也许你已经下载了TensorFlow,而且准备开始着手研究深度学习。但是你会疑惑:TensorFlow里面的Tensor,也就是“张量”,到底是个什么鬼?也许你查阅了维基百科,而且现在变得更加困惑。也许你在NASA教程中看到它,仍然不知道它在说些什么?问题在于大多数讲述张量的指南,都假设你已经掌握他们描述数学的所有术语。
别担心!
我像小孩子一样讨厌数学,所以如果我能明白,你也可以!我们只需要用简单的措辞来解释这一切。所以,张量(Tensor)是什么,而且为什么会流动(Flow)?
让我们先来看看tensor(张量)是什么?
张量=容器
张量是现代机器学习的基础。它的核心是一个数据容器,多数情况下,它包含数字,有时候它也包含字符串,但这种情况比较少。因此把它想象成一个数字的水桶。
张量有多种形式,首先让我们来看最基本的形式,你会在深度学习中偶然遇到,它们在0维到5维之间。我们可以把张量的各种类型看作这样(对被题目中的猫咪吸引进来小伙伴说一句,不要急!猫咪在后面会出现哦!):

0维张量/标量
装在张量/容器水桶中的每个数字称为“标量”。
标量是一个数字。
你会问为什么不干脆叫它们一个数字呢?
我不知道,也许数学家只是喜欢听起来酷?标量听起来确实比数字酷。
实际上,你可以使用一个数字的张量,我们称为0维张量,也就是一个只有0维的张量。它仅仅只是带有一个数字的水桶。想象水桶里只有一滴水,那就是一个0维张量。
本教程中,我将使用Python,Keras,TensorFlow和Python库Numpy。在Python中,张量通常存储在Nunpy数组,Numpy是在大部分的AI框架中,一个使用频率非常高的用于科学计算的数据包。

你将在Kaggle(数据科学竞赛网站)上经常看到Jupyter Notebooks(安装见文末阅读链接,“数学烂也要学AI:带你造一个经济试用版AI终极必杀器”)关于把数据转变成Numpy数组。Jupyter notebooks本质上是由工作代码标记嵌入。可以认为它把解释和程序融为一体。
我们为什么想把数据转换为Numpy数组?
很简单。因为我们需要把所有的输入数据,如字符串文本,图像,股票价格,或者视频,转变为一个统一得标准,以便能够容易的处理。
这样我们把数据转变成数字的水桶,我们就能用TensorFlow处理。
它仅仅是组织数据成为可用的格式。在网页程序中,你也许通过XML表示,所以你可以定义它们的特征并快速操作。同样,在深度学习中,我们使用张量水桶作为基本的乐高积木。
1维张量/向量
如果你是名程序员,那么你已经了解,类似于1维张量:数组。
每个编程语言都有数组,它只是单列或者单行的一组数据块。在深度学习中称为1维张量。张量是根据一共具有多少坐标轴来定义。1维张量只有一个坐标轴。
1维张量称为“向量”。
我们可以把向量视为一个单列或者单行的数字。

如果想在Numpy得出此结果,按照如下方法:

我们可以通过NumPy’s ndim函数,查看张量具有多个坐标轴。我们可以尝试1维张量。

2维张量
你可能已经知道了另一种形式的张量,矩阵——2维张量称为矩阵

不,这不是基努·里维斯(Keanu Reeves)的电影《黑客帝国》,想象一个excel表格。
我们可以把它看作为一个带有行和列的数字网格。
这个行和列表示两个坐标轴,一个矩阵是二维张量,意思是有两维,也就是有两个坐标轴的张量。
在Numpy中,我们可以如下表示:
- x = np.array([[5,10,15,30,25],
- [20,30,65,70,90],
- [7,80,95,20,30]])
我们可以把人的特征存储在一个二维张量。有一个典型的例子是邮件列表。
比如我们有10000人,我们有每个人的如下特性和特征:
- First Name(名)
- Last Name(姓)
- Street Address(街道地址)
- City(城市)
- State(州/省)
- Country(国家)
- Zip(邮政编码)
这意味着我们有10000人的七个特征。
张量具有“形状”,它的形状是一个水桶,即装着我们的数据也定义了张量的最大尺寸。我们可以把所有人的数据放进二维张量中,它是(10000,7)。
你也许想说它有10000列,7行。
不。
张量能够被转换和操作,从而使列变为行或者行变为列。
3维张量
这时张量真正开始变得有用,我们经常需要把一系列的二维张量存储在水桶中,这就形成了3维张量。
在NumPy中,我们可以表示如下:
- x = np.array([[[5,10,15,30,25],
- [20,30,65,70,90],
- [7,80,95,20,30]]
- [[3,0,5,0,45],
- [12,-2,6,7,90],
- [18,-9,95,120,30]]
- [[17,13,25,30,15],
- [23,36,9,7,80],
- [1,-7,-5,22,3]]])
你已经猜到,一个三维张量有三个坐标轴,可以这样看到:
- x.ndim
输出为:
- 3
让我们再看一下上面的邮件列表,现在我们有10个邮件列表,我们将存储2维张量在另一个水桶里,创建一个3维张量,它的形状如下:
- (number_of_mailing_lists, number_of_people, number_of_characteristics_per_person)
- (10,10000,7)
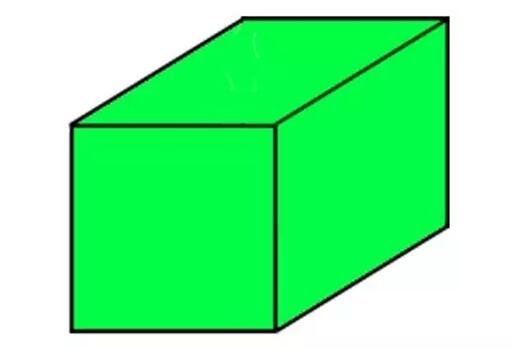
你也许已经猜到它,但是一个3维张量是一个数字构成的立方体。
我们可以继续堆叠立方体,创建一个越来越大的张量,来编辑不同类型的数据,也就是4维张量,5维张量等等,直到N维张量。N是数学家定义的未知数,它是一直持续到无穷集合里的附加单位。它可以是5,10或者无穷。
实际上,3维张量最好视为一层网格,看起来有点像下图:

存储在张量数据中的公式
这里有一些存储在各种类型张量的公用数据集类型:
- 3维=时间序列
- 4维=图像
- 5维=视频
几乎所有的这些张量的共同之处是样本量。样本量是集合中元素的数量,它可以是一些图像,一些视频,一些文件或者一些推特。
通常,真实的数据至少是一个数据量。
把形状里不同维数看作字段。我们找到一个字段的最小值来描述数据。
因此,即使4维张量通常存储图像,那是因为样本量占据张量的第4个字段。
例如,一个图像可以用三个字段表示:
- (width, height, color_depth) = 3D
但是,在机器学习工作中,我们经常要处理不止一张图片或一篇文档——我们要处理一个集合。我们可能有10,000张郁金香的图片,这意味着,我们将用到4D张量,就像这样:

- (sample_size, width, height, color_depth) = 4D
我们来看看一些多维张量存储模型的例子:
时间序列数据
用3D张量来模拟时间序列会非常有效!
医学扫描——我们可以将脑电波(EEG)信号编码成3D张量,因为它可以由这三个参数来描述:
- (time, frequency, channel)
这种转化看起来就像这样:
如果我们有多个病人的脑电波扫描图,那就形成了一个4D张量:
- (sample_size, time, frequency, channel)
- Stock Prices
在交易中,股票每分钟有最高、最低和最终价格。如下图的蜡烛图所示:
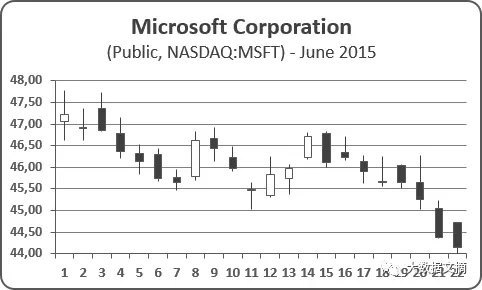
纽交所开市时间从早上9:30到下午4:00,即6.5个小时,总共有6.5 x 60 = 390分钟。如此,我们可以将每分钟内最高、最低和最终的股价存入一个2D张量(390,3)。如果我们追踪一周(五天)的交易,我们将得到这么一个3D张量:
- (week_of_data, minutes, high_low_price)
即:
- (5,390,3)
同理,如果我们观测10只不同的股票,观测一周,我们将得到一个4D张量
- (10,5,390,3)
假设我们在观测一个由25只股票组成的共同基金,其中的每只股票由我们的4D张量来表示。那么,这个共同基金可以有一个5D张量来表示:
- (25,10,5,390,3)
文本数据
我们也可以用3D张量来存储文本数据,我们来看看推特的例子。
首先,推特有140个字的限制。其次,推特使用UTF-8编码标准,这种编码标准能表示百万种字符,但实际上我们只对前128个字符感兴趣,因为他们与ASCII码相同。所以,一篇推特文可以包装成一个2D向量:
- (140,128)
如果我们下载了一百万篇川普哥的推文(印象中他一周就能推这么多),我们就会用3D张量来存:
- (number_of_tweets_captured, tweet, character)
这意味着,我们的川普推文集合看起来会是这样:
- (1000000,140,128)
图片
4D张量很适合用来存诸如JPEG这样的图片文件。之前我们提到过,一张图片有三个参数:高度、宽度和颜色深度。一张图片是3D张量,一个图片集则是4D,第四维是样本大小。
著名的MNIST数据集是一个手写的数字序列,作为一个图像识别问题,曾在几十年间困扰许多数据科学家。现在,计算机能以99%或更高的准确率解决这个问题。即便如此,这个数据集仍可以当做一个优秀的校验基准,用来测试新的机器学习算法应用,或是用来自己做实验。

