神经网络机器翻译(Neural Machine Translation, NMT)模型自2013年在学术界首次被提出后,就不断快速发展,目前在某些语种和场景下,译文质量甚至可以达到人工翻译的水平。
阿里翻译团队自2016年10月起正式开始自主研发NMT模型,2016年11月首次将NMT系统的输出结果应用在中英消息通讯场景下的外部评测中并取得了不错的成绩,翻译质量有了大幅度提升。

但是,由于NMT模型的结构复杂,且深度神经网络模型本身的训练过程一般又会涉及很大量的计算,因此NMT系统往往需要较长的训练周期,例如,使用3000万的训练数据在单块GPU卡上一般需要训练20天以上,才能得到一个初步可用的模型。
基于上述问题,2017年2月初开始,阿里翻译团队和阿里云Large Scale Learning的穆琢团队合作,共同开发支持分布式训练的NMT系统,并于2017年3月底完成了第一个版本的分布式NMT系统。
项目成果
在2017年4月份的英俄电商翻译质量优化项目中,分布式NMT系统大大提高了训练速度,使模型训练时间从20天缩短到了4天,为项目整体迭代和推进节省了很多时间成本。
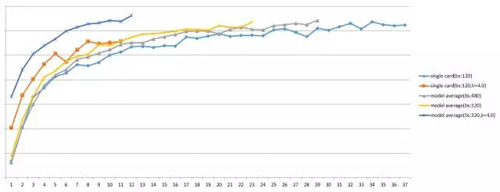
图一:使用不同卡数时,在中英100万训练语料上获得的收敛加速比
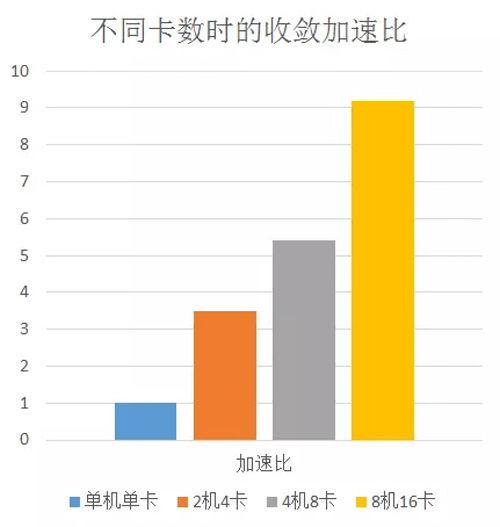
在4张GPU卡上,可以达到3倍以上的收敛加速比,在8张GPU卡上,可以达到5倍以上的收敛加速比,在16张GPU卡上,可以达到9倍以上的收敛加速比,通过不断累加GPU卡数,收敛加速比预期还会继续提升。
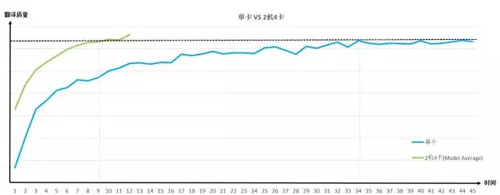
图二:中英2000万训练集上,利用2机4卡进行分布式训练的收敛过程
图三:多种分布式策略的加速效果对比
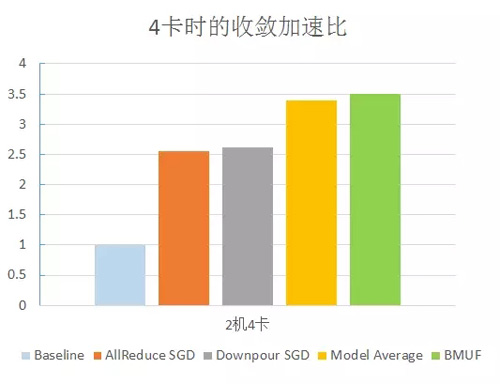
除了基于MA的分布式实现,项目组还尝试了其他多种分布式实现方法,也都获得了不同程度的加速效果,包括Downpour SGD、AllReduce SGD以及使用了BMUF(Blockwise Model-Update Filtering, 一种针对Model Average方法的改进方案)策略的Model Average方法。
实现方案
关于多机多卡分布式方案的讨论
data parallel数据并行
基于data parallel的同步SGD算法,即使用多个worker均摊整个batch的计算量,且每个GPU(worker)上存储完整的模型副本。Tensorflow本身提供的PS框架可以直接用于实现此算法。标准的同步SGD算法每次迭代都分为三个步骤,首先,从参数服务器中把模型参数pull到本地,接着用新的模型参数计算本地mini-batch的梯度,最后后将计算出的梯度push到参数服务器。参数服务器需要收集所有workers的梯度,再统一处理更新模型参数。
因此,在ps框架下,同步SGD算法的总通信量 transfer data = 2 * num_of_gpus * size_of_whole_model。通过对模型的大小和一个mini-batch计算时间的评估,发现在单机两卡的情况下,由于PCIe的带宽较高(~10GB/s),可以获得接近2倍的加速比,但两机两卡的情况下,计算通信比则为1:1,而随着机器数的增多,不但没有带来加速,反而比单卡更慢。
可见,通信优化是同步SGD算法的主要问题,下面的具体方案介绍中,我们也展示了相关的实验结果。
hybrid parallel混合并行
