












前言
python具有丰富的库,并且很容易作为胶水语言很容易与c/c++进行交互集成。
因此为了适应快速变化的业务和兼顾计算效率,在上层采用python作为server提供service,在底层采用c/c++进行计算是一种对于算法开发者非常适宜的方式。
python flask库提供http接口以及相关demo页面,gunicorn提供多核并行能力,底层c++库提供单线程上的计算。
下面通过一个例子说明这种架构。代码地址:python_hps
准备
在实验开始之前,需要安装flask、gunicorn、apach bench tool等工具。
注:所有实验均在linux系统中进行。测试机器为4核虚拟机。
- sudo pip install flask
- sudo pip install gunicorn
- sudo apt-get install apache2-utils
计算
计算部分模拟真实计算,因此计算量比较大,在我测试的虚拟机上单核单线程跑400ms左右。
c++核心计算部分,随便写的:
- API_DESC int foo(const int val)
- {
- float result = 0.0f;
- for(int c=0;c<1000;c++)
- {
- for(int i=0;i<val;i++)
- {
- result += (i);
- result += sqrt((float)(i*i));
- result += pow((float)(i*i*i),0.1f);
- }
- }
- return (int)result;
- }
python wrapper,采用ctypes:
- #python wrapper of libfoo
- class FooWrapper:
- def __init__(self):
- cur_path = os.path.abspath(os.path.dirname(__file__))
- self.module = ctypes.CDLL(os.path.join(cur_path,'./impl/libfoo.so'))
- def foo(self,val):
- self.module.foo.argtypes = (ctypes.c_int,)
- self.module.foo.restype = ctypes.c_int
- result = self.module.foo(val)
- return result
flask http API:
- @app.route('/api/foo',methods=['GET','POST'])
- def handle_api_foo():
- #get input
- val = flask.request.json['val']
- logging.info('[handle_api_foo] val: %d' % (val))
- #do calc
- result = fooWrapper.foo(val)
- logging.info('[handle_api_foo] result: %d' % (result))
- result = json.dumps({'result':result})
- return result
单核服务
首先测试python单核服务,同时也是单线程服务(由于python GIL的存在,python多线程对于计算密集型任务几乎起反作用)。
- 启动服务
在script目录下执行run_single.sh,即
- #!/bin/sh
- #python
- export PYTHONIOENCODING=utf-8
- #start server
- cd `pwd`/..
- echo "run single pocess server"
- python server.py
- cd -
- echo "server is started."
- 测试服务
另外打开一个终端,执行script目录下的bench.sh,即
- #!/bin/sh
- ab -T 'application/json' -p post.data -n 100 -c 10 http://127.0.0.1:4096/api/foo
- 测试结果
CPU运转

ab测试结果
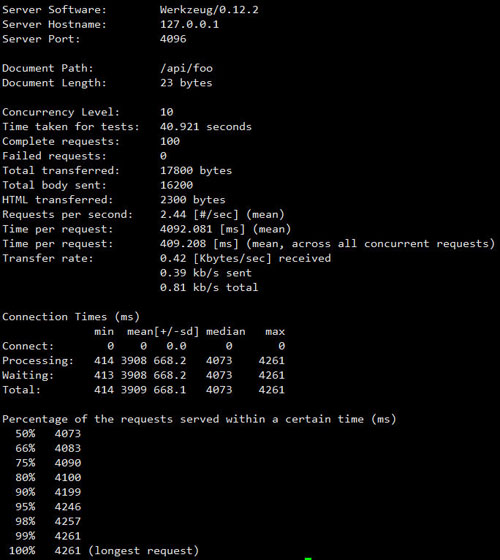
可以看出CPU只用了1个核,负载是2.44 request/second。
多核
- 启动服务
在script目录下执行run_parallel.sh,即
- #!/bin/sh
- #python
- export PYTHONIOENCODING=utf-8
- #start server
- cd `pwd`/..
- echo "run parallel pocess server"
- gunicorn -c gun.conf server:app
- cd -
- echo "server is started."
其中gun.conf是一个python脚本,配置了gunicorn的一些参数,如下:
- import multiprocessing
- bind = '0.0.0.0:4096'
- workers = max(multiprocessing.cpu_count()*2+1,1)
- backlog = 2048
- worker_class = "sync"
- debug = False
- proc_name = 'foo_server'
- 测试服务
另外打开一个终端,执行script目录下的bench.sh,即
- #!/bin/sh
- ab -T 'application/json' -p post.data -n 100 -c 10 http://127.0.0.1:4096/api/foo
- 测试结果
CPU运转

ab测试结果
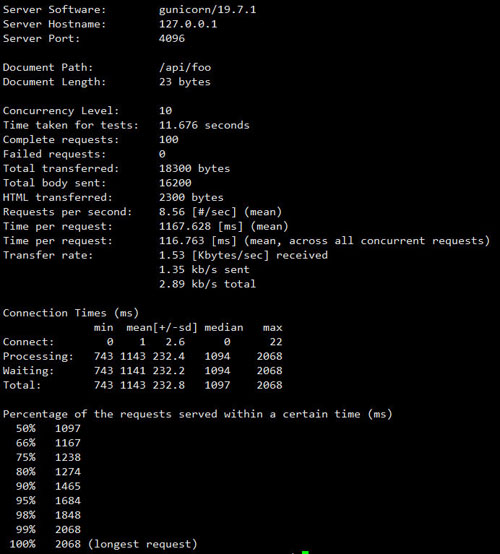
可以看出CPU用满了4个核,负载是8.56 request/second。是单核的3.5倍左右,可以任务基本达成多核有效利用的的目的。
总结
使用flask、gunicorn基本可以搭建一个用于调试或者不苛责过多性能的服务,用于算法服务提供非常方便。本文提供该方案的一个简单示例,实际业务中可基于此进行修改完善。
















