CNN是现在十分火热的模型,在很多图像检索问题上,CNN模型的效果在以往的基础上有了很大的提高,但是CNN毕竟没有把这些问题完全解决,CNN还是有它自己的弱点的。这个弱点也不能算作是它独有的问题,但是由于它的效果实在太好了,很多人甚至对它产生了迷信,因此这盆冷水就泼到它身上了。
大神们看到了CNN模型的强大,但忍不住提出一个问题:CNN有没有什么搞不定的地方?比方说我们用CNN构建了一个人脸识别的模型,在训练数据集和测试数据集上表现良好,但是会不会有一些用例是它会误判的,而且我们可以找到规律生成这些用例?
我们可以想象,如果我们对之前识别正确的数据做轻微的改动,那么它还是有可能识别正确的。于是我们就有了一个方案,我们每将图像做一点改动,就把图像传入CNN做一下测试,然后看看CNN的预测结果有没有发生改变,如果没有发生改变,我们就保存这个图像,接着我们再进行下一轮的改动,经过若干轮的改动后,我们把生成的图像输出出来看看图像会变成什么样子。
这里我们将采用MNIST为例,以下的就是我们的改动方案:
- 利用MNIST的训练集训练一个CNN的模型,我们的CNN模型结构是:conv32*3*3->relu->maxpool2*2->conv64*3*6->relu->maxpool2*2->fc256->dropout0.5->fc10。
- 找到一个训练数据,将其数据范围限定在0到1之间,我们对每一个像素点随机增减-0.1到0.1之间的一个数,这样得到64个随机的图像,然后经过CNN模型预测得到这64个图像的预测label,从中选择一个和原始label相同的图像。经过若干轮迭代后,我们就可以看看这个随机改变的数字变成了什么样子。
我们选择了一个数字0:
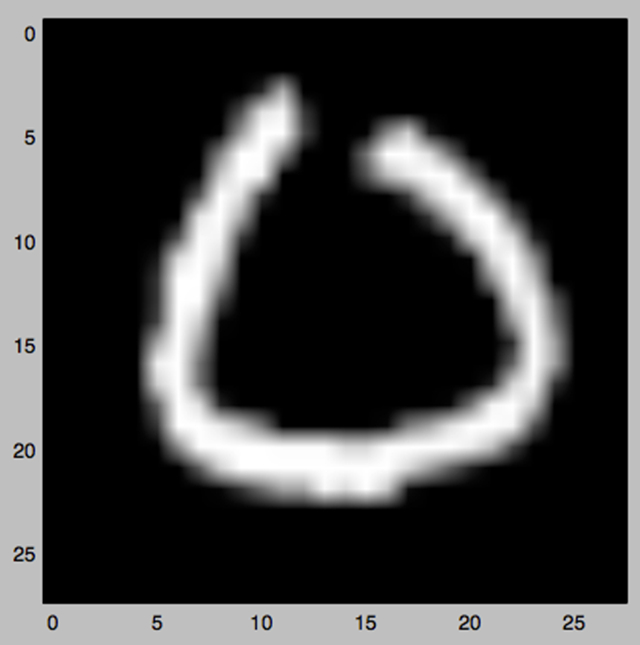
经过50轮迭代,我们得到了这样的图像:
