批归一化技术(Batch Normalization)是深度学习中最近出现的一个有效的技术,已经被广泛证明其有效性,并很快应用于研究和应用中去。这篇文章假设读者知道什么是批归一化,并对批归一化有一定程度的了解,知道它是如何工作的。如果你是刚刚接触这个概念,或者需要复习一下,您可以在后面的链接地址找到批归一化的简要概述(http://blog.csdn.net/malefactor/article/details/51476961)。
本文使用两种不同方法实现了一种神经网络。每一步都输入相同的数据。网络具有完全相同的损失函数、完全相同的超参数和完全相同的优化器。然后在完全相同数量的 GPU 上进行训练。结果是其中一个版本的分类准确度比另一种低2%,并且这种性能的下降表现地很稳定。
我们拿一个简单的 MNIST 和 SVHN 的分类问题为例。
在***种实现中,抽取一批 MNIST 数据和一批 SVHN 数据,将它们合并到一起,然后将其输入网络。
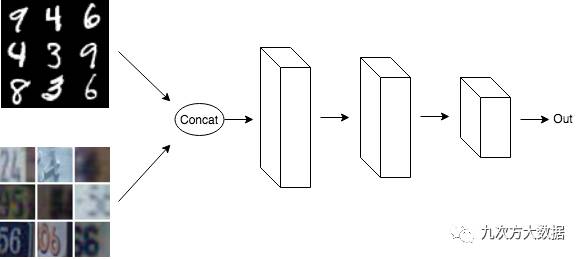
在第二种实现中,创建两个副本的网络,并共享权重。一个副本输入 MNIST 数据,另一个副本输入 SVHN 数据。
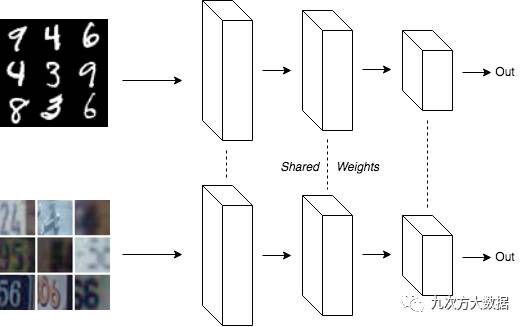
请注意,在这两种实现里,一半的数据是 MNIST,另一半是 SVHN。另外由于第二种实现共享权重,使得两个模型的参数数量相同,且其更新方式也相同。
简单地想一下,这两个模型的训练过程中梯度应该是相同的。事实也是如此。但是在加入批归一化之后情况就不同了。在***种实现中,同一批数据中同时包含 MNIST 数据和 SVHN 数据。而在第二种方法中,该模型分两批进行训练,一批只训练 MNIST 数据,另一批只训练 SVHN 数据。
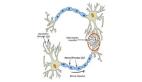
导致这个问题的原因就是:在训练的时候,在两个网络共享参数的同时,其数据集均值和方差的移动平均也是被共享的。这个参数的更新也是应用在两套数据集上的。在第二种方法中,图中上方的网络用来自 MNIST 数据的平均值和方差的估计值进行训练,而下方的网络用 SVHN 数据平均值和方差的估计值进行训练。但是由于移动平均在两个网络之间共享,所以移动平均收敛到 MNIST 和 SVHN 数据的平均值。
因此,在测试时,测试集使用的批归一化的缩放和平移(某一种数据集的平均值)与模型预期的(两种数据集的平均值)是不同的。当测试的归一化与训练的归一化不同时,模型会得到如下结果。
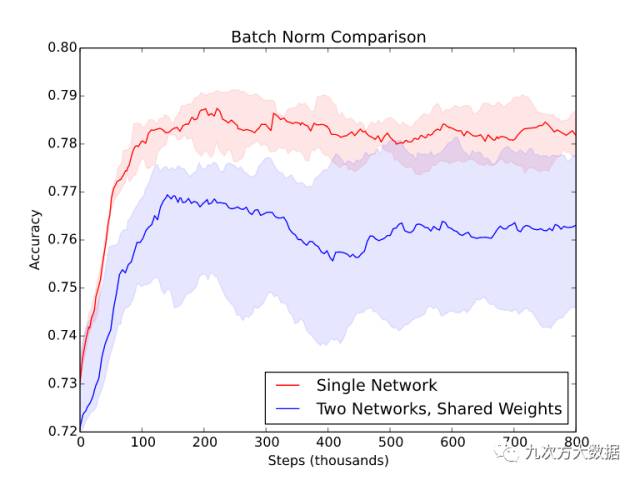
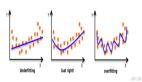
该图是在另一个相似数据集上(不是例子中的 MNIST 或 SVHN)用五个随机种子的得到的***、中间和最差的模型的性能。当使用两个共享权重的网络时,不仅性能下降明显,而且输出结果的方差也增加。
每当单个小批次(minibatch)的数据不能代表整个数据的分布时,都会遇到这样的问题。这就意味着忘记将输入随机打乱顺序的情况下使用批归一化是很危险的。这在最近流行的生成对抗网络(GAN)里也是非常重要的。GAN中的判别器通常是对假数据和真实数据的混合进行训练。如果在判别器中使用了批归一化,在纯假数据的批次或纯真实数据批次之间进行交替是不正确的。每个小批次需要是两者的均匀混合(各 50%)。
值得一提的是,在实践中,使用分离批归一化变量而共享其他变量的网络结构得到了***的结果。虽然这样实现起来比较复杂,但的确是比其他方法有效的(见下图)。
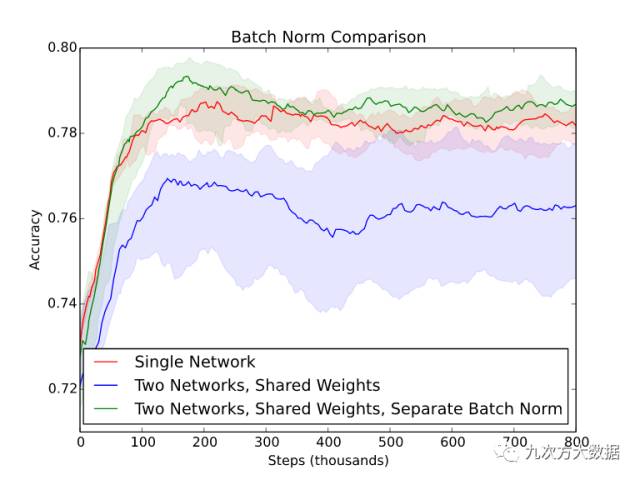
批归一化:万恶之源
