最近看《机器学习系统设计》…前两章。学到了一些用Matplotlib进行数据可视化的方法。在这里整理一下。
声明:由于本文的代码大部分是参考书中的例子,所以不提供完整代码,只提供示例片段,也就是只能看出某一部分用法,感兴趣的需要在自己的数据上学习测试。
最开始,当然还是要导入我们需要的包:
# -*- coding=utf-8 -*-
from matplotlib import pyplot as plt
from sklearn.datasets import load_iris
import numpy as np
import itertools1234512345
- 1.
- 2.
- 3.
- 4.
- 5.
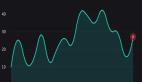
1. 画散点图
画散点图用plt.scatter(x,y)。画连续曲线在下一个例子中可以看到,用到了plt.plot(x,y)。
plt.xticks(loc,label)可以自定义x轴刻度的显示,***个参数表示的是第二个参数label显示的位置loc。
plt.autoscale(tight=True)可以自动调整图像显示的***化比例 。
plt.scatter(x,y)
plt.title("Web traffic")
plt.xlabel("Time")
plt.ylabel("Hits/hour")
plt.xticks([w*7*24 for w in range(10)],['week %i' %w for w in range(10)])
plt.autoscale(tight=True)
plt.grid()
##plt.show()1234567812345678
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
画出散点图如下:

2. 多项式拟合并画出拟合曲线
## 多项式拟合
fp2 = np.polyfit(x,y,3)
f2 = np.poly1d(fp2)
fx = np.linspace(0,x[-1],1000)
plt.plot(fx,f2(fx),linewidth=4,color='g')
## f2.order: 函数的阶数
plt.legend(["d=%i" % f2.order],loc="upper right")
plt.show()123456789123456789
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
效果图:

3. 画多个子图
这里用到的是sklearn的iris_dataset(鸢尾花数据集)。
此数据集包含四列,分别是鸢尾花的四个特征:
- sepal length (cm)——花萼长度
- sepal width (cm)——花萼宽度
- petal length (cm)——花瓣长度
- petal width (cm)——花瓣宽度
这里首先对数据进行一定的处理,主要就是对特征名称进行两两排列组合,然后任两个特征一个一个做x轴另一个做y轴进行画图。
# -*- coding=utf-8 -*-
from matplotlib import pyplot as plt
from sklearn.datasets import load_iris
import numpy as np
import itertools
data = load_iris()
#print(data.data)
#print(data.feature_names)
#print(data.target)
features = data['data']
feature_names = data['feature_names']
target = data['target']
labels = data['target_names'][data['target']]
print(data.data)
print(data.feature_names)123456789101112131415161718123456789101112131415161718
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
这里有一个排列组合参考代码,***是取出了两两组合的情况。
排列组合的结果是feature_names_2包含了排列组合的所有情况,它的每一个元素包含了一个排列组合的所有情况,比如***个元素包含了所有单个元素排列组合的情况,第二个元素包含了所有的两两组合的情况……所以这里取出了第二个元素,也就是所有的两两组合的情况
feature_names_2 = []
#排列组合
for i in range(1,len(feature_names)+1):
iter = itertools.combinations(feature_names,i)
feature_names_2.append(list(iter))
print(len(feature_names_2[1]))
for i in feature_names_2[1]:
print(i)123456789123456789
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
下面是在for循环里画多个子图的方法。对我来说,这里需要学习的有不少。比如
for i,k in enumerate(feature_names_2[1]):这一句老是记不住。
比如从列表中取出某元素所在的索引的方法:index1 = feature_names.index(k[0]),也即index = list.index(element)的形式。
比如for循环中画子图的方法:plt.subplot(2,3,1+i)
比如for循环的下面这用法:for t,marker,c in zip(range(3),”>ox”,”rgb”):
plt.figure(1)
for i,k in enumerate(feature_names_2[1]):
index1 = feature_names.index(k[0])
index2 = feature_names.index(k[1])
plt.subplot(2,3,1+i)
for t,marker,c in zip(range(3),">ox","rgb"):
plt.scatter(features[target==t,index1],features[target==t,index2],marker=marker,c=c)
plt.xlabel(k[0])
plt.ylabel(k[1])
plt.xticks([])
plt.yticks([])
plt.autoscale()
plt.tight_layout()
plt.show()12345678910111213141234567891011121314
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
这里的可视化效果如下:

4. 画水平线和垂直线
比如在上面***一幅图中,找到了一种方法可以把三种鸢尾花分出来,这是我们需要画出模型(一条直线)。这个时候怎么画呢?
下面需要注意的就是plt.vlines(x,y_min,y_max)和plt.hlines(y,x_min,x_max)的用法。
plt.figure(2)
for t,marker,c in zip(range(3),">ox","rgb"):
plt.scatter(features[target==t,3],features[target==t,2],marker=marker,c=c)
plt.xlabel(feature_names[3])
plt.ylabel(feature_names[2])
# plt.xticks([])
# plt.yticks([])
plt.autoscale()
plt.vlines(1.6, 0, 8, colors = "c",linewidth=4,linestyles = "dashed")
plt.hlines(2.5, 0, 2.5, colors = "y",linewidth=4,linestyles = "dashed")
plt.show() 12345678910111234567891011
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
此时可视化效果如下:

5. 动态画图
plt.ion()打开交互模式。plt.show()不再阻塞程序运行。
注意plt.axis()的用法。
plt.axis([0, 100, 0, 1])
plt.ion()
for i in range(100):
y = np.random.random()
plt.autoscale()
plt.scatter(i, y)
plt.pause(0.01)1234567812345678
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
可视化效果: