什么是hiriver?
hiriver是纯java开发的、高性能的、基于解析mysql row base binlog技术实现的用于监控mysql数据变化并分发这些变化的框架。它提供了一套完整的框架,内置数据监控线程和数据消费线程,对外提供简单的Consumer接口,开发者可以根据自己的业务场景自行实现Consumer接口,而不不必关心线程问题。
实现原理
hiriver实现了mysql主从复制协议,把自己伪装成一个mysql的从库,在接收到binlog后按照mysql binlog协议进行解析,由此获取mysql的数据变化。由于基于mysql的主从复制协议,它监控数据变化特别快,理论上与mysql本身的主从同步一样快,甚至更快。同时与在应用层监控数据变化不同,它不需要考虑事务是否成功问题。当然,***限制***是mysql binlog的方式必须是***row***方式。
名字的由来
hiriver是hidden river的简称,中文名称”暗渠”,用于隐喻在数据库的后面导流数据,而不必要在应用层做任何控制。
支持mysql的版本
hiriver支持mysql 5.6.9+和 mysql5.1+版本。
- 强烈推荐 使用5.6.9+版本,并使用binlog file name + position的方式处理同步点。
- 虽然5.6.9+版本提供 gtid 功能,它是用于表示事务的唯一的id,理论上,基于它可以实现HA功能,当mysql出现故障时可以自动从一台mysql从库切换到另一台,并且不会丢失或者重复数据, 但是 在实际的使用过程中gtid依然存在bug,并不稳定,而且存在多个gtid时很难找到mysql认识的初始同步点。
- mysql5.6.9之前的版本,必须binlog file name和在该文件中的偏移位置作为同步点。
javadoc
使用教程
quickstart
总体说明
- hiriver模块组主要由2个组件和一个示例组成:mysql-proto、hiriver和hiriver-sample
- mysql-proto实现了mysql的client-server协议,包括Text protocol和主从复制协议。Text protocol是从mysql 正常 读取数据的协议,它是mysql jdbc驱动背后的协议。主从复制协议顾名思义就是实现主从之间复制数据的协议。
- hiriver是基于mysql-proto组件封装的监听mysql变化、记录同步点、控制数据消费的上层应用框架。它是hiriver业务流程的实现。它需要与spirng集成使用
- hiriver-sample一个使用hirvier的示例
准备数据库环境
1.创建自己的mysql 5.6.28
2.开启row base和gtid 模式(如果使用gtid作为同步点,必须开启)
- log-bin=mysql-bin
- binlog_format=Row
- log-slave-updates=ON
- enforce_gtid_consistency=true
- gtid_mode=ON
3.创建自己的复制账号,创建repl database和一张表,并在表示写入数据
快速使用-binlogname + 偏移地址模式
1.下载代码,找到hiriver-sample模块,它是一个基于spring的web应用,有3 spring xml配置文件,分别是:
- spring-boot.xml # spring容器描述入口文件
- spring-bin.xml # binlogname + 偏移地址模式
- spring-gtid.xml # gtid模式
2.修改示例中hiriver-sample.properties的参数,修改数据库相关属性、初始同步点、同步点存储路径和表名过滤黑、白名单配置
3.初始化同步点使用channel.0000.binlog和channel.0000.binlog.pos属性,可以通过执行
- show master status
命令获取对应信息

修改后如图:

4.修改spring-boot.xml中的***一行为:
- <import resource="classpath:spring/spring-binlog.xml"/>
5.使用tomcat/jetty或maven jetty插件运行示例即可
快速使用-gtid模式
下载代码,找到hiriver-sample模块,它是一个基于spring的web应用,有3 spring xml配置文件,分别是:
- spring-boot.xml # spring容器描述入口文件
- spring-bin.xml # binlogname + 偏移地址模式
- spring-gtid.xml # gtid模式
2.修改示例中hiriver-sample.properties的参数,修改数据库相关属性、初始同步点、同步点存储路径和表名过滤黑、白名单配置,其中channel_0000.gtid参数的配置需要从mysql中查询数获取,执行
- show master status
命令,得到如下结果:

这是一个范围,你只需要使用
- 8c80613e-ac5b-11e5-b170-148044d6636f:1 or 8c80613e-ac5b-11e5-b170-148044d6636f:8
即可.修改后如图:

