一、可视化之根
多年前读过一篇非常震撼的文章,叫《Lisp之根》(英文版:The roots of Lisp),大意是Lisp仅仅通过一种数据结构(列表)和有限的几个函数,就构建出了一门极为简洁,且极具扩展性的编程语言。当时就深深的被这种设计哲学所震撼:一方面它足够简单,每个单独的函数都足够简单,另一方面它有非常复杂,像宏,高阶函数,递归等机制可以构建出任意复杂的程序,而复杂的机制又是由简单的组件组成的。
数据的可视化也是一样,组成一幅内容清晰、表达力强、美观的可视化信息图的也仅仅是一些基本的元素,这些元素的不同组合却可以产生出令人着迷的力量。
要列出“可视化元素之根”很容易:位置、长度、角度、形状、纹理、面积(体积)、色相、饱和度等几种有限的元素,邱南森在他的《数据之美》中提供了一张视觉元素的图,其中包含了大部分常用的元素。

令人振奋的是,这些元素可以自由组合,而且组合旺旺会产生1+1>2的效果。
二、心理学与认知系统
数据可视化其实是基于人类的视觉认知系统的,因此对人类视觉系统的工作方式有一些了解可以帮助我们设计出更为高效(更快的传递我们想要表达的信息给读者)的可视化作品。
1. 心理物理学
在生活中,我们会遇到这样的场景:一件原价10元的商品,如果降价为5元,则消费者很容易购买;而一件原价100元的商品,降价为95元,则难以刺激消费者产生购买的冲动。这两个打折的绝对数字都是5元,但是效果是不一样的。
韦伯-费希纳定理描述的正是这种_非理性_的场景。这个定理的一个比较装逼的描述是:
【感觉量与物理量的对数值成正比,也就是说,感觉量的增加落后于物理量的增加,物理量成几何级数增长,而心理量成算术级数增长,这个经验公式被称为费希纳定律或韦伯-费希纳定律。
—— 摘自百度百科】
这个现象由人类的大脑构造而固有,因此在设计可视化作品时也应该充分考虑,比如:
- 避免使用面积图作为对比
- 在做对比类图形时,当差异不明显时需要考虑采用非线性的视觉元素
- 选用多种颜色作为视觉编码时,差异应该足够大
比如:

如上图中,当面积增大之后,肉眼越来越难从形状的大小中解码出实际的数据差异,上边的三组矩形(每行的两个为一组),背后对应的数据如下,可以看到每组中的两个矩形的绝对差都是5:
- var data = [
- {width: 5, height: 5},
- {width: 10, height: 10},
- {width: 50, height: 50},
- {width: 55, height: 55},
- {width: 100, height: 100},
- {width: 105, height: 105}
- ];
2. 格式塔学派
格式塔学派是心理学中的一个重要流派,她强调整体认识,而不是结构主义的组成说。格式塔认为,人类在看到画面时,会优先将其简化为一个整体,然后再细化到每个部分;而不是先识别出各个部分,再拼接为整体。
比如那条著名的斑点狗:

我们的眼睛-大脑可以很容易的看出阴影中的斑点狗,而不是先识别出狗的四条腿或者尾巴(事实上在这张图中,人眼无法识别出各个独立的部分)。
格式塔理论有几个很重要的原理:
- 接近性原理
- 相似性原理
- 封闭性原理
- 连续性原理
- 主体/背景原理
当然,格式塔学派后续还有一些发展,总结出了更多的原理。工程上,这些原理还在大量使用,指导设计师设计各式各样的用户界面。鉴于网上已经有众多的格式塔理论及其应用的文章,这里就不在赘述。有兴趣的同学可以参考这几篇文章:
- 优设上的一篇格式塔文章
- 优设上的一篇关于格式塔与Web设计的文章
- 腾讯CDC的一篇格式塔介绍
三、视觉设计的基本原则
《写给大家看的设计书》一书中,作者用通俗易懂的方式给出了几条设计的基本原则,这些原则完全可以直接用在数据可视化中的设计中:
- 亲密性(将有关联的信息物理上放在一起,而关联不大的则通过留白等手段分开)
- 对齐(将元素通过水平,垂直方向对齐,方便视觉识别)
- 重复(重复使用某一模式,比如标题1的字体颜色,标题2的字体颜色等,保持重复且一致)
- 对比(通过强烈的对比将不同的信息区分开)

