最近学习了一点网络爬虫,并实现了使用Python来爬取知乎的一些功能,这里做一个小的总结。网络爬虫是指通过一定的规则自动的从网上抓取一些信息的程序或脚本。我们知道机器学习和数据挖掘等都是从大量的数据出发,找到一些有价值有规律的东西,而爬虫则可以帮助我们解决获取数据难的问题,因此网络爬虫是我们应该掌握的一个技巧。
Python有很多开源工具包供我们使用,我这里使用了requests、BeautifulSoup4、json等包。requests模块帮助我们实现http请求,bs4模块和json模块帮助我们从获取到的数据中提取一些想要的信息,几个模块的具体功能这里不具体展开。下面我分功能来介绍如何爬取知乎。
模拟登录
要想实现对知乎的爬取,首先我们要实现模拟登录,因为不登录的话好多信息我们都无法访问。下面是登录函数,这里我直接使用了知乎用户fireling的登录函数,具体如下。其中你要在函数中的data里填上你的登录账号和密码,然后在爬虫之前先执行这个函数,不出意外的话你就登录成功了,这时你就可以继续抓取想要 的数据。注意,在***使用该函数时,程序会要求你手动输入captcha码,输入之后当前文件夹会多出cookiefile文件和zhihucaptcha.gif,前者保留了cookie信息,后者则保存了验证码,之后再去模拟登录时,程序会自动帮我们填上验证码。

