大约3年前我开始使用R,起初进展很慢,与我习惯的语言相比,语法更加直观也比较简单,而且需要一段时间才能习惯于细微的差别。我还不清楚语言的力量与社区和各种包的密切关系。
和其他语言(比如Python和Java)相比,R可以更模糊和麻烦。好消息是,有大量的包可以在R基础库上提供简单和熟悉的界面。这篇文章是我喜欢和每天使用的10个包,并且我希望自己能早些知道他们。
1. sqldf
R语言学习曲线中最陡峭的一部分就是语法,我花了一段时间才习惯使用<-代替=。我听到很多人问如何实现VLOOKUP?!?R 对于一般的数据粗加工任务非常有用,但需要一段时间才能掌握。可以认为sqldf是我的R”辅助轮子”。
sqldf让你在R数据框上执行SQL查询。来自SAS的人会发现它非常熟悉,任何具有基本SQL技能的人都可以轻松的使用它—sqldf使用SQLite语法。
install.packages("sqldf")
library(sqldf)
sqldf("SELECT
day
, avg(temp) as avg_temp
FROM beaver2
GROUP BY
day;")
# day avg_temp
#1 307 37.57931
#2 308 37.71308
#beavers1 和 beavers2 是R base 自带的两个数据集,记录了两种海狸的体温序列
beavers <- sqldf("select * from beaver1
union all
select * from beaver2;")
#head(beavers)
# day time temp activ
#1 346 840 36.33 0
#2 346 850 36.34 0
#3 346 900 36.35 0
#4 346 910 36.42 0
#5 346 920 36.55 0
#6 346 930 36.69 0
movies <- data.frame(
title=c("The Great Outdoors", "Caddyshack", "Fletch", "Days of Thunder", "Crazy Heart"),
year=c(1988, 1980, 1985, 1990, 2009)
)
boxoffice <- data.frame(
title=c("The Great Outdoors", "Caddyshack", "Fletch", "Days of Thunder","Top Gun"),
revenue=c(43455230, 39846344, 59600000, 157920733, 353816701)
)
sqldf("SELECT
m.*
, b.revenue
FROM
movies m
INNER JOIN
boxoffice b
ON m.title = b.title;")
# title year revenue
#1 The Great Outdoors 1988 43455230
#2 Caddyshack 1980 39846344
#3 Fletch 1985 59600000
#4 Days of Thunder 1990 157920733
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
如果你喜欢sqldf,可以使用pandasql包来查询pandas中的DataFrame,通过SQL。
2. forecast
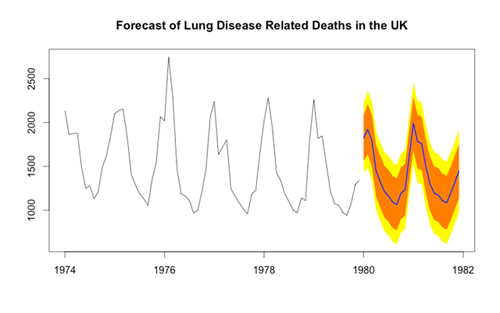
我不经常做时间序列分析,但是当我做的时候forecast包是我的选择。forecast对ARIMA,ARMA,AR,指数平滑等时间序列模型的预测简单的令人难以置信。
install.packages("forecast")
library(forecast)
# mdeaths: 英国每月死于肺病的人数
fit <- auto.arima(mdeaths)
#定制你的置信区间
forecast(fit, level=c(80, 95, 99), h=3)
# Point Forecast Lo 80 Hi 80 Lo 95 Hi 95 Lo 99 Hi 99
#Jan 1980 1822.863 1564.192 2081.534 1427.259 2218.467 1302.952 2342.774
#Feb 1980 1923.190 1635.530 2210.851 1483.251 2363.130 1345.012 2501.368
#Mar 1980 1789.153 1495.048 2083.258 1339.359 2238.947 1198.023 2380.283
plot(forecast(fit), shadecols="oldstyle")