如果稍加留意,就会发现现实世界中在大量的使用这几个原则。1,2,3三个标题的形式就是重复性的体现;每个标题的内容自成一体是因为组成它的元素(数字,两行文字)的距离比较近,根据亲密性原则,人眼会自动将其归为一类;超大的数字字体和较小的文字形成了对比;大标题的颜色和其他内容形成了对比等等。
这些原则其实跟上面提到的格式塔学派,以及韦伯-费希纳定理事实上是相关的,在理解了这些人类视觉识别的机制之后,使用这些原则就非常自然和得心应手了。
一些例子
- 淡化图表的网格(和数据图形产生对比)
- 通过深色来强调标尺(强烈的线条和其余部分产生对比)
- 离群点的高亮(通过不同颜色产生对比)
- 使用颜色(通过不同的颜色,利用亲密性原则方便读者对数据分组)
- 元素颜色和legend(使用重复性原则)
- 同一个页面上有多个图表,采取同样的图例,色彩选择(强调重复性原则)

四、实例
上篇文章提到我通过一个手机App收集到了女儿成长的一些记录,包括哺乳信息,换尿布记录,以及睡眠信息。这个例子中,我会一步步的介绍如何将这些信息可视化出来,并解释其中使用的视觉原理。
可视化的第一步是要明确你想要从数据中获取什么信息,我想要获取的信息是孩子的睡眠总量以及睡眠时间分布情况。
1. 进阶版的条形图
确定了可视化的目的之后,第二步是选取合适的视觉编码。上面提到过,对于人眼来说,最精确的视觉编码方式是长度。我们可以将睡眠时间转化为长度来展现,最简单的方式是按天聚合,然后化成柱状图。比如:
- 2016/11/21,768
- 2016/11/22,760
- 2016/11/23,700
不过这种图无法看出时间的分布。我们可以考虑通过条形图的变体来满足前面提到的两个核心诉求。先来在纸上画一个简单的草图。纵轴是24小时,横轴是日期。和普通的条形图不一样的是,每个条形的总长度是固定的,而且条形代表的不是简单非数据类型,而是24小时。在草稿中,每个画斜线的方块表示孩子在睡眠状态,而虚线部分表示她醒着。

