随着云计算技术的进步,软件系统的架构方式也因此发生着一些变化,其中Serverless架构就是这里的一个典型的例子。
一、什么是Serverless架构
目前关于Serverless架构的准确定义,业界并没有一个统一的标准。那么我们从字面上来分析,所谓Serverless架构,翻译过来也就是无服务器架构。那么似乎可以涵盖以下两个方面:
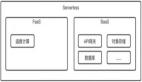
- BaaS(Backend as a Service)即后台即服务。后台即服务出现有很长一段的时间了,例如Parse,Firebase都是典型的代表。具体来说就是服务器端的逻辑和状态是完全依赖于云平台进行管理的。
- FaaS(Function as a Service)即函数即服务。函数即服务,意味着这些函数中的后台逻辑是由我们开发者自己实现的。但是这些函数是执行在一个无状态的计算容器中的,函数的执行是基于事件驱动的,关于这些函数的部署、执行、触发是由云平台来管理的。其最典型的例子就是AWS Lambda。
我们这篇文章中的所讨论的Serverless,是指的第二种,也就是FaaS。在我们Thoughtworks***一期的技术雷达中,Serverless架构位于试验象限,下文就介绍下我们在Serverless架构下的一些实践经验。
二、数据处理业务的Serverless架构演进
所谓的数据处理业务,是指我们的系统需要每天定时获取一些外部数据与我们自身的数据结合,生成一些数据报表。那么最初我们是怎么设计技术方案的呢?
1. 传统架构方式

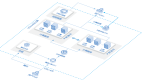
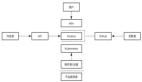
我们将业务拆分为3个独立的服务,2个Data Collector,1个Data Loader,都分别部署在AWS服务器上,将中间数据存储在一个外部S3(AWS的数据存储)上。***将数据保存在数据库中,在数据库之上使用专门的BI工具来制作报表。
我们***个数据服务就是按照这样的架构进行设计和实践的。当系统上线服务以后,我们发现了里边的一些问题。
在这套系统中,Data Collector 2每天的执行时间较长,需要1个小时左右的时间,而Data Collector 1每天的执行时间较短,通常执行时间不会超过1分钟,但是由于外部数据源的更新时间是不确定的,所以虽然我们服务实际有效时间只有仅仅一到两分钟,但是也不得不让服务器全天运行。
可以看到,这个系统每天的有效时间只有一个小时,其他23个小时实际上是在浪费资源,如何改善这样的情况呢?首先想到了让服务定点运行的方法。由于我们外服数据源的更新特点,虽然它的更新时间是不确定的,但是它在某个特定的时间点前是一定会更新的。基于这样的前提,我们将服务运行时间改为定点运行,这样是不是就能解决问题了呢?
然而现实并不总是那么美好,因为我们服务间是有依赖关系的,Data Loader是依赖于我们Data Collector的处理结果的,当我们把运行方式改为定点运行后,带来的问题是,一旦Data Collector的运行状态出现了问题,例如运行时间过长,运行中出现错误,那么Data Loader必然出错。同时改为定点运行后,我们的数据更新必然有延迟。
那么如何解决这些问题呢?
2. Serverless的系统架构

我们引入了Lambda,将Data Collector 和 Data Loader用Lambda进行了替换,带来了下面这些好处:
由于Lambda是由事件驱动的,S3上一个数据的变化可以触发一个事件,SNS的一条消息可以触发一个时间等等,在使用Lambda后,我们就可以讲原来基于时间的数据处理流程,转变为基于事件的数据处理流程,这样一方面可以保证我们数据更新的实时性,另一方面可以大大节省资源,由于Lambda是按照触发次数收费的,所以在我们的这个用例下,可以大大减少花费。
可能细心的读者想问为什么我们Data Collector 2没有使用Lambda进行替换呢?这是因为它的业务逻辑比较复杂,每次运行的时间较长,而Lambda的最长执行时间是5分钟,所以在这种情况下,就不适合使用Lambda进行替换了。
3. 实时数据处理下的Serverless架构
在初识Serverless架构的好处之后,我们开始在其他方面的应用尝试,比较典型的一个例子就是在实时数据处理业务下的Serverless架构。在我们业务下,我们需要实时跟踪一个外部的数据源API,根据它的数据变化来实时更新我们的数据。

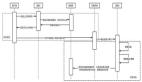
在我们的架构设计中,我们使用一个Lambda来跟踪外部数据源的数据变化,并将其推到AWS Kinesis Stream里,AWS Kinesis会触发第二个Lambda进行相应的数据处理,并把数据存储到数据库中,值得注意的是由于Lambda是可以根据需求自动伸缩的,所以Lambda会根据Kinesis的需求来自动扩展。这就体现了Serverless架构下的另一个好处,可以相对简单的,自动进行伸缩扩展。
4. Web系统的Serverless架构
对于Web系统这种我们最为熟悉和常见的IT系统来说,它能不能用Serverless的架构来实现呢?我们来看下边的例子。我们先来看看传统的例子。

在传统实现中,我们会利用Load Blancer来做负载均衡,然后后续的应用会部署在AutoScaling Group中,根据流量来做自动伸缩,这种模式已经是十分成熟了。那么在Serverless的架构下该如何设计呢?

在Serverless架构下,一般我们的前端应用的资源文件包括Html,JS,CSS,都是部署在S3(AWS的文件存储)上的。前端应用通过AJAX请求向后台请求数据。后台通过API GateWay定义对外的Endpoint,同时每个Endpoint会触发一个Lambda进行数据操作,例如图中的GET,和POST请求会触发两个不同Lambda。这样的Serverless架构可以让开发者不必担心水平扩展的问题。
三、Serverless架构的未来
目前AWS Lambda似乎已经成为了Serverless的代名词,为了帮助开发者更好的构建Serverless应用,市场上出现了一些工具和框架,例如Serverless Framework。但是同样我们还可以看到一些其他的云平台和开源框架也在提供类似的服务,例如webtask,OpenWhisk,以及其在IBM Bluemix上的实现。
Serverless架构作为一种新的架构方式,还在不断的发展中。希望本文能给您带来一些思考。
【本文是51CTO专栏作者“ThoughtWorks”的原创稿件,微信公众号:思特沃克,转载请联系原作者】