Keras 甚至能用以下语句帮助我们自动导入MNIST数据集:
- from keras.datasets import mnist
- (train_images, train_labels), (test_images, test_labels) = mnist.load_data()
这个数据集被分成两个部分:训练集和测试集。数据集中的每张图片都有一个标签。这个标签写有正确的读数,例如3,7或是9,这些标签都是通过人工判断并填写的。
训练集是用来训练神经网络学习算法,测试集则用来校验这个学习算法。
MNIST图片是黑白的,这意味着它们可以用2D张量来编码,但我们习惯于将所有的图片用3D张量来编码,多出来的第三个维度代表了图片的颜色深度。
MNIST数据集有60,000张图片,它们都是28 x 28像素,它们的颜色深度为1,即只有灰度。
TensorFlow这样存储图片数据:
- (sample_size, height, width, color_depth).
于是我们可以认为,MNIST数据集的4D张量是这样的:
- (60000,28,28,1)
彩色图片
彩色图片有不同的颜色深度,这取决于它们的色彩(注:跟分辨率没有关系)编码。一张典型的JPG图片使用RGB编码,于是它的颜色深度为3,分别代表红、绿、蓝。
这是一张我美丽无边的猫咪(Dove)的照片,750 x750像素,这意味着我们能用一个3D张量来表示它:
- (750,750,3)

My beautiful cat Dove (750 x 750 pixels)
这样,我可爱的Dove将被简化为一串冷冰冰的数字,就好像它变形或流动起来了。

然后,如果我们有一大堆不同类型的猫咪图片(虽然都没有Dove美),也许是100,000张吧,不是DOVE它的,750 x750像素的。我们可以在Keras中用4D张量来这样定义:
- (10000,750,750,3)
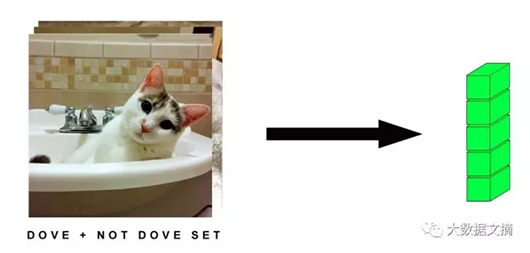
5D张量
5D张量可以用来存储视频数据。TensorFlow中,视频数据将如此编码:
- (sample_size, frames, width, height, color_depth)
如果我们考察一段5分钟(300秒),1080pHD(1920 x 1080像素),每秒15帧(总共4500帧),颜色深度为3的视频,我们可以用4D张量来存储它:
- (4500,1920,1080,3)
当我们有多段视频的时候,张量中的第五个维度将被使用。如果我们有10段这样的视频,我们将得到一个5D张量:
- (10,4500,1920,1080,3)
实际上这个例子太疯狂了!
这个张量的大是很荒谬的,超过1TB。我们姑且考虑下这个例子以便说明一个问题:在现实世界中,我们有时需要尽可能的缩小样本数据以方便的进行处理计算,除非你有无尽的时间。
这个5D张量中值的数量为:
10 x 4500 x 1920 x 1080 x 3 = 279,936,000,000
在Keras中,我们可以用一个叫dype的数据类型来存储32bits或64bits的浮点数
我们5D张量中的每一个值都将用32 bit来存储,现在,我们以TB为单位来进行转换:
279,936,000,000 x 32 = 8,957,952,000,000
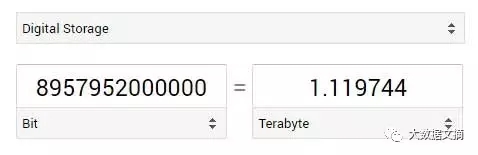
这还只是保守估计,或许用32bit来储存根本就不够(谁来计算一下如果用64bit来存储会怎样),所以,减小你的样本吧朋友。
事实上,我举出这最后一个疯狂的例子是有特殊目的的。我们刚学过数据预处理和数据压缩。你不能什么工作也不做就把大堆数据扔向你的AI模型。你必须清洗和缩减那些数据让后续工作更简洁更高效。
降低分辨率,去掉不必要的数据(也就是去重处理),这大大缩减了帧数,等等这也是数据科学家的工作。如果你不能很好地对数据做这些预处理,那么你几乎做不了任何有意义的事。
结论
好了,现在你已经对张量和用张量如何对接不同类型数据有了更好的了解。
原文:https://hackernoon.com/learning-ai-if-you-suck-at-math-p4-tensors-illustrated-with-cats-27f0002c9b32
【本文是51CTO专栏机构大数据文摘的原创译文,微信公众号“大数据文摘( id: BigDataDigest)”】