企业数据中心团队可以从超大型云服务提供商那里学习到相应的重要的经验教训。与此同时,企业还应重新思考其冗余策略,并考虑采用诸如像SDN这样的技术来帮助提高效率。
现如今,在数据中心领域,超大规模云服务提供商所带来的效率和自动化程度的提高也已经开始逐渐转为向传统的数据中心普及了。
从***的冷却技术到自动化配置的一切都是为了提高普通企业数据中心的效率,并帮助降低成本。
Vantage数据中心的***运营官,亚马逊网络服务(AWS)基础设施运营前任副总裁Chris Yetman表示:“您企业正在获得起草效应,就像您在参加一场赛跑一样。跑得快的在前面领跑,落在后面的每个竞争者也都在这样的氛围下奋起直追。”
同理,那些落后、因仍在采用旧的运维方式而陷入困境的数据中心IT***们可以从超大规模云服务提供商那里学习经验,并吸取教训。数据中心设施咨询机构Uptime Institute的IT优化和战略副总裁Todd Traver表示,今天的许多企业组织机构都在努力地做出关键决策。
他说:“***的益处来自于领导层占据了强硬立场的企业组织机构,并已制定了相应的机制,以追踪利用和目标。”
反思冗余策略
直到大约四年前,大多数企业都还在依赖于2N基础架构,这是一种冗余策略,其中数据中心每款基础设施组件的数量是数据中心基本运营所需组件数量的两倍。例如,如果一家公司需要10台服务器进行正常运行,那么一个2N架构将需要20台服务器。现在,由于应用程序的多样性,以及对物理基础设施的依赖性较小,因此混合架构得到了广泛的认可。
更多的企业组织则更倾向于采用N + 1冗余架构,这种方法使公司只保留比正常运行所需只多一个的备用基础架构组件。
一家位于美国旧金山的托管服务提供商Digital Realty Trust公司的全球业务高级副总裁丹尼·莱恩(Danny Lane)表示,在过去几年中,客户已经减少了对2N冗余架构的依赖。
Lane表示说,虚拟化技术和云架构固有的应用弹性已经帮助Digital Realty公司的客户们将其硬件占地面积减少了约20%。
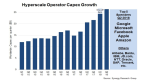
尽管如此,根据IDC最近的一项调查显示,只有9%的IT***相信他们的数据中心得到了优化,这项调研是IDC受一家设在美国明尼苏达州伊登普雷利的数据中心设计和管理提供商Datalink公司的委托进行的。毫无疑问,如果拿同样的问题来采访诸如AWS、Microsoft或Google等超大规模云服务提供商,则又会得到完全不同的答案。
Datalink的虚拟化和云计算实践总监Kent Christensen表示:“这告诉我们,一般的普通企业现在并不觉得他们是在像AWS云一样运行的。 “他们的确正在演变,但是仍然觉得发展速度还不够快。”
一个重要的起点可以从重新评估高可用性(HA)和可靠性、可用性和可维护性(RAS)功能开始着手。戴尔EMC超大规模基础设施部门(extreme scale infrastructure unit)总监Jyeh Gan表示,企业需要摆脱冗余和弹性必须建立在每一块硬件中以防止故障的想法。相反,企业组织需要从硬件抽象软件,以便其可以在一切之上运行,然后采用设计用于能够克服硬件故障的弹性应用程序。他说,这样可以没有HA和RAS的功能。
Gan表示说:“大多数企业远还未达到这一程度,但他们也不会在这一程度水平持续多年。” “即使是超大规模供应商也没有完全达到这一程度水平。”
通常情况下,当一家公司在市场竞争中面临对手的竞争时,落后的企业将积极部署现代化。经常,当他们采用一些超大型数据中心运营商的经验教训时,Gan说。
但是,这一过渡不可能非常突然,也不会非常简单。相反,这需要分阶段完成,他指出,他所在的公司正在与逐渐删除HA和RAS系统管理功能的公司合作。他说,拥有一套旨在部署,管理和监控服务器的软件的公司不应该从消除整个套件开始。而应该转移到Redfish环境——借助一款标准的RESTful API来管理服务器——将其作为一个初始步骤。