需要注意的是,在login函数中有一个全局变量s=reequests.session(),我们用这个全局变量来访问知乎,整个爬取过程中,该对象都会保持我们的持续模拟登录。
获取用户基本信息
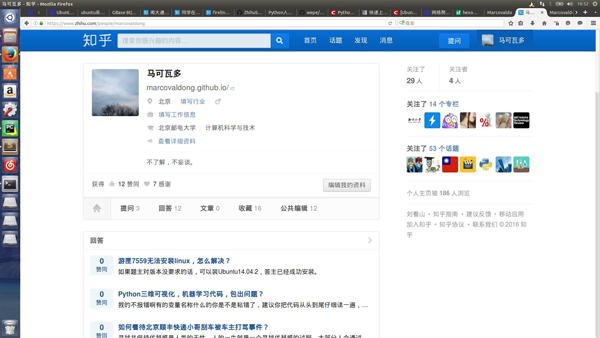
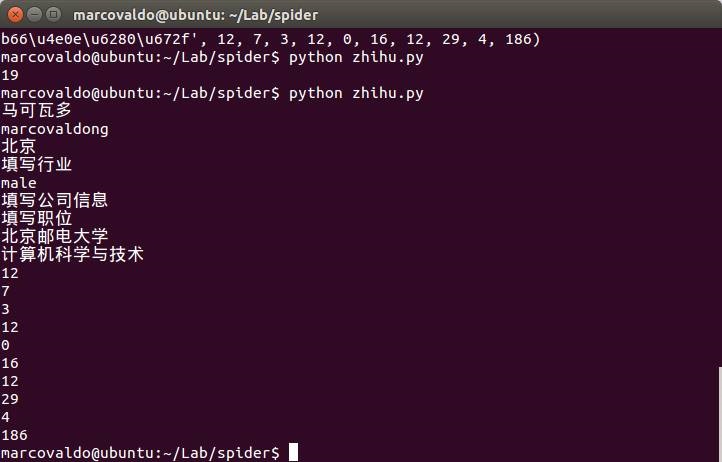
知乎上每个用户都有一个唯一ID,例如我的ID是marcovaldong,那么我们就可以通过访问地址 https://www.zhihu.com/people/marcovaldong 来访问我的主页。个人主页中包含了居住地、所在行业、性别、教育情况、获得的赞数、感谢数、关注了哪些人、被哪些人关注等信息。因此,我首先介绍如何通过爬虫来获取某一个知乎用户的一些信息。下面的函数get_userInfo(userID)实现了爬取一个知乎用户的个人信息,我们传递给该用户一个用户ID,该函数就会返回一个 list,其中包含昵称、ID、居住地、所在行业、性别、所在公司、职位、毕业学校、专业、赞同数、感谢数、提问数、回答数、文章数、收藏数、公共编辑数量、关注的人数、被关注的人数、主页被多少个人浏览过等19个数据。
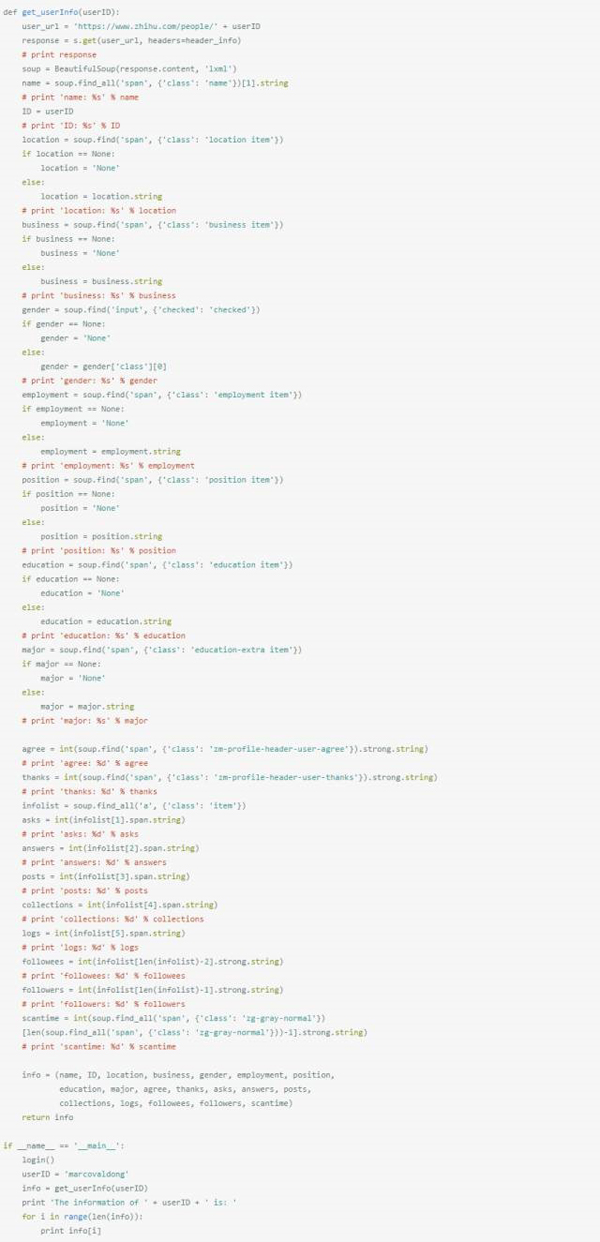
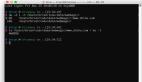
下图是我的主页的部分截图,从上面可以看到这19个数据,下面第二张图是终端上显示的我的这19个数据,我们可以作个对照,看看是否全部抓取到了。这个函数我用了很长时间来调试,因为不同人的主页的信息完整程度是不同的,如果你在使用过程中发现了错误,欢迎告诉我。
获取某个答案的所有点赞者名单
知乎上有一个问题是如何写个爬虫程序扒下知乎某个回答所有点赞用户名单?,我参考了段小草的这个答案如何入门Python爬虫,然后有了下面的这个函数。
这里先来大概的分析一下整个流程。我们要知道,知乎上的每一个问题都有一个唯一ID,这个可以从地址中看出来,例如问题2015 年有哪些书你读过以后觉得名不符实?的地址为 https://www.zhihu.com/question/38808048 ,其中38808048就是其ID。而每一个问题下的每一个答案也有一个唯一ID,例如该问题下的***票答案2015 年有哪些书你读过以后觉得名不符实? - 余悦的回答 - 知乎的地址链接为https://www.zhihu.com/question/38808048/answer/81388411 ,末尾的81388411就是该答案在该问题下的唯一ID。不过我们这里用到的不是这两个ID,而是我们在抓取点赞者名单时的唯一ID,此ID的获得方法是这样:例如我们打算抓取如何评价《人间正道是沧桑》这部电视剧? - 老编辑的回答 - 知乎的点赞者名单,首先打开firebug,点击“5321 人赞同”时,firebug会抓取到一个“GET voters_profile”的一个包,把光标放在上面,会看到一个链接 https://www.zhihu.com/answer/5430533/voters_profile ,其中的5430533才是我们在抓取点赞者名单时用到的一个唯一ID。注意此ID只有在答案被赞过后才有。(在这安利一下《人间正道是沧桑》这部电视剧,该剧以杨立青三兄妹的恩怨情仇为线索,从大革命时期到解放战争,比较全面客观的展现了国共两党之间的主义之争,每一次看都会新的认识和体会。)
在拿到唯一ID后,我们用requests模块去get到知乎返回的信息,其中有一个json语句,该json语句中包含点赞者的信息。另外,我们在网页上浏览点赞者名单时,一次只能看到20条,每次下拉到名单底部时又加载出20条信息,再加载20条信息时所用的请求地址也包含在前面的json语句中。因此我们需要从json语句中提取出点攒着信息和下一个请求地址。在网页上浏览点赞者名单时,我们可以看到点赞者的昵称、头像、获得了多少赞同和感谢,以及提问和回答的问题数量,这里我提取了每个点赞者的昵称、主页地址(也就是用户ID)、赞同数、感谢数、提问数和回答数。关于头像的提取,我会在下面的函数中实现。
在提取到点赞者名单后,我将者信息保存了以唯一ID命名的txt文件中。下面是函数的具体实现。