模型并行可以通过模型参数的存储策略,利用参数的稀疏性,减少参数的实际通信量,对训练过程进行加速。一般情况下,适用于稀疏模型的训练,但对于特殊的网络结构,模型并行可以和数据并行相结合,提高全局的计算通信比,我们这里称之为hybrid parallel。以AlexNet举例来说,可以把模型结构分为全连接层和卷积层两部分,从而对两个部分分别分析计算通信比。
全连接层计算通信比极低,毫无扩展性,而卷积层的计算通信比较高,适合使用数据并行,因此hybrid parallel的方案是:多个workers使用数据并行的方式计算卷积层,而只需一个worker(或极少量workers)计算全连接层,以获得最高的计算通信比,且卷积层和全连接层中间只有一个规模很小的feature map需要通信。
通过对NMT的模型中各个层进行profiling,发现网络中各部分的参数大小相差不大,计算量也相当,不但计算通信比不高,各层结构之间传递的feature map也较大,并不适合使用hybrid parallel的方式。
分布式方案的进一步探索
基于以上的分析,我们对分布式方案进行了进一步的探索。为了最大程度的获得多机多卡的扩展性,我们选择了Model average、BMUF、downpour等分布式方法。Model average(MA)方法较于简单的数据并行,有两个显著的优势:一、通信量可以通过同步频次来调节,两次同步的间隔可以以step甚至epoch为单位来控制,一般情况下,通信开销几乎可以忽略不计,从而获得线性的计算加速比;二、batch size的大小可以和单机baseline保持一致,基于数据并行的同步SGD,通常为了保持计算通信比而同比增大batch size,导致精度损失。
但是,MA方法、BMUF方法以及基于异步更新的downpour方法,对调参的要求都更高,不同的参数设置,会对模型的收敛结果有较大的影响,计算加速比的提高并不意味着收敛加速比的提高。下文是对各个实现方案的消息介绍和结果展示。
基于Model Average方法的分布式训练方案
方案概述
Model Average方法,即每个worker负责训练本地的模型,多个GPU之间通过固定(或动态)的频率求取各个模型的均值,并以此作为继续训练的基础。
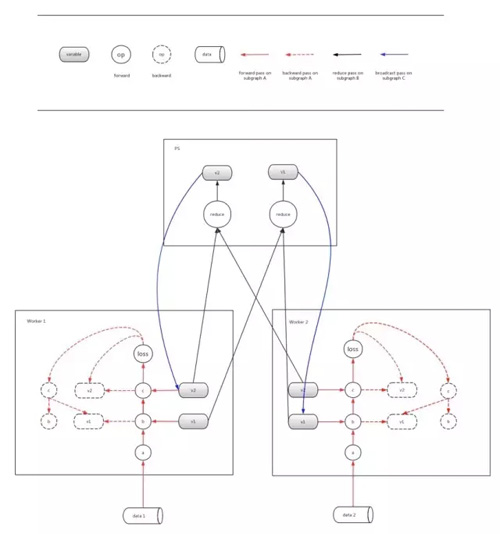
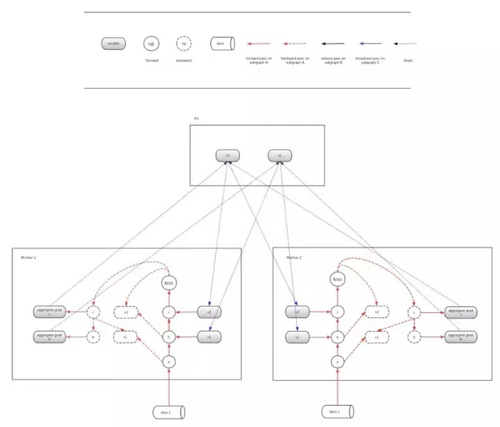
基于Tensorflow的Model Average设计主要分为graph构建和分步run两部分。
1. 首先,由于每个worker需要在各自的进程内进行求解,所以需要在每个worker上分别进行构建forward-backward子图,这一部分的子图在上图中用红色的箭头线表示。应当注意,每个worker上应该具有独立的op和variable。
2. 其次,需要在ps上维护一份模型拷贝,并构建Reduce Average的子图,这一部分的子图在上图中用黑色的箭头线表示。
3. 然后,需要构建broadcast的子图,这一部分的子图在上图中用蓝色的线表示。(这里由于美观,在图中没有画出全部的broadcast依赖关系,ps的variable 1和variable 2都应该和worker 1和worker 2中的variable 1和variable 2建立依赖关系)
4. 在构建上述依赖关系后,我们需要通过client启动Model Average的机制。用户只需要通过控制session run的顺序来指定每个子图的求解即可完成。在这里,红色的子图需要每轮都run,而到了一定轮数间隔后开始依次run黑色的子图和蓝色的子图即可完成Model Average的机制。
在实现上,可以用主worker完成所有子图的构建,其他worker处于join状态。在运行时,各个worker会根据图中的依赖关系驱动起来。
超参的调整