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
我最喜欢的特性是产生预测的时序图。
3. plyr
当我***次使用R时,我用基本的控制运算来操纵数据(for, if, while, etc.)。我很快知道这是一个业余的做法,并且有更好的方法去实现。
在R中,apply函数族是在对列表或者向量每个元素调用函数的***方法。虽然R基础库中有这些函数,但它们的使用可能难以掌握。我发现plyr包 是一个对R基础库中诸如split,apply, combine的泛函的更好用的替代。
plyr 给予你一些函数 (ddply, daply, dlply, adply, ldply)按照常见的蓝图:将数据结构分组拆分,对每个组应用一个函数,将结果返回到数据结构中。
ddply 拆分一个数据框(data frame)并且返回一个数据框 (所以是 dd)。 daply 拆分一个数据框并且返回一个数组(array) (所以是 da)。希望你明白这个想法。
译者注:plyr包包含了12个命名与功能相关的函数,均以..ply命名,***个.表示输入的数据类型(a数组 d数据框 l列表),第二个.表示输出的数据类型(_表示不输出)
install.packages("plyr")
library(plyr)
# 按照 Species 拆分数据库,汇总一下,然后转换结果
# 到数据框
ddply(iris, .(Species), summarise,
mean_petal_length=mean(Petal.Length)
)
# Species mean_petal_length
#1 setosa 1.462
#2 versicolor 4.260
#3 virginica 5.552
# 按照 Species 拆分数据库,汇总一下,然后转换结果
# 到数组
unlist(daply(iris[,4:5], .(Species), colwise(mean)))
# setosa.Petal.Width versicolor.Petal.Width virginica.Petal.Width
# 0.246 1.326 2.026
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
4. stringr
我发现R基础库的字符串功能使用起来非常困难和麻烦。Hadley Wickham编写的另一个包, stringr,提供了一些非常需要的字符串运算符。很多函数使用那些做基础分析时不常用的数据结构。
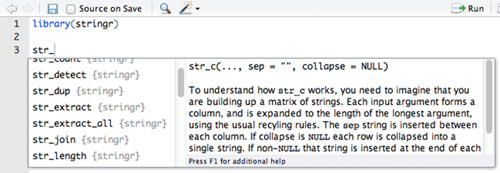
stringr 非常易于使用。几乎所有的(和所有的重要功能)都以”str”为前缀,所以很容易记住。
install.packages("stringr")
library(stringr)
names(iris)
#[1] "Sepal.Length" "Sepal.Width" "Petal.Length" "Petal.Width" "Species"
names(iris) <- str_replace_all(names(iris), "[.]", "_")
names(iris)
#[1] "Sepal_Length" "Sepal_Width" "Petal_Length" "Petal_Width" "Species"
s <- c("Go to Heaven for the climate, Hell for the company.")
str_extract_all(s, "[H][a-z]+ ")
#[[1]]
#[1] "Heaven " "Hell "
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
5. 数据库驱动的包
install.packages("RPostgreSQL")
install.packages("RMySQL")
install.packages("RMongo")
install.packages("RODBC")
install.packages("RSQLite")
- 1.
- 2.
- 3.
- 4.
- 5.
每个人(包括我自己)开始的时候都会这样做。你刚在***的SQL编辑器中写了一个很棒的查询。一切都是***的—列名都是snake case(译者注:表示单词之间用下划线连接。单词要么全部大写,要么全部小写。),日期有正确的数据类型,***调试出了"must appear in the GROUP BY clause or be used in an aggregate function"的问题。你现在准备在R中进行一些分析,因此你可以在SQL编辑器中运行查询,将结果复制到csv(或者……xlsx)并读入R,你并不需要这样做!