注意,点赞者名单中会有匿名用户,或者有用户被注销,这时我们抓取不到此用户的信息,我这里在txt文件中添加了一句“有点赞者的信息缺失”。
使用同样的方法,我们就可以抓取到一个用户的关注者名单和被关注者名单,下面列出了这两个函数。但是关注者名单抓取函数有一个问题,每次使用其抓取大V的关注者名单时,当抓取到第10020个follower的时候程序就会报错,好像知乎有访问限制一般。这个问题,我还没有找到解决办法,希望有solution的告知一下。因为没有看到有用户关注10020+个人,因此抓取被关注者名单函数暂时未发现报错。

提取用户头像
再往下就是抓取用户头像了,给出某个唯一ID,下面的函数自动解析其主页,从中解析出该用户头像地址,抓取到图片并保存到本地文件,文件以用户唯一ID命名。
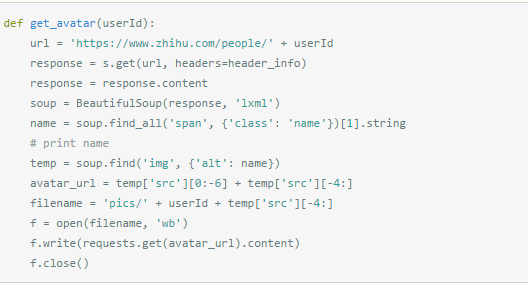
结合其他函数,我们就可以抓取到某个答案下所有点赞者的头像,某个大V所有followers的头像等。
抓取某个问题的所有答案
给出某个唯一ID,下面的函数帮助爬取到该问题下的所有答案。注意,答案内容只抓取文字部分,图片省略,答案保存在txt文件中,txt文件以答主ID命名。

数据库存取数据
在完成了上面的这些功能后,下一步要做的是将用户信息保存在数据库中,方便数据的读取使用。我刚刚接触了一下sqlite3,仅仅实现了将用户信息存储在表格中。

等熟悉了sqlite3的使用,我的下一步工作是抓取大量用户信息和用户之间的follow信息,尝试着将大V间的follow关系进行可视化。再下面的工作应该就是学习python的爬虫框架scrapy和爬取微博了。
另外,在写这篇博客的时候我又重新测试了一下上面的这些函数,然后我再在火狐上访问知乎时,系统提示“因为该账户过度频繁访问”而要求输入验证码,看来知乎已经开始限制爬虫了,这样以来我们就需要使用一些反反爬虫技巧了,比如控制访问频率等等,这个等以后有了系统的了解之后再作补充吧。