当两机四卡的参数保持和单机单卡baseline参数一致的情况下,从多组实验中可以观察到,不同的同步频次对模型的质量有影响,加速比最快只达到1.5。通过推导,我们发现,MA方法中每次计算多个worker的模型均值,都相当于把每个训练样本对模型梯度的贡献缩减为原来的1/num_of_gpus, 大大抵消了多卡带来的加速。因此,MA中的本地训练learning rate(lr)应该调整为原baseline lr的num_of_gpus倍。
实验结果
其中bs表示batch size,lr表示learning rate,横坐标是训练时间,纵坐标代表翻译质量。
使用BMUF方法对Model Average方案进行改进
方案概述
上面提到的Model Average方法在两卡、四卡、八卡上均获得了较高的加速比,在不断并行扩展的过程中,需要根据机器的个数对lr进行调整,然而lr的大小一定有一个适当的范围,并不能无限的增大,随着机器数的增多,这种naive MA方法也逐渐暴露出它的局限性。
BMUF(Blockwise Model-Update Filtering)是Model average(naive MA)的一种优化算法,最主要的区别是引入了梯度的历史量。MA算法等价于在每次同步时,把所有workers上的模型增量加和平均,作为“block gradients”,用于更新参数服务器上的全局参数,而BMUF的“block gradients”则在此基础之上,增加了另外一项历史梯度,且历史梯度的权重为block momentum rate。
具体推导如下:


MA:一个mini-batch的训练数据对最后模型的贡献公式为:
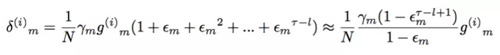
BMUF:一个mini-batch的训练数据对最后模型的贡献公式为:
![]()
从公式中可以看出,MA中单个mini-batch的贡献在average阶段被缩小为原来的N分之1,如果要保持和baseline一样的贡献度,则需要增大lr。而BMUF相比baseline的贡献比为:
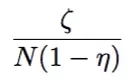
超参的调整
上文的公式可以指导BMUF训练过程中参数的调整。BMUF最主要的参数有两个,一是block learning rate(blr),此超参一般设为1.0,和MA算法一致,二是block momentum rate(bmr),可以通过调整bmr为1-1/N,从而保持lr不变,总的贡献量和baseline一致。此外,引入了历史梯度后,还可以结合Nesterov方法,在本地训练时先对本地的模型更新已知的历史梯度,再进行训练,从而进一步加速了收敛。
实验结果
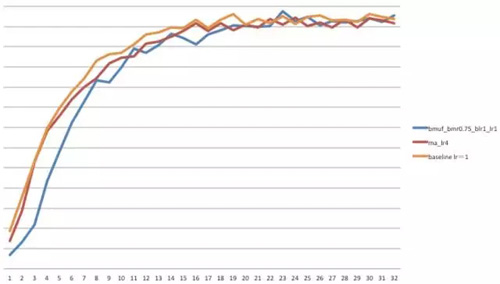
上图横坐标代表已训练的总数据量,即每个计算节点训练数据量的总和(最理想的情况,收敛曲线应该和baseline重合甚至更高),纵坐标代表模型的翻译质量。可以看到MA和BMUF在两机四卡上可以获得相当的加速比,BMUF的优势在于,可以通过调节bmr从而把learning rate(lr)可以保持在与单机单卡的baseline一个量级,因为lr有一个较为适当的范围,不能随着GPU的增多无限制增大。BMUF的效果在更大的lr以及十六卡的实验中已得到体现。
基于Downpour SGD方法的分布式训练方案
方案概述
和MA的设计类似,Downpour SGD的设计也比较自然,同样分为graph构建和分布run两部分。在这里需要注意的是,Downpour SGD方法是一种ASGD的异步分布式训练方法,其在Apply gradients时是不需要多个worker之间同步的。
下面具体介绍Downpour的整体流程。
