












今天聊下调度,为什么说这个,主要是最近和人讨论和服务和服务之间的功能分界,被追问AWS data pipeline、AWS Step Functions和AWS Batch的区别,甚至追问Migration和pipeline的分界。因此特别写一篇文章说一说调度。
调度(scheduler),这个词说高大上也高大上,说low也low,看你怎么理解。理解low的会认为这就是定时任务,说高大上的知道要做好里面的难度,怎么解决***任务冲突,***资源利用其实都是很困难的事情。
聊到正题,AWS datapipeline/AWS Step Functions/AWS Batch三个服务在AWS分类里面分布放在“计算”“分析”“应用程序服务”三个大类里面,说明这几个服务完全都是一个层次的东西。

为什么会被人为冲突和重复呢,关键是这几个服务看上去都像是调度服务,负责任务的安排。下面分布来看看几个服务都是什么?
1. AWS data pipeline
https://aws.amazon.com/cn/datapipeline/?nc2=h_m1
这个是正经的大数据服务,EMR团队负责孵化出来。最开始核心解决的问题就是EMR服务的任务调度和数据移动,后面扩展到把大数据的相关的各个服务串接起来,解决服务和服务之间的数据移动和任务调度。
支持的服务包括DynamoDB,RDS,Redshift,S3,EC2,EMR。解决就是这些服务的周期的任务调度和数据搬迁。

服务将任务统一抽象叫着Activity,收费也是按照使用的activity按需计费。
这个服务解决的场景就是大数据常见的ETL/数据集成场景,不过它只提供很少的数据转换能力,大部分是客户自己编写任务(Activiy)然后上传到服务中调度,去完成业务逻辑的转换。
2. AWS Step Functons
https://aws.amazon.com/cn/step-functions/?nc2=h_m1
step functions是16年AWS revient大会新发布的服务,在这之前,AWS发布了一款AWS Lambda服务,Lambda服务是一个应用框架,使用者只需要编写业务逻辑代码片段(函数),放到框架中运行,而不用关心底层服务器的配置,实现了serverless,极大的简化了简单应用开发的门槛。
但是aws发现,当业务代码片段越来越多的时候,就需要有一个工具来协调和编排业务逻辑之间的依赖关系,以及管理这些代码片段(函数)的运行。这就诞生了step functions服务。
Step functions核心编排和调度的对象是Lambda服务商的逻辑代码片段(函数),并提供可视化诊断能力,快速问题定位。
Step functions也是按需收费,这个收费是按照转换次数来收费。(转换是stepfunctions定义的一个概念,当您从应用程序工作流的一个步骤转到下一个步骤时,您会在状态之间进行转换,我们将这一过程称为状态转换。其实说白了,一个步骤到另外一个步骤,这个过程就是step functions帮你根据你定义的业务逻辑做的调度的过程,一次转换就是stepfunctions帮你调度一次,然后就收你一次费用。)
去看这个step functions和AWS data pipeline内部调度原理其实是一样的,核心的就是DAG状态机,但是两者调度的对象不一样,data pipeline调度的是hadoop任务,这些任务运行本身至少是秒级以上,而step functions调度的对象是函数,毫秒级别的,所以具体实现的时候stepfunctions会要求轻量和高效很多,内部应该是通过事件来传递状态,应该是全内存实现,不像datapipeline一样持久化要求很高。
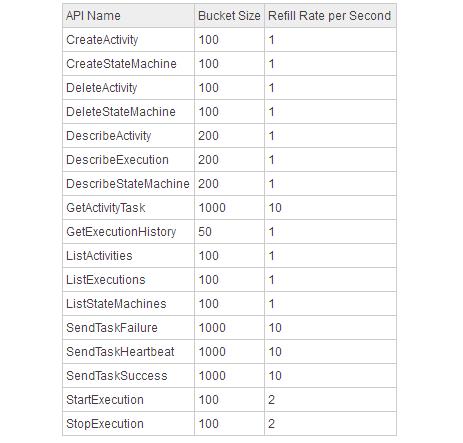
帮助中也有描述step functions的限制,是通过token bucket来维护服务的能力。
Some Step Functions API actions are throttled using a token bucket scheme to maintain servicebandwidth.
3. AWS Batch
AWS Batch调度的对象就更粗暴和简单,主要是HPC(AWS都是EC2)。前面有写过一篇HPC相关的博客,可以看看:云服务让HPC死而复生。
AWS Batch实际解决的场景是传统的金融,生物,视频转码等,有很多自编写的任务,需要HPC来完成,通过Batch可以简化这些工作的实现,实现一些定时的调度。
AWS Batch和前面不同的核心区别是,step functons和datapipelie对资源都不可见,解决的是任务/函数的调度,这是因为底层的大数据框架或者lambda框架本身就是分布式框架,解决的就是资源的管理和分配。AWS Batch调度的对象是HPC,所以AWS Batch和HPC绑定很紧密,核心要解决的问题就是任务并行调度到各种HPC资源上,同时可以解决一些分布式的问题。AWS声称可以自动分布任务,推测只是根据配置简单的做任务并行分布。
AWS Batch automatically provisions computeresources and optimizes the workload distribution based on the quantity andscale of the workloads.
这个服务本身定位为促进HPC的销售,所以在AWS里面不收费。另外,AWS Batch 可与商用开源工作流引擎和语言集成 (如 PegasusWMS 和 Luigi),让您能够使用熟悉的工作流语言为批量计算管道建模。核心是解决客户使用习惯问题。
AWS Batch调度的也是大颗粒任务,核心调度能力和Data pipeline有点类似,不过和各种HPC集成,以及对工作流语言的支持是其中的关键。
***简单总结一下吧。三个服务的核心功能都是调度,一些基本的调度能力,以及状态机是可以服用,但因为其调度的对象,核心场景不同。所以底层的实现机制存在差异以及主要的对接能力也不太一样,产品形态,收费模式,以及工作侧重点都不同。
【本文为51CTO专栏作者“大数据和云计算”的原创稿件,转载请通过微信公众号获取联系和授权】
