修改spring-boot.xml中的***一行为: <import resource="classpath:spring/spring-gtid.xml"/>
使用tomcat/jetty或maven jetty插件运行示例即可
详细参数说明
底层socket控制参数(使用TransportConfig类描述)
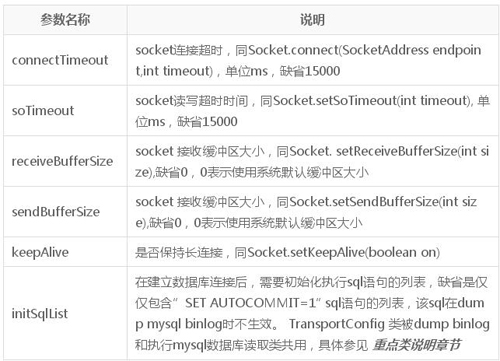
binlog读取参数(DefaultChannelStream类)
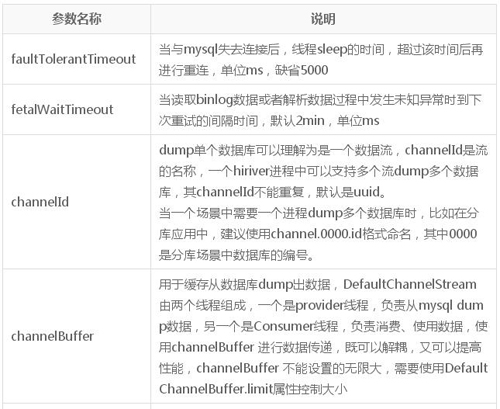
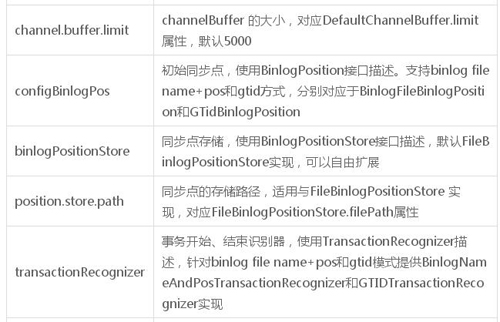
数据库配置


重点类说明
底层通信类
binlog dump类(BinlogStreamBlockingTransportImpl)
实现mysql binlog dump协议,负责与mysql建立socket连接,完成用户名密码验证后,执行数据dump命令,并持续的读取、解析mysql binlog event数据。
数据库数据读取类(TextProtocolBlockingTransportImpl)
mysql文本协议的实现,mysql文本协议即jdbc背后的协议,主要用于执行sql读取数据,也可以执行一些其他的命令,比如读取表定义的元数据等,之所以不使用mysql jdbc是由于两个原因:一是不想引入一个第三方包,降低依赖性;二是mysql的文本协议支持更多指令,比如COM_FIELD_LIST指令方便的获取到表字段是否为空、是否是索引字段等信息,而jdbc是个通用的api,并没有暴露这些指令实现。
表名过滤类 (BlackWhiteNameListTableFilter)
支持黑白名单的过滤实现。 按照表名进行过滤时,表名格式为database.table(可以为正则),以逗号分隔.
当白名单和黑名单同时存在时,只有不在黑名单中同时在白名单中存在的才起作用.
e.g,在properties文件中描述
白名单:filert_white=test.account,test.user_sharding*
白名单:filert_black=test.*bak
binlog row event数据描述类(BinlogDataSet)
binlog数据是二进制数据,它遵循mysql rowbase binlog协议,在协议内部event作为一个基本单位用于描述数据库的变更,这里的“变更”不仅仅是数据的修改,也可能是事务的开启、结束,表的变更等,在hiriver里我们仅仅关注表数据的变更,BinlogDataSet用于描述一条或多条数据的变化,类似于jdbc的RowSet。BinlogDataSet 包括:
- channelId
- sourceHostUrl,该数据来自哪个数据库
- gtId, 该数据所在的事务的gtid,在不支持gtid模式下,为null
- binlogPos, 当前数据所在事务的binlogfile + pos,无论哪种模式,一定补位null
- isStartTransEvent, 当前是否一个事务的开启
- isPositionStoreTrigger,当前是否一个事务的结束,当时true时需要记录同步点。
- rowDataMap, 行数据,每一行使用BinlogResultRow描述
- columnDefMap, 类定义描述
BinlogResultRow内部是有二个列表,一个记录变更之前的数据,另一个记录变更之后的数据。
数据消费类 (Consumer)
描述消费BinlogDataSet数据的接口,这个留给业务实现方来实现。
binlog流(DefaultChannelStream)
mysql binlog dump被抽象成一个流,每一个流仅仅针对一个mysql实例,这个流称之为ChannelStream, ChannelStream负责源源不断的从mysql实例读取数据并过滤、解析和消费。
DefaultChannelStream是ChannelStream的缺省实现,在内部它开启了2条线程:provider和consumer线程,provider线程负责从数据库读取数据,识别事务、根据表名过滤、解析成BinlogDataSet并放入ChannelBuffer;consumer线程负责从ChannelBuffer读取数据并调用Consumer进行数据消费。
当provider线程产生数据的速度大于consumer线程消费数据的速度时,数据会被积压在ChannelBuffer中,为了防止内存被打爆,ChannelBuffer需要实现成有界的,当ChannelBuffer达到上限时会阻塞provider线程产生新数据。
数据缓存类 (DefaultChannelBuffer)
ChannelStream中provider和consumer线程的数据通信基础,它是ChannelBuffer的缺省实现。谨记,需要配置上限。
事务识别类(TransactionRecognizer)
用于识别事务的开启、结束,并且记录当前事务的开始位置。针对gtid和binlog file name + pos两种模式,提供2种实现:GTIDTransactionRecognizer和BinlogNameAndPosTransactionRecognizer。