本文结构:
- 什么是命名实体识别(NER)
- 怎么识别?
cs224d Day 7: 项目2-用DNN处理NER问题
什么是NER?
命名实体识别(NER)是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等。命名实体识别是信息提取、问答系统、句法分析、机器翻译等应用领域的重要基础工具,作为结构化信息提取的重要步骤。摘自 BosonNLP
怎么识别?
先把解决问题的逻辑说一下,然后解释主要的代码,有兴趣的话,完整代码请去 这里看 。
代码是在 Tensorflow 下建立只有一个隐藏层的 DNN 来处理 NER 问题。
1.问题识别:
NER 是个分类问题。
给一个单词,我们需要根据上下文判断,它属于下面四类的哪一个,如果都不属于,则类别为0,即不是实体,所以这是一个需要分成 5 类的问题:
- • Person (PER)
- • Organization (ORG)
- • Location (LOC)
- • Miscellaneous (MISC)
我们的训练数据有两列,***列是单词,第二列是标签。
- EU ORG
- rejects O
- German MISC
- Peter PER
- BRUSSELS LOC
2.模型:
接下来我们用深度神经网络对其进行训练。
模型如下:
输入层的 x^(t) 为以 x_t 为中心的窗口大小为3的上下文语境,x_t 是 one-hot 向量,x_t 与 L 作用后就是相应的词向量,词向量的长度为 d = 50 :
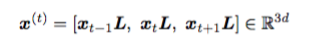
我们建立一个只有一个隐藏层的神经网络,隐藏层维度是 100,y^ 就是得到的预测值,维度是 5:
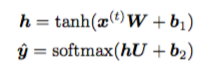
用交叉熵来计算误差:
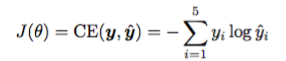
J 对各个参数进行求导:
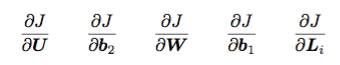
得到如下求导公式:
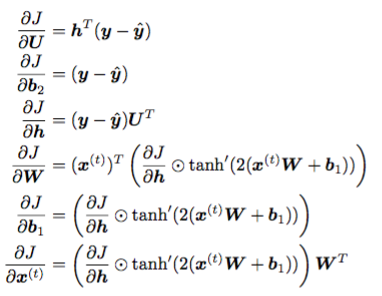
在 TensorFlow 中求导是自动实现的,这里用Adam优化算法更新梯度,不断地迭代,使得loss越来越小直至收敛。
3.具体实现
在 def test_NER() 中,我们进行 max_epochs 次迭代,每次,用 training data 训练模型 得到一对 train_loss, train_acc ,再用这个模型去预测 validation data,得到一对 val_loss, predictions ,我们选择最小的 val_loss ,并把相应的参数 weights 保存起来,***我们是要用这些参数去预测 test data 的类别标签:
- def test_NER():
- config = Config()
- with tf.Graph().as_default():
- model = NERModel(config) # 最主要的类
- init = tf.initialize_all_variables()
- saver = tf.train.Saver()
- with tf.Session() as session:
- best_val_loss = float('inf') # ***的值时,它的 loss 它的 迭代次数 epoch
- best_val_epoch = 0
- session.run(init)
- for epoch in xrange(config.max_epochs):
- print 'Epoch {}'.format(epoch)
- start = time.time()
- ###
- train_loss, train_acc = model.run_epoch(session, model.X_train,
- model.y_train) # 1.把 train 数据放进迭代里跑,得到 loss 和 accuracy
- val_loss, predictions = model.predict(session, model.X_dev, model.y_dev) # 2.用这个model去预测 dev 数据,得到loss 和 prediction
- print 'Training loss: {}'.format(train_loss)
- print 'Training acc: {}'.format(train_acc)
- print 'Validation loss: {}'.format(val_loss)
- if val_loss < best_val_loss: # 用 val 数据的loss去找最小的loss
- best_val_loss = val_loss
- best_val_epoch = epoch
- if not os.path.exists("./weights"):
- os.makedirs("./weights")
- saver.save(session, './weights/ner.weights') # 把最小的 loss 对应的 weights 保存起来
- if epoch - best_val_epoch > config.early_stopping:
- break
- ###
- confusion = calculate_confusion(config, predictions, model.y_dev) # 3.把 dev 的lable数据放进去,计算prediction的confusion
- print_confusion(confusion, model.num_to_tag)
- print 'Total time: {}'.format(time.time() - start)
- saver.restore(session, './weights/ner.weights') # 再次加载保存过的 weights,用 test 数据做预测,得到预测结果
- print 'Test'
- print '=-=-='
- print 'Writing predictions to q2_test.predicted'
- _, predictions = model.predict(session, model.X_test, model.y_test)
- save_predictions(predictions, "q2_test.predicted") # 把预测结果保存起来
- if __name__ == "__main__":
- test_NER()
4.模型是怎么训练的呢?
