对于华为存储自研存储领域的相关芯片,外界一直充满好奇。纵观业界,Avago并购LSI,Cavium并购QLogic,博通并购博科,皆因芯片的技术能力,在芯片并购的大浪潮之下,为什么华为存储反其道而行之,自研芯片?特别是在火热的闪存存储领域,华为自研了哪些芯片?其芯片未来又是如何演进的呢?本文将为您一一解惑。
自研芯片驱动力
全球范围内的企业都面临数字洪流的影响,快速增长的数据规模、越来越高要求的业务处理性能和存储效率成为企业面临的重大挑战。作为企业数字化转型的利器,全闪存天生高性能的优势,为加速关键业务带来新的动力。
全闪存的高速发展,促使介质快速演进,介质性能由量变达到质变(3D XPoint介质比NAND介质快1000倍);介质和应用(AR/VR等)的发展,对网络也提出更低时延的要求;摩尔周期延长,导致CPU性能提升放缓,计算能力需求缺口增大;介质与网络接口、CPU技术发展不均衡,推动存储技术又一轮变革。
面对存储技术变革的挑战,为满足客户业务日益增长的诉求,华为存储提出以All IP为基础,以All Cloud和All Flash为牵引,芯片、网络设备、应用垂直整合的策略。通过垂直整合,实现资源***化利用,向客户提供具有更强性能的产品。
自研芯片技术创新
2016年华为发布新一代全闪存阵列OceanStor Dorado V3,具备高达400万IOPS时,仍保持0.5ms稳定时延的卓越性能,能充分发挥闪存效率,满足关键重载业务处理能力。华为存储构建了从前端协议处理芯片、IO处理加速芯片、SSD控制芯片端到端的硬件芯片平台,为全闪存存储带来创新的加速方案,端到端传输性能提升200%。
一.协议处理芯片
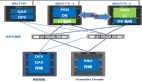
1.SmartIO融合多协议,减少连接线缆,简化组网,降低TCO
SmartIO卡使用华为存储协议处理芯片,同时支持8G/16G FC、10G FCoE、10GE、iWARP协议,客户可将IP 和FC数据流量整合到同一个接口芯片中。
通过支持融合组网,10GE支持FCoE/iSCSI/iWARP/CIFS/NFS多协议时,无需更换任何物理部件,支持与任何10GE存储主机端口进行连接。在10GE或8/16Gb FC组网下只需要更换光模块部件,无需更换卡件,支持任意协议转换。使布线减少1/3,接口卡物理部件减少75%,降低客户初始投资成本。
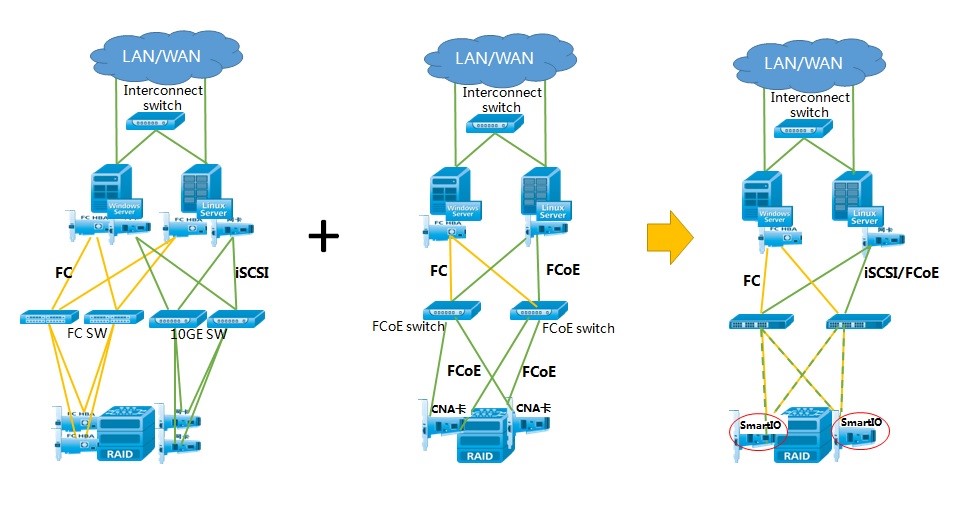
2.RDMA技术,降低60%链路时延
RDMA(Remote Direct Memory Access)是“远程直接数据存取”,通过网络把数据直接传入计算机的存储区,将数据从一个系统快速移动到远程系统存储器中,而不对操作系统造成任何影响,这样就不需要用到多少计算机的处理能力。因而能腾出总线空间和CPU周期,用于改进应用系统性能。华为存储协议处理芯片支持硬件级RDMA,在多个存储控制器之间通过RDMA进行数据传输和交换,从而降低链路上时延超过60%,极大地提升客户在多并发和高负载业务下的处理效率。基于10GE,在8并发、8KB IO大小,时延测试结果如下:
3.针对WAN优化,减少广域网拥塞,提升复杂组网场景下远程复制带宽
WAN优化即广域网优化,通过各种技术手段削减广域网数据传输量、优化广域网上的数据通信,提升广域网带宽利用率。WAN优化从部署方式上分为单边优化和双边优化:单边优化主要采用流控和TCP优化技术;双边优化主要采用缓存和压缩技术。
华为存储协议处理芯片内嵌QoS流控和TCP拥塞算法技术,在客户复杂组网场景,比如连接不同地区的局域网或城域网的计算机通信的远程网,甚至跨接很大的物理范围,所覆盖的范围从几十公里到几百公里连接多个城市情况下,通过实时侦测网络数据包RTT时延、丢包率、ECN等,配合多种TCP拥塞算法,调整发送和接收策略,包括重试策略、收/发Buffer窗口、智能流控等手段,动态的针对某些链路传输拥塞进行规避和缓解,达到比普通网卡跑得更快的目的。WAN加速在复杂组网下可提升65%~400%的广域网性能。