R对于几乎每一个可以想到的数据库都有好的驱动。当你在偶尔使用不具有独立驱动程序的数据库(SQL Server)时,你可以随时使用RODBC。
library(RPostgreSQL)
drv <- dbDriver("PostgreSQL")
db <- dbConnect(drv, dbname="ncaa",
user="YOUR USER NAME", password="YOUR PASSWORD")
q <- "SELECT
*
FROM
game_scores;"
data <- dbGetQuery(db, q)
head(data)
#id school game_date spread school_score opponent opp_score was_home
#1 45111 Boston College 1985-11-16 6.0 21 Syracuse 41 False
#2 45112 Boston College 1985-11-02 13.5 12 Penn State 16 False
#3 45113 Boston College 1985-10-26 -11.0 17 Cincinnati 24 False
#4 45114 Boston College 1985-10-12 -2.0 14 Army 45 False
#5 45115 Boston College 1985-09-28 5.0 10 Miami 45 True
#6 45116 Boston College 1985-09-21 6.5 29 Pittsburgh 22 False
nrow(data)
#[1] 30932
ncol(data)
#[1] 8
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
下次你完成了***的查询后,只需要粘贴到R里面,即可使用 RPostgreSQL, RMySQL,RMongo, SQLite, 或 RODBC执行。不仅可以避免生成数以百计的CSV文件,在R中运行查询还可以节省I/O和转换数据类型的时间。日期,时间等会自动设置为R中的等价表示。它还使你的R脚本可重复,因此你或你团队中的其他人可以轻松获得相同的结果。
6. lubridate
在R中处理日期我从来没有幸运过。我从来没有完全掌握用POSIXs和R内建日期类型合作的方法。请用 lubridate。
lubridate 是那些似乎完全按照你期望的神包之一。这些函数都有易懂的名字如 year,month, ymd, 和 ymd_hms。对于熟悉javascript的人来说,它类似于Moment.js 。
install.packages("lubridate")
library(lubridate)
year("2012-12-12")
#[1] 2012
day("2012-12-12")
#[1] 12
ymd("2012-12-12")
#1 按照 %Y-%m-%d 的方式解析
#[1] "2012-12-12 UTC"
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
这是我在一篇文章发现的非常方便的参考卡片。它涵盖了你处理日期时可能想要做的一切事情。 我还发现了这个日期速查表也可以作为一个方便的参考。
7. ggplot2
另一个Hadley Wickham的包,也许是他最知名的一个。 ggplot2在每个人“喜爱的R包”的列表中排名很高。 它很容易使用,并且产生一些很好看的图像。 这是介绍你的工作的好方法,有很多资源可以帮助你开始使用。
- ggplot2:数据分析与图形艺术 by Hadley Wickham (Amazon)
- 从Excel到ggplot的罗塞塔石碑 (Yaksis Blog)
- Hadley Wickham在Google的ggplot2演讲 (youtube)
- R数据可视化手册 by Winston Chang (Amazon)
8. qcc
install.packages("qcc")
library(qcc)
# 均值为10的序列,加上白噪声
x <- rep(10, 100) + rnorm(100)
# 测试序列,均值为11
new.x <- rep(11, 15) + rnorm(15)
# qcc 会标记出新的点
qcc(x, newdata=new.x, type="xbar.one")
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
qcc 是用于 统计质量控制的库。 早在上世纪五十年代,现已不复存在的西方电气公司正在寻找一种更好检测电话线和电线问题的方法。他们提出了一系列 规则 来帮助识别有问题的线。规则观察一系列数据点的历史平均值,并且基于标准差的偏差,该规则有助于判断一组新的点是否经历均值漂移。
典型的例子是监控生产 螺母的机器。假设机器应该生产2.5英寸长的螺母。我们测量一系列的螺母: 2.48, 2.47, 2.51, 2.52, 2.54, 2.42, 2.52, 2.58, 2.51。机器出故障了吗?很难说,但上述规则可以帮助描述。