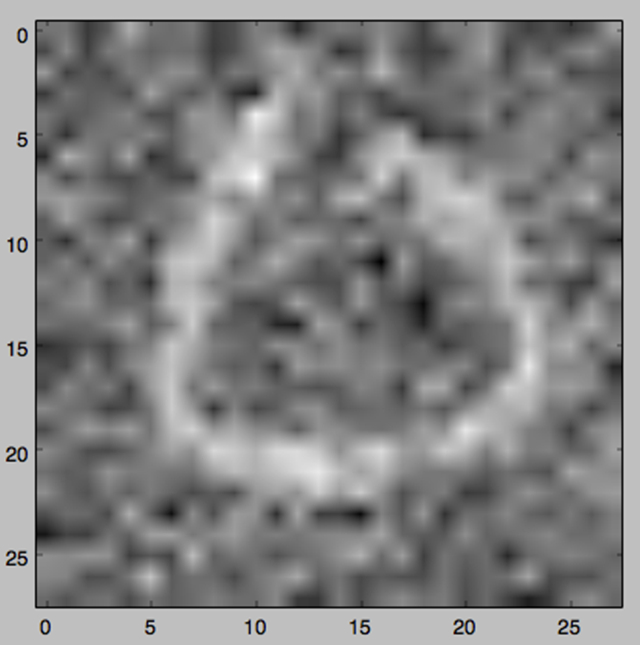
经过100轮迭代,我们得到了这样的图像:
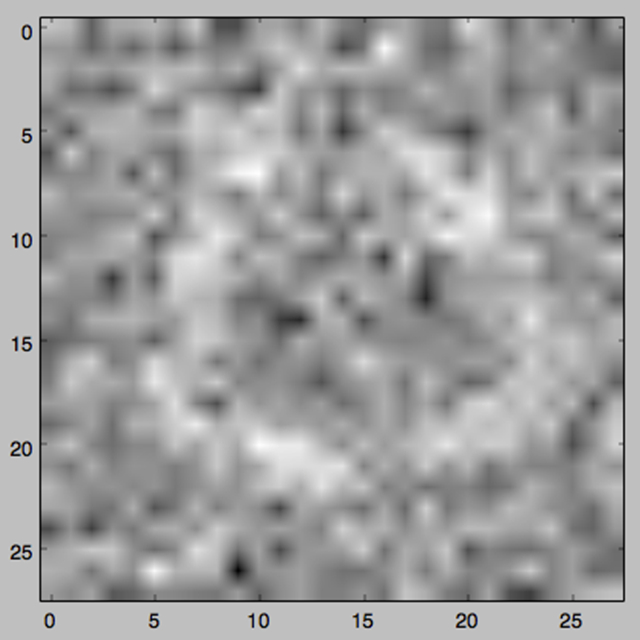
经过150轮迭代,我们得到了这样的图像:
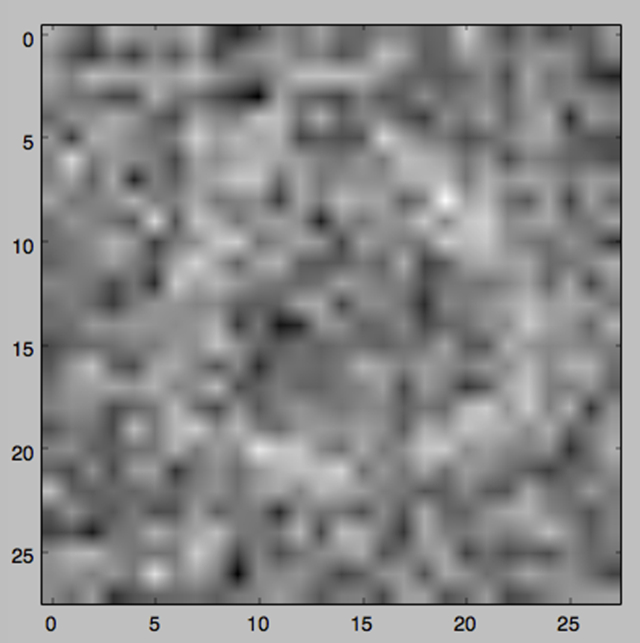
经过200轮迭代,我们得到了这样的图像:
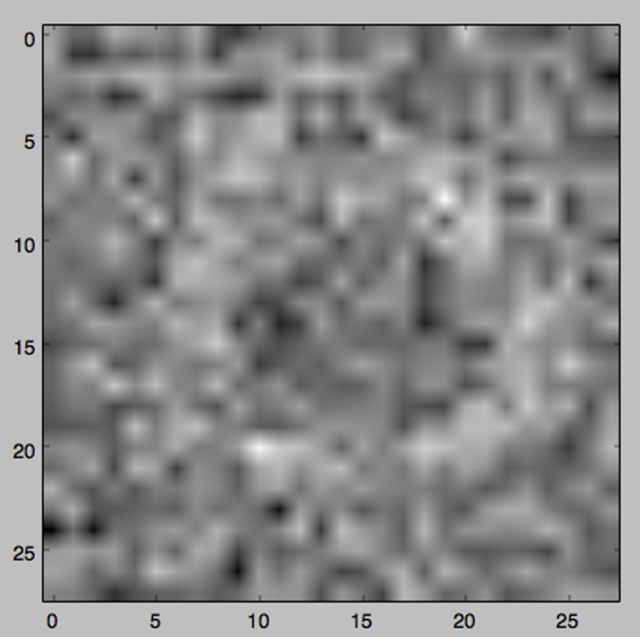
到此为止,可以看出这个数字还是隐约可见,但是实际上图像已经变得模糊不清,大量的杂乱信息混入其中,已经和原始的数字完全不同。
这个套路被称作“fool CNN”,用东北话说就是忽悠。继续迭代下去,我们还能生成出更精彩的图像。当然这也只是忽悠CNN模型的一种办法,我们还有其他的办法来生成图像。其他的办法这里就不再介绍了。关于这种忽悠,大神们也给出了和机器学习有关的解释:
CNN的模型说到底还是个判别式模型,如果我们把图像设为X,label设为y,CNN的模型就相当于求p(y|X)的值。判别式模型相当于描述“什么样的图像是这个label的图像”,而满足了这些条件的图像有时并不是具有真实label的那个图像。而上面的忽悠套路就是利用了这个漏洞。
上面的例子中,我们用这种fool的方法让一张模糊不清的图像保持了原来的label,同时我们也可以让一张不算模糊的图像被CNN错认成另外一个label。
比方说下面这张经过40轮迭代的图像被认成了6:
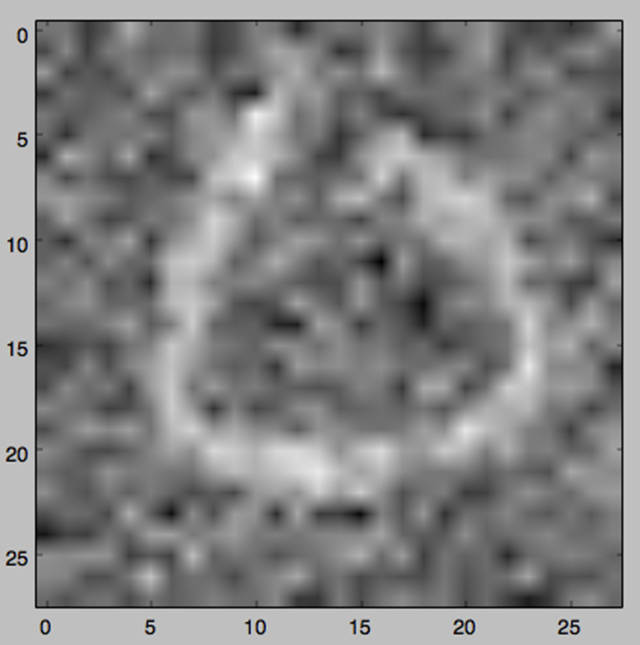
这些套路的出现都让我们对CNN有了一些警惕,如果想让CNN对手写数字完全hold住,我们还需要其他的方法辅助,不然的话这种意外总会发生。
那么有没有什么方法能解决这样的问题呢?