Gan表示,企业组织很容易了解到保持竞争力的驱动力,但是,在数据中心操作人员面临这么多不熟悉的概念和技术的前提下,很难顺利和有条不紊地完成整个过程。
云计算
大型公共云服务数据中心的特点已经开始在更典型的企业组织通过使用企业内部部署的本地产品中更频繁地出现了。分析公司IDC的一名研究主管Kuba Stolarski说,在超大规模云提供商架构之后,超融合基础设施在一般性的普通企业也开始被建模。
他说:“这真的是采用了Google,Facebook等的模式来确定如何更有效地进行虚拟化存储。”
Vantage公司的Yetman说,在另外一些企业组织机构的数据中心中已经开始出现的进步是软件定义的网络。
Yetman说:“一家像AWS或微软这样的大型云服务提供商所做的便是寻求方法来削减更高的成本开销。”
这导致了低成本交换机的设计和开发。他说,企业可以复制传统供应商所提供的产品,并避免每台交换机花费数千美元,转而购买800美元的产品,也同样奏效。
Facebook、微软Azure和AWS都使用标准硬件来构建自己的路由器版本。一些具有定制基础设施的大公司,如Facebook和LinkedIn,已经分享了他们的设计。 Yetman说:“每家企业都可以从中受益,并以更低的成本构建一个网络,而且仍然可以合理地获得支持。”
Uptime的Traver,还拥有二十多年在IBM从事各种数据中心设计和效率项目的经验,他表示说,超大规模云服务提供商对数据中心的有条不紊的管理使他们与大多数企业组织区别开来。
超大规模数据中心运营商知道如何在任何特定情况下做出反应,而许多企业则可以从中获益。
例如,一项典型的业务可能依赖于员工之间经常互相交流来运行数据中心。相反,超大型数据中心运营商可能在世界各地的数据中心位置拥有数百人负责运维。为了整合分布式知识,超大规模运营商通常使用文档化的方法来维护特定的运行书。
效率自动化
超大规模运营商的效率在很大程度上来自于人工手动流程的自动化和使用同质的服务器。
Traver说,企业已经开始减少在数据中心中安装各种类型的服务器和虚拟机了。数据中心运营商的变化越来越小,可以更好地管理工作负载。高效的企业组织将把服务器与管理所有服务器整体的协调层组合在一起。
为了达到峰值利用率,数据中心运营商需要预测实际机架载荷,这对于大多数大型企业而言是困难的,Aligned数据中心***执行官Jakob Carnemark说。
他说,超大型数据中心的密度通常平均每机架15千瓦,这是目前大多数数据中心密度的五倍。企业组织需要预测数据中心密度,以便管理基础架构效率。
Carnemark表示:“除极端超大规模企业以外,任何企业都可以做到这一点。”
Yetman表示,销售数据中心产品的供应商已经注意到超大规模云提供商所采用的策略,并应尽快开发可供更多典型客户使用的管理工具。
例如,Google已经开始使用人造智能(AI)来管理其数据中心的冷却。这使得他们每年在冷却成本方面实现了10%的节约。任何企业对于冷却成本减少10%无疑都是相当欢迎的。对于Google而言,这意味着节省1亿美元。
“如果DCIM提供商们足够聪明,那么他们将会看到他们如何能够复制这种成功,并将效率传递给他们的客户,而这些客户往往是企业。”Yetman说。
虽然AI对于许多公司来说太复杂了,但至少有一家或两家供应商将能够很快复制Google所做的工作,以帮助企业组织以类似的方式管理数据中心环境。
除了缺少超大规模外,没有什么其他的因素会妨碍一般性的企业组织的数据中心实现超大型数据中心的效率。
克里斯坦森说,一家已经认识到需要实施类似云服务效率的企业往往会试图让整个数据中心团队都参与进来。如果有阻力,他已经看到有公司会让另一个团队来做。
他说:“这另一支团队将会带来一个新的想法和理念,并尝试做出改变,但这另一只团队的运作会随着时间的推移变得不那么有价值。因为事情的变化是很快的,人们需要不断的调整。