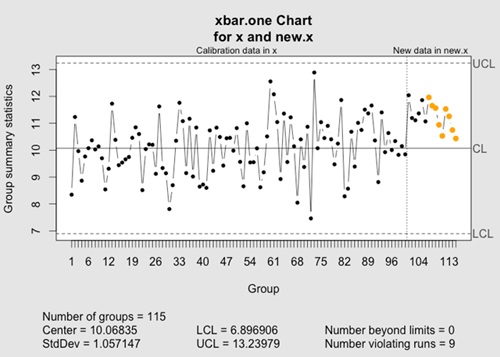
虽然你可能不会监控电话线,qcc可帮你监控你网站的交易量,数据库的访问者或者登录名,以及其他许多流程。
9. reshape2
我经常发现,任何分析中最难的部分是把数据转化成正确的格式。 reshape2 正是Hadley Wickham的另一个软件包,专门用于 “宽”数据表 和“窄”数据表 的转换。我一般会和ggplot2 及 plyr一起使用它。
install.packages("reshape2")
library(reshape2)
# 为每一行生成唯一的ID; 这样我们可以稍后转回到宽格式
iris$id <- 1:nrow(iris)
iris.lng <- melt(iris, id=c("id", "Species"))
head(iris.lng)
# id Species variable value
#1 1 setosa Sepal.Length 5.1
#2 2 setosa Sepal.Length 4.9
#3 3 setosa Sepal.Length 4.7
#4 4 setosa Sepal.Length 4.6
#5 5 setosa Sepal.Length 5.0
#6 6 setosa Sepal.Length 5.4
iris.wide <- dcast(iris.lng, id + Species ~ variable)
head(iris.wide)
# id Species Sepal.Length Sepal.Width Petal.Length Petal.Width
#1 1 setosa 5.1 3.5 1.4 0.2
#2 2 setosa 4.9 3.0 1.4 0.2
#3 3 setosa 4.7 3.2 1.3 0.2
#4 4 setosa 4.6 3.1 1.5 0.2
#5 5 setosa 5.0 3.6 1.4 0.2
#6 6 setosa 5.4 3.9 1.7 0.4
library(ggplot2)
# 为数据集中每个数值列绘制直方图
p <- ggplot(aes(x=value, fill=Species), data=iris.lng)
p + geom_histogram() +
facet_wrap(~variable, scales="free")
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
这是一个快速查看数据集并且获得转接的方法。你可以使用 melt 函数将宽数据转换为窄数据, 使用 dcast 将窄数据转换为宽数据。
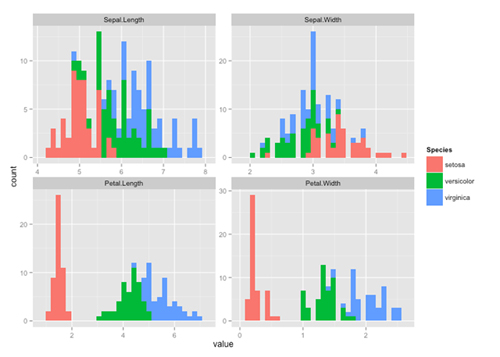
10. randomForest
如果这个列表不包括至少一个能你的朋友震惊的机器学习包就不会完整。随机森林 是一个很好的算法。它很容易使用,可以进行监督学习或者无监督学习,它可以与许多不同类型的数据集一起使用,但最重要的是它的高效率!这是它在R中的使用方法。
install.packages("randomForest")
library(randomForest)
# 下载泰坦尼克号幸存者数据集
data <- read.table("http://math.ucdenver.edu/RTutorial/titanic.txt", h=T, sep="\t")
# 将Survived列转为yes/no因子
data$Survived <- as.factor(ifelse(data$Survived==1, "yes", "no"))
# 拆分为训练集和测试集
idx <- runif(nrow(data)) <= .75
data.train <- data[idx,]
data.test <- data[-idx,]
# 训练一个随机森林
rf <- randomForest(Survived ~ PClass + Age + Sex,
data=data.train, importance=TRUE, na.action=na.omit)
# 模型中每个变量的重要程度
imp <- importance(rf)
o <- order(imp[,3], decreasing=T)
imp[o,]
# no yes MeanDecreaseAccuracy MeanDecreaseGini
#Sex 51.49855 53.30255 55.13458 63.46861
#PClass 25.48715 24.12522 28.43298 22.31789
#Age 20.08571 14.07954 24.64607 19.57423
# 混淆矩阵 [[真反例, 假正例], [假反例, 正正例]]
table(data.test$Survived, predict(rf, data.test), dnn=list("actual", "predicted"))
# predicted
#actual no yes
# no 427 16
# yes 117 195
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.