首先导入数据 training,validation,test:
- # Load the training set
- docs = du.load_dataset('data/ner/train')
- # Load the dev set (for tuning hyperparameters)
- docs = du.load_dataset('data/ner/dev')
- # Load the test set (dummy labels only)
- docs = du.load_dataset('data/ner/test.masked')
把单词转化成 one-hot 向量后,再转化成词向量:
- def add_embedding(self):
- # The embedding lookup is currently only implemented for the CPU
- with tf.device('/cpu:0'):
- embedding = tf.get_variable('Embedding', [len(self.wv), self.config.embed_size]) # assignment 中的 L
- window = tf.nn.embedding_lookup(embedding, self.input_placeholder) # 在 L 中直接把window大小的context的word vector搞定
- window = tf.reshape(
- window, [-1, self.config.window_size * self.config.embed_size])
- return window
建立神经层,包括用 xavier 去初始化***层, L2 正则化和用 dropout 来减小过拟合的处理:
- def add_model(self, window):
- with tf.variable_scope('Layer1', initializer=xavier_weight_init()) as scope: # 用initializer=xavier去初始化***层
- W = tf.get_variable( # ***层有 W,b1,h
- 'W', [self.config.window_size * self.config.embed_size,
- self.config.hidden_size])
- b1 = tf.get_variable('b1', [self.config.hidden_size])
- h = tf.nn.tanh(tf.matmul(window, W) + b1)
- if self.config.l2: # L2 regularization for W
- tf.add_to_collection('total_loss', 0.5 * self.config.l2 * tf.nn.l2_loss(W)) # 0.5 * self.config.l2 * tf.nn.l2_loss(W)
- with tf.variable_scope('Layer2', initializer=xavier_weight_init()) as scope:
- U = tf.get_variable('U', [self.config.hidden_size, self.config.label_size])
- b2 = tf.get_variable('b2', [self.config.label_size])
- y = tf.matmul(h, U) + b2
- if self.config.l2:
- tf.add_to_collection('total_loss', 0.5 * self.config.l2 * tf.nn.l2_loss(U))
- output = tf.nn.dropout(y, self.dropout_placeholder) # 返回 output,两个variable_scope都带dropout
- return output
关于 L2正则化 和 dropout 是什么, 如何减小过拟合问题的,可以看 这篇博客,总结的简单明了。
用 cross entropy 来计算 loss:
- def add_loss_op(self, y):
- cross_entropy = tf.reduce_mean( # 1.关键步骤:loss是用cross entropy定义的
- tf.nn.softmax_cross_entropy_with_logits(y, self.labels_placeholder)) # y是模型预测值,计算cross entropy
- tf.add_to_collection('total_loss', cross_entropy) # Stores value in the collection with the given name.
- # collections are not sets, it is possible to add a value to a collection several times.
- loss = tf.add_n(tf.get_collection('total_loss')) # Adds all input tensors element-wise. inputs: A list of Tensor with same shape and type
- return loss
接着用 Adam Optimizer 把loss最小化:
- def add_training_op(self, loss):
- optimizer = tf.train.AdamOptimizer(self.config.lr)
- global_step = tf.Variable(0, name='global_step', trainable=False)
- train_op = optimizer.minimize(loss, global_step=global_step) # 2.关键步骤:用 AdamOptimizer 使 loss 达到最小,所以更关键的是 loss
- return train_op
每一次训练后,得到了最小化 loss 相应的 weights。
这样,NER 这个分类问题就搞定了,当然为了提高精度等其他问题,还是需要查阅文献来学习的。下一次先实现个 RNN。