二.IO处理加速芯片
云服务时代带来数据超预期增长的同时,也带来了大量的重复数据,这些重复数据给企业带来的价值十分有限,却大量占用存储空间、增加能耗和散热成本,而且会降低系统的数据访问性能、消耗企业有限的IT预算。企业迫切希望有一种方法能够保证原有数据的访问性能,并在此基础上减少重复数据。
业内普遍采用重删和压缩技术来解决这个问题,但是重删压缩涉及到大量的指纹和压缩、解压缩算法,对CPU占用率较高,一旦开启会显著影响业务性能,因此传统存储都采用后重删压缩技术。对用户来说,后重删压缩技术无法减少客户预留存储空间,不能减少***购置成本,同时更多的数据写入,也影响SSD寿命。
华为IO处理加速芯片集成压缩、解压算法引擎,将压缩和解压缩等比较消耗计算资源的工作卸载到算法引擎,有效降低CPU负载。根据实际测试,在顺序大IO场景下,CPU占用率减少24.6%,IOPS提升342.4%,时延缩短77.4%。
三.SSD控制芯片
华为自研SSD使用新一代自研的SSD控制芯片,采用了计算能力更强的Cortex-A9芯片,支持DDR4,多达18个NAND Flash通道,采用了硬件FTL(Flash Translation Layer)技术加速IO处理,实现200K IOPS能力,达到业界领先水平。
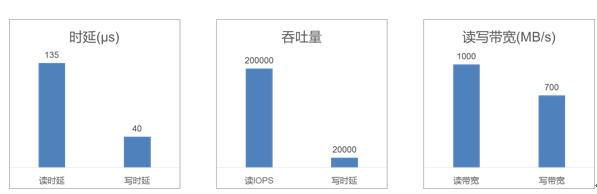
华为自研SSD性能数据
1. 硬件FTL,低负载时延比业界低20%
FTL(Flash Translation Layer)是SSD盘片内部的一个核心数据结构,用来保存用户LBA到SSD盘内物理页面的映射关系,用户读写数据时带下来一个LBA地址,SSD盘接收到以后,从FTL表中查询到该LBA地址所对应的物理页面,即可实现数据的读取。传统的SSD读取数据的时候,SSD内部控制软件查找到LBA地址对应的物理地址,然后再从Flash中读取对应的数据返回给主机;写入数据的时候,软件写入完毕后,再去更新FTL映射表。华为自研SSD使用硬件加速FTL表管理,所有读取和写入FTL的操作全部由硬件完成,减少软件交互次数,减小IO的延时,在低负载场景下时延低至40μs,比业界低20%。
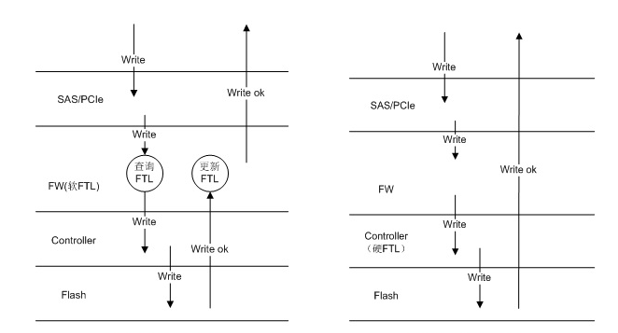
2. FlashLink技术保障全闪存阵列,实现平均稳定时延0.5ms
FlashLink技术是基于华为自研SSD盘和自研存储操作系统,实现盘控联动配合的软硬件垂直优化技术,保障华为OceanStor Dorado V3全闪存存储系统实现平均稳定时延0.5ms。

FlashLink技术示意图
冷热数据分区提供多个数据分区,自研存储操作系统在访问SSD盘片时,将数据的冷热标示发给SSD,SSD控制芯片根据数据冷热标识将冷热数据分开存放,从而降低SSD垃圾回收的搬移数据量,写放大降低约40%,时延降低20%。
IO优先级调度提供多个IO优先级调度能力,为保证稳定时延,自研存储操作系统对IO优先级别进行了标识。比如,主机读请求的优先级高于Flash Cache刷盘请求,Flash Cache刷盘写请求优先级高于异步复制的后台拷贝IO。IO优先级随着读写请求一起发给SSD,SSD控制芯片接收到IO时,根据IO的优先级标识优先处理高优先级IO,从而实现端到端的IO优先级控制,保障优先的业务数据读写在***顺序响应。
总结
华为存储在自研芯片研发上持续投入和技术创新,帮助企业应对数字洪流挑战,进行数字化转型。
协议处理芯片以All IP为战略,覆盖前端网络、交换网络、后端网络、复制/双活网络,构建大规模、低时延网络能力;IO处理加速芯片以SOC为方向,集成存储和网络加速功能,持续优化计算、存储、网络能力;SSD控制芯片以介质为核心,匹配介质演进节奏,针对介质特性进行优化,充分发挥新介质优势。
通过技术创新和软硬件芯片垂直优化,华为存储致力于消除CPU、介质、网络发展不均衡导致的鸿沟,为客户提供更快、更好、更省的产品和解决方案,与客户一起实现商业成功。