2. 原始数据
- name,date,length,note
- 心心,2016/11/21 19:23,119,
- 心心,2016/11/21 22:04,211,
- 心心,2016/11/22 02:03,19,
- 心心,2016/11/22 02:23,118,
- 心心,2016/11/22 05:58,242,
- 心心,2016/11/22 10:57,128,
- 心心,2016/11/22 14:35,127,
- 心心,2016/11/22 17:15,127,
- 心心,2016/11/22 20:02,177,
- 心心,2016/11/23 01:27,197,
这里有个问题,我们的纵轴是24小时,如果她晚上23点开始睡觉,睡了3个小时,那么这个条形就回超出24格的轴。我写了一个函数来做数据转换:
- require 'csv'
- require 'active_support/all'
- require 'json'
- csv = CSV.read('./visualization/data/sleeping_data_refined.csv', :headers => :first_row)
- data = []
- csv.each do |row|
- date = DateTime.parse(row['date'], "%Y/%m/%d %H:%M")
- mins_until_end_of_day = date.seconds_until_end_of_day / 60
- diff = mins_until_end_of_day - row['length'].to_i
- if (diff >= 0) then
- data << {
- :name => row['name'],
- :date => row['date'],
- :length => row['length'],
- :note => row['note']
- }
- else
- data << {
- :name => row['name'],
- :date => date.strftime("%Y/%m/%d %H:%M"),
- :length => mins_until_end_of_day,
- :note => row['note']
- }
- data << {
- :name => row['name'],
- :date => (date.beginning_of_day + 1.day).strftime("%Y/%m/%d %H:%M"),
- :length => diff.abs,
- :note => row['note']
- }
- end
- end
有了干净的数据之后,我们可以编写一些前端的代码来绘制条形图了。画图的时候有几个要注意的点:
- 每天内的时间段对应的矩形需要有相同的X坐标
- 不同的睡眠长度要有颜色区分(睡眠时间越长,颜色越深)
- require 'csv'
- require 'active_support/all'
- require 'json'
- csv = CSV.read('./visualization/data/sleeping_data_refined.csv', :headers => :first_row)
- data = []
- csv.each do |row|
- date = DateTime.parse(row['date'], "%Y/%m/%d %H:%M")
- mins_until_end_of_day = date.seconds_until_end_of_day / 60
- diff = mins_until_end_of_day - row['length'].to_i
- if (diff >= 0) then
- data << {
- :name => row['name'],
- :date => row['date'],
- :length => row['length'],
- :note => row['note']
- }
- else
- data << {
- :name => row['name'],
- :date => date.strftime("%Y/%m/%d %H:%M"),
- :length => mins_until_end_of_day,
- :note => row['note']
- }
- data << {
- :name => row['name'],
- :date => (date.beginning_of_day + 1.day).strftime("%Y/%m/%d %H:%M"),
- :length => diff.abs,
- :note => row['note']
- }
- end
- end
函数getFirstInDomain可以根据一个日期值返回一个X坐标,这样2016/11/21 19:23和2016/11/21 22:04都会返回一个整数值(借助d3提供的标尺函数)。
另外,我们根据每次睡觉的分钟数将睡眠质量划分为5个等级:
- var level = d3.scale.threshold()
- .domain([60, 120, 180, 240, 300])
- .range(["low", "fine", "medium", "good", "great", "prefect"]);
然后在绘制过程中,根据实际数据值来确定不同的CSS Class:
- svg.selectAll(".bar")
- .data(data)
- .enter()
- .append("rect")
- .attr("class", function(d) {
- return level(d.length)+" bar";
- })
- //...
实现之后,看起来是这个样子的。事实上这个图标可以比较清楚的看出大部分睡眠集中在0-6点,而中午的10-13点以及黄昏18-20点基本上只有一些零星的睡眠。

3. 星空图
上面的图有一个缺点,是当日期很多的时候(上图差不多有100天的数据),X轴会比较难画,如果缩减成按周,或者按月,又会增加很多额外的复杂度。
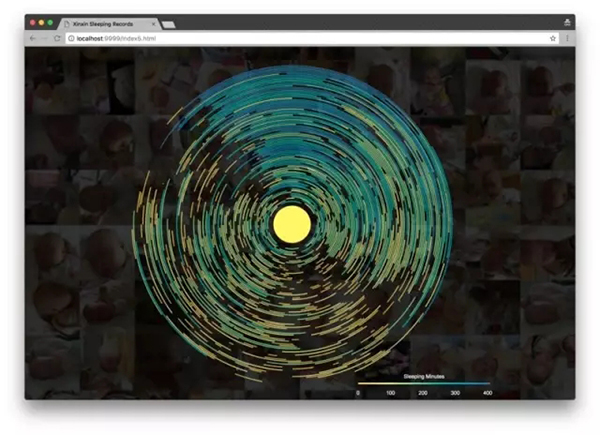
另外一个尝试是变形:既然这个统计是和时间相关的,那么圆形的钟表形象是一个很好的隐喻,每天24小时自然的可以映射为一个圆。而睡眠时间可以通过弧长来表示,睡眠时间越长,弧长越大:

4. 角度转弧度
我们首先将整个圆(360度)按照分钟划分,则每分钟对应的角度数为:360/(24*60),再将角度转化为弧度:degree * π/180:
- var perAngle = (360 / (24 * 60)) * (Math.PI/180);
那么对于指定的时间,比如10:20,先计算出其分钟数:10*60+20,再乘以preAngle,就可以得出起始弧度;起始时间的分钟数加上睡眠时长,再乘以preAngle,就是结束弧度。
- function startAngle(date) {
- var start = (date.getHours() * 60 + date.getMinutes()) * perAngle;
- return Math.floor(start*1000)/1000;
- }
- function endAngle(date, length) {
- var end = (date.getHours() * 60 + date.getMinutes() + length) * perAngle;
- return Math.floor(end*1000)/1000;
- }
实现的结果是这样的:

初看起来,它像是星空图,但是图中的不同颜色含义没有那么直观,我们需要在图上补充一个图例。通过使用d3的线性标尺和定义svg的渐变来实现,定义好渐变和渐变的颜色取值范围之后,就可以来绘制图例了。

图上的每段弧都会有鼠标移动上去的tooltip,这样可以很好的和读者大脑中的钟表隐喻对照起来,使得图表更容易理解。

由于我将整个圆分成了24份,这点和普通的钟表事实上有差异,那么如果加上钟表的刻度,会不会更好一些呢?从结果来看,这样的标线反而有点画蛇添足,所以我在最后的版本中去掉了钟表的标线。
可以看到,我们通过圆形的钟表隐喻来体现每一天的睡眠分布,然后用颜色的深浅来表示每次睡眠的时长。由于钟表的形象已经深入人心,因此读者很容易发现0点在圆环群的正上方。中心的黄色实心圆帮助读者视线先聚焦在最内侧的圆上,然后逐渐向外,这和日期的分布方向正好一致。
最终的结果在这里:心心的睡眠记录,完整的代码在这里。
5. 更进一步
一个完整的可视化作品,不但要运用各种视觉编码来将数据转换为视觉元素,背景信息也同样重要。既然这个星空图是关于睡眠主题的,那么一个包含她在睡觉的图片集合则会加强这种视觉暗示,帮助读者快速理解。
6. 制作背景图
我从相册中选取了很多女儿睡觉时拍的照片,现在需要有个工具将这些照片缩小成合适大小,然后拼接成一个大的图片。这其中有很多有趣的地方,比如图片有横屏、竖屏之分,有的还是正方形的,我需要让缩放的结果是正方形的,这样容易拼接一些。
好在有imagemagick这种神器,只需要一条命令就可以做到:
- $ montage *.jpg -geometry +0+0 -resize 128x128^ \
- -gravity center -crop 128x128+0+0 xinxin-sleeping.jpg
这条命令将当前目录下的所有的jpg文件缩放成128x128像素,并从中间开始裁剪-gravity center,+0+0表示图片之间的缝隙,最后将结果写入到xinxin-sleeping.jpg中。
拼接好图片之后,就可以通过CSS或者图片编辑器为其添加模糊效果,并设置深灰色半透明遮罩。
- body {
- background-image:url('/xinxin-sleeping.png');
- background-size:cover;
- background-position:center;
- }
当然,背景信息只是补充作用,需要避免喧宾夺主。因此图片做了模糊处理,且加上了深灰色的半透明Mask(此处应用了格式塔理论中的主体/背景原理)。
五、小结
这篇文章讨论了可视化作品背后的一些视觉元素理论,以及人类的视觉识别机制。在这些机制的基础上,介绍了如何运用常用的设计原则来进行视觉编码。最后,通过一个实例来介绍如何运用这些元素 – 以及更重要的,这些元素的组合 – 来制作一个漂亮的、有意义的可视化图表。
【本文是51CTO专栏作者“ThoughtWorks”的原创稿件,微信公众号:思特沃克,转载请联系原作者】