1. 将ps上的model weights拉到每个worker上。
2. 每个worker自己求解本地的model,在求解过程中,不但要对本地model进行参数更新,还要将梯度累加到另一组variable中保存。
3. 当本地worker求解到一定轮数后,将本地存储的累积梯度异步apply到ps的model参数上。
这种方式在实现上,需要在每个worker上再保存一份variable用来存储梯度的累积量,并且在构图时需要对optimizer进行更改,主要体现在需要将AdaDelta计算的梯度在apply到自己的模型上之前先累加到本地的variable中,然后再apply到自身参数中。
这里还存在一个问题关于累加梯度的问题,因为在AdaDelta的实现中,实际上apply到model上的量包含梯度和delta量两个部分,因此在累加上有可能需要将这些delta量也考虑进去。在实现时,无需重写新的optimizer,只需要将调用apply gradients前后的model weights相减即可得出正确的结果。
Downpour SGD会带来一些其他的超参数,这其中就包括push gradients和pull weights的间隔轮数,我们称之为step。另外,若push和pull的step过大,也会导致这期间的累积梯度过大,如果此时直接将累积梯度apply到weights上很可能会出现NAN的情况,因此需要对累积梯度做clipping操作,所以对累加梯度进行clipping的norm值也是一个额外的超参数。
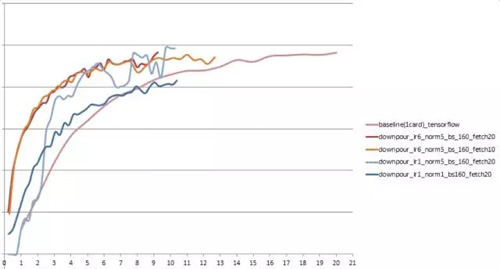
超参的调整
由于ASGD带来的异步性,导致调参的难度相对于同步SGD更为困难,而且Downpour SGD的超参数确实比较多。为了加快训练的速度,减少每个epoch的迭代时间,我们采用了比较激进的weak scaling的方式,即每个worker都使用较大的batch size。
但是应当注意,虽然增加batch size会使过数据的速度加快,但也会让每个数据的学习效果降低,这是因为和小batch size相比,我们更新模型的频率大大降低了,因此我们需要同时加大learning rate。另外,在异步条件下,每个worker计算的累积梯度都有可能成为stale的gradients,这些gradients的表示的方向并不一定最优,相反,有时候会很差。
倘若我们不对这些累积的梯度进行clip,那么很可能出现NAN的情况,因此我们需要调整累积梯度的clipping norm值。但是clipping norm值越小,梯度值就被削弱的越狠,模型的学习效果就越不好,它与learning rate的调参是一对trade off。最后,用于push和pull的step间隔值不宜过大,因为过大的step会导致过大的累积梯度,如果此时使用较小的clipping norm对累积梯度进行削减,那么这将意味着如此长轮数计算出来的累积梯度效果将被削减。在实验中我们发现这个step间隔轮数设置在20左右比较理想。
综上所述,调参的基本目标是,固定push和pull的step间隔轮数后,选取较大的batch size并适当增加learning rate,逐步调整增加clipping norm的大小,使学习效果达到最大。
实验结果
其中bs表示batch size,lr表示learning rate,norm将累积梯度做clipping的最大值,fetch为downpour中push和pull的间隔值,纵坐标代表翻译质量值,横坐标是训练时间。
基于Ring-allReduce SGD方法的分布式训练方案
方案概述
