在从事深度学习过程中, 如果我们想训练一个类别非常多的分类器 (比如一个拥有巨大词汇库的语言模型), 正常的训练过程将非常缓慢。这是由于在训练过程中,所有的类别都需要进行评估。为了解决这个问题,人们发明了候选采样的技巧,每次只评估所有类别的一个很小的子集。深度学习库 TensorFlow (TF) 实现了候选采样技巧, 并提供了一些 API。

1. 候选采样函数
候选采样函数,从巨大的类别库中,按照一定原则,随机采样出类别子集。TF 提供下面几个候选采样函数, 其中前面三个的参数和返回值是一致的,第四个也很类似。具体参数和返回值可以移步 TF 文档。
(1) tf.nn.uniform_candidate_sampler
均匀地采样出类别子集。
(2) tf.nn.log_uniform_candidate_sampler
按照 log-uniform (Zipfian) 分布采样。
![]()
这个函数主要用于处理词作类别的情况。在语言学中,词按照出现频率从大到小排序之后,服从 Zipfian 分布。在使用这个函数之前,需要对类别按照出现频率从大到小排序。
(3) tf.nn.learned_unigram_candidate_sampler
按照训练数据中类别出现分布进行采样。具体实现方式:1)初始化一个 [0, range_max] 的数组, 数组元素初始为1; 2) 在训练过程中碰到一个类别,就将相应数组元素加 1;3) 每次按照数组归一化得到的概率进行采样。
(4) tf.nn.fixed_unigram_candidate_sampler
按照用户提供的概率分布进行采样。
如果类别服从均匀分布,我们就用uniform_candidate_sampler;如果词作类别,我们知道词服从 Zipfian, 我们就用 log_uniform_candidate_sampler; 如果我们能够通过统计或者其他渠道知道类别满足某些分布,我们就用 nn.fixed_unigram_candidate_sampler; 如果我们实在不知道类别分布,我们还可以用 tf.nn.learned_unigram_candidate_sampler。
其实我蛮好奇 tf 内部怎么实现快速采样的,特别是
tf.nn.learned_unigram_candidate_sampler 概率分布在变的情况下,我知道最快的采样算法也是 O(n) 的。不知道 tf 有没有更快的算法。
2. 候选采样损失函数
候选采样函数生成类别子集。类别子集需要送给候选采样损失函数计算损失,最小化候选采样损失便能训练模型。TF 提供下面两个候选采样损失函数。这两个采样损失函数的参数和返回值是一致的, 具体参数和返回值可以移步 TF 文档。
(1) tf.nn.sampled_softmax_loss
这个函数通过 模型的交叉熵损失。候选类别子集由采样类别 和真实类别 组成,即 。模型***一层输出是 , 经过 softmax 激活函数转成模型输出的概率 , 得 。
因为只有候选类别子集 , 没有类别全集 L,我们无法计算 ,进而计算交叉熵损失。通过候选类别子集,我们只能计算 。那么怎么优化 相关的损失函数,得到 呢?我们有。
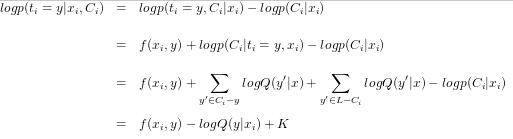
其中 K 是和 y 无关的数。我们得到概率计算公式和交叉熵损失。
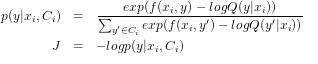
最小化 J 训练模型。
(2) tf.nn.nce_loss
NCE Loss 和 Sampled Softmax Loss 的出发点是一致, 都是想使得模型输出 。它们的不同点在于 Sampled Softmax Loss 只支持 Single-Label 分类,而 NCE 支持 Multi-Label 分类。候选类别子集 由采样类别 和真实类别 组成,即 。对于候选类别子集中的每一个类别,都建立一个 Logistic 二分类问题,其损失函数为
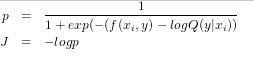
最小化 J 训练模型。
3. 候选采样限制
很多时候, 负类别由问题给定。比如我们训练分类器玩斗地主扑克, 下面几个性质:
- 斗地主中所有可能的出牌动作非常多;
- 对于一副牌局, 所有可选动作至多只有几百个;
- 对于一副牌局, 我们选择人类高手出牌动作为正类别,我们将人类高手没有选择的出牌动作作为负样本;
- 按照当前牌局构建出的训练样本, 正类别只有一个, 负类别至多几百个而且由当前牌局决定。
在上述问题中, 不同牌局的候选动作的个数不一样, 我们无法使用候选采样的方法进行训练。候选采样只能采样出相同个数的类别。一方面 TF 的基本单元是 Tensor, 要求各个维度一致。另一方面是由于候选采样为了 Word2Vec 中的 Negative sampling 等场景设计, 这些场景只需要挑选一些负类别反映非正类别的特性。
4. 总结
候选采样加速了类别数量巨大的训练过程。TF 提供了候选采样相关 API,方便人们使用。
【本文为51CTO专栏作者“李立”的原创稿件,转载请通过51CTO获取联系和授权】