纵观上述问题,作者得出了能不用就不用批归一化的结论。
这个结论是从工程的角度来分析的。
大体来讲,当代码出问题的时候,原因往往不外乎下面两个:
- 很明显的错误。比如变量名输错了,或忘记调用某个函数。
- 代码对与其交互的其他代码的行为有没有写明的依赖条件,并且的确有些条件没有满足。这些错误往往更加有害,因为一般需要花很长时间来弄清楚代码依赖什么样的条件。
这两个错误都是不可避免的。第二类错误可以依靠使用更简单的方法和重用已有代码来减少。
批归一化的方法有两个基本的性质:
- 在训练时,单个输入 xi 的输出受制于小批次中的其他 xj 。
- 在测试时,模型的计算路径发生了变化。因为现在它使用移动平均值而不是小批次平均值来进行归一化。
几乎没有其他优化方法有这些性质。这样的话,对于实现批归一化代码的人,很容易假设以下的前提:输入的小批次内是不相关的,或者训练时与测试时做的事情是一样的。没有人会质疑这种做法。
当然,你可以将批归一化看作***归一化黑盒,而且还挺好用的。但是在实践中,抽象泄漏总是存在的,批归一化也不例外,而且其特性使它更容易泄漏。
为什么大家还不放弃批归一化?
计算机学界有一封著名的文章: Dijkstra 的“ GoTo 语句是有害的”。在其中,Dijkstra 认为应该避免使用 goto 语句,因为它使得代码更难阅读,任何使用 goto 的程序都可以换种不用 goto 语句的方法重写。
作者想要声明“批归一化是有害的”的观点,但无奈找不到太好的理由,毕竟批归一化实在太有用了。
没错,批归一化的确存在问题。但当你做的一切都正确时,模型的确训练地快的多。批归一化的论文有超过 1400 次的引用不是白来的。
批归一化有很多的替代方法,但它们也有自己的不足。层归一化(Layer Normalization)与 RNN 合用才更有效,而且用于卷积层有时会有问题。权重归一化(Weight Normalization)和余弦归一化(Cosine Normalization)都是比较新型的归一化方法。权重归一化文章中表示,权重归一化能够适用于一些批归一化不起作用的问题上。但是这些方法迄今为止并没有太多应用,或许这只是个时间问题。层归一化,权重归一化和余弦归一化都解决了上述批归一化的问题。如果你在做一个新问题而且想冒点险的话,推荐试一下这些归一化方法。毕竟不论用哪一种方法,都需要做超参数调整。调整好后,各种方法之间的区别应该是不大的。
(如果你足够勇敢的话,甚至可以尝试批重归一化(Batch Renormalization),不过它仍然只在测试时使用移动平均值。 )
使用批归一化可以看作是深度学习中的“魔鬼的契约”。换来的是高效的训练,失去的是可能的不正常的结果(insanity)。每个人都在签着这个契约。
译者注
作者关于”批归一化是有害的“,以及“尽可能不使用批归一化”的观点不免有些偏激。但文中提到的批归一化的陷阱的确是不得不防的。因为批归一化的有效性,很多深度学习的研究者的确将其当作是“魔法黑箱”,将其应用到每一个可以用的地方。因为这种简单粗暴的方法对于训练速度的提高是很有效的。但大家很难将准确率的降低归咎于批归一化,毕竟从没有见人提到过批归一化会降低训练准确率。
但这种训练测试时数据集不一致的情况的确是很常见的。译者做的人工模拟训练数据集的方法中就会遇到这种问题。建议大家在使用批归一化之前仔细考虑这样几个问题:
- 我的训练数据集的每批样本是否平均?
- 我的训练数据集的每批均值是否和测试时的移动平均一致?
否则的话,就有必要使用下面中的一种或几种方法来避免文中的问题:
- 随机采样训练数据集来确保批次平均;
- 像文中的例子一样修改模型来避免上述问题;
- 使用层归一化,权重归一化或者余弦归一化来替代批归一化;
- 不使用归一化方法。