上文提到,同步SGD算法每次迭代都需要pull参数和push梯度这两次通信,这样的一个push+pull的过程对于整个系统来说,等价于一次allreduce操作,通信量相当于2 * nGPUs * model_size,随着GPU个数的增多,allreduce成为最主要的性能瓶颈。
Ring-allReduce op
Allreduce聚合通信已有较成熟的优化方法,最常用的方法之一有Ring allreduce。其基本思想是将allreduce分拆成reduce_scatter和allgather两步。
1. 首先,根据节点数对待通信的message进行分片,分片的数量与通信的节点数相同(不需要额外的参数服务器)。
2. 开始进行reduce_scatter操作。对worker(i)来说,第j次通信是把自己的第j片message发送给worker(i+1),并把收到的消息累加到message的对应片段。如此经过n-1轮的环状流水线通信后,每个worker上都有一个分片是reduce了所有workers的结果。
3. 然后开始allgather操作。第j次通信是把自己的第j+1片message发送给worker(i+1),如此经过n-1轮通信,所有worker的整个message就都经过了reduce操作,即完成了all_reduce操作。
ring-allreduce方法可以使得集群内的通信总量保持在一个常数,略小于2 * mdoel_size,不随并行规模的增大而增多,有很好的扩展性。
gRPC vs MPI
Ring-allreduce方法能够带来性能提升的前提是:latency的开销相对于bandwidth来说可以忽略不计,因为ring allreduce虽然降低了通信总量,却增加了通信次数。当前tensorflow的通信协议只支持gRPC,通信的latency较高不能被简单忽略,而使用基于支持RDMA的cuda-aware MPI来实现allreduce op,效果则更加显著。
此外,allreduce操作同样存在于Model average算法中,同样可以带来一定的性能收益。
超参的调整
因为对于同步SGD分布式算法,如果保持Total Batch size不变,每块GPU卡上的mini batch size会随着GPU卡数的增多而减小,其计算时间并不是线性减少,因为当batch size足够小后,计算时间会逐渐趋于平稳,虽然通信已经通过优化而大幅减少,计算的拓展性依然有限。因此,在使用多机多卡的同步SGD时,batch size与GPU个数同比例增大,同理,为了保持单个训练样本的贡献,lr也同比增大。
实验结果
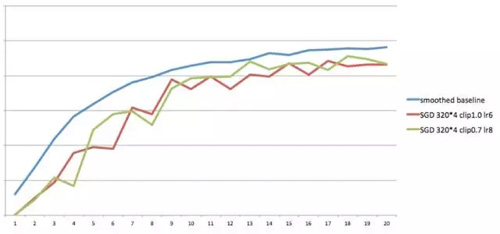
上图中,多卡同步SGD的总batch size设置为1280,是baseline(batch size=160)的8倍,横坐标代表已训练的总数据量,纵坐标代表模型的翻译质量。在InfiniBand(10GB/s)网络上,获得4倍的计算加速比,在万兆(1GB/s)以太网上,获得2.56倍计算加速比。但batch size的增大会影响收敛精度,上图可以看到,收敛的最高点比baseline略低,有明显的精度损失。
未来工作
上一阶段工作主要集中在模型训练阶段的加速策略上,接下来的工作主要分为两方面:一方面是继续挖掘分布式训练的加速潜力,通过系统与算法相结合的优化策略,最大化利用硬件资源,提升收敛加速比,并将分布式优化策略和算法模型本身解耦,实现复杂DL模型分布式加速功能的组件化和通用化。
另一方面,需要在现有的服务化方案的基础上,进一步通过模型精度压缩、网络结构简化等方式,在保证模型效果的同时,提高解码速度,降低线上延时,进而增强线上服务能力,节约服务化所需的硬件成本。
【本文为51CTO专栏作者“阿里巴巴官方技术”原创稿件,转载请联系原作者】