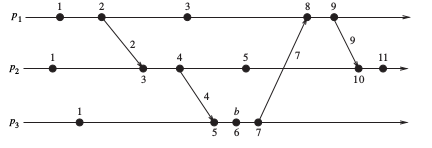
通过该例子可以发现存在一些并没有明确的先后关系的并发事件,比如p1上的时间戳为3的事件和p2上的时间戳为4的事件,这些事件可以是任意先后或者同时发生,但在Lamport clock算法中这些事件却有了明确的时间戳,该时间戳的大小并不代表事件的先后顺序。
重要属性
用简单的公式来描述logical time算法的Clock Condition,C表示时间戳,ei 和 ej表示两个事件,假设ei先于ej发生,并用->表示该“happened before”关系,那么存在以下两个Clock Condition:
1) ei -> ej => C(ei) < C(ej)
表示如果ei先于ej发生,那么ei的时间戳C(ei)必定小于C(ej)。
2) ei -> ej <=> C(ei) < C(ej)
表示如果ei先于ej发生,那么ei的时间戳C(ei)必定小于C(ej),如果C(ei)小于C(ej),那么ei必定先于ej发生。
根据算法是否满足以上Clock Condition来区分其所具备的属性,如果一个算法满足Clock Conditon 2,那么该算法具备strongly consistent属性,本篇文章介绍的Lamport clock算法只满足Clock Condition 1,所以不具备strongly consistent属性,但后续介绍的vector clock算法具备strongly consitent属性。
strongly consistent属性的意义在于是否可以通过C时间戳来判断出事件ei与ej的顺序关系,具备该属性的算法,当时间戳C(ei) > C(ej)时,可以确定ei先于ej发生,否则可以认为ei与ej是冲突的(这里的冲突表示ei与ej可以是任意的先后关系),所以可以用来检测事件的冲突。
案例分析
使用Lamport clock对之前的例子做排序,如下图:
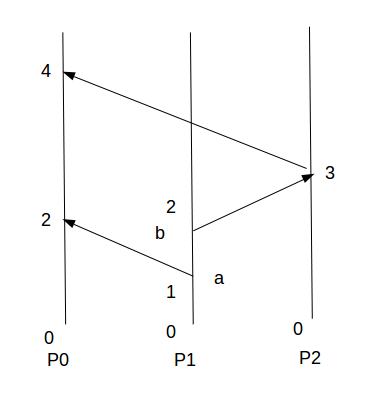
P1发送a消息和b消息,因为P1的初始时间戳为0,所以按照Lamport clock算法事件a和b的发送时间戳为1和2。
P0收到P1的消息a,取两者时间戳的较大值max(0,1)并+1得到时间戳为2。
P2收到b消息后,取两者时间戳的较大值max(0,2)并+1得到时间戳为3。
P0收到P2转发的事件b后,取两者时间戳的较大值max(2,3)并+1得到时间戳为4。
所以在P0端可以得到事件a是先于事件b的。
但在实际的应用中由于存在网络延时,会出现以下情况:
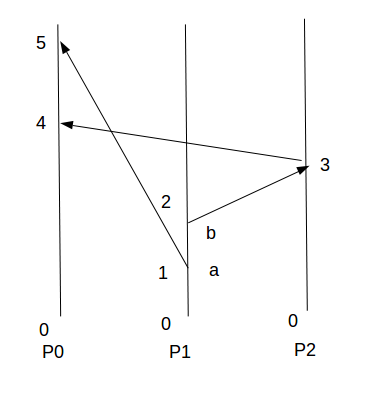
因为网络延时导致P0先收到P2转发的b事件,再收到P1的a事件,然后根据Lamport clock算法计算出来的时间戳也变成了b事件先于a事件了,这显然是错误的,那么要如何避免出现这个情况,为了关注解决该问题的实际算法,假定系统已经满足以下条件:
- 消息的接受顺序与发送顺序一致;
- 所有的消息最终都会被收到;
每个process都有自己的请求队列,并且对其他process不可见,请求队列中的初始时间戳为0,算法由以下5条规则组成:
1) 请求资源时,process Pi发送消息Tm,给其他所有process,并且将消息Tm置于它的请求队列中
2) prcocess Pj收到Pi的资源请求消息Tm后,将该消息置于自己的请求队列中并发送一个带有时间戳的回复给Pi
3) 释放资源时,Pi将消息Tm从请求队列中移除,并发送资源释放消息给所有其他process
4) process Pj收到Pi的资源释放消息后将之前的资源请求消息Tm从请求队列中移除
5) 当满足以下2个条件时认为Pi获取了资源
- Pi的请求队列中有请求消息Tm,并且按照顺序排列好的,这里以消息的发送顺序为准;
- Pi收到了任意一个时间戳比Tm要大的消息;
把这个算法带入到上面的例子中,相当于P1发起了两个事件a和b来请求资源,a比b要先发生,那么也期望a比b要先被P0处理(这里处理可以理解为获取了P0的资源),那么当出现上述例子中的情况,事件b先被P0收到,按照算法,P0发送Tm给所有其他process,然后等待回复,当收到P1的回复时a事件也必然被收到了(按照系统假定满足的条件1)消息的接受顺序与发送顺序一致),这时按照规则5的(i)条件,会根据事件a和b的发送端的时间戳比较,重新排序为a事件先于b事件,这样就解决了因为网络延时导致的消息乱序问题。
总结
Lamport clock虽然作为分布式系统中解决logical time问题的鼻祖,为后续其他算法提供了思路,但其不具备strongly consistent,无法满足分布式数据库场景中写冲突的检测,所以实际场景中更多是使用后来的vector clock,后面我们将会给大家介绍vector clock。
【本文是51CTO专栏机构作者“大U的技术课堂”的原创文章,转载请通过微信公众号(ucloud2012)联系作者】