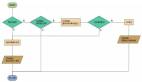
针对浏览器的http缓存的分析也算是老生常谈了,每隔一段时间就会冒出一篇不错的文章,其原理也是各大公司面试时几乎必考的问题。
之所以还写一篇这样的文章,是因为近期都在搞新技术,想“回归”下基础,也希望尽量总结的更详尽些。
那么你是否还需要阅读本篇文章呢?可以试着回答下面这个问题:
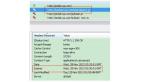
我们在访问百度首页的时候,会发现不管怎么刷新页面,静态资源基本都是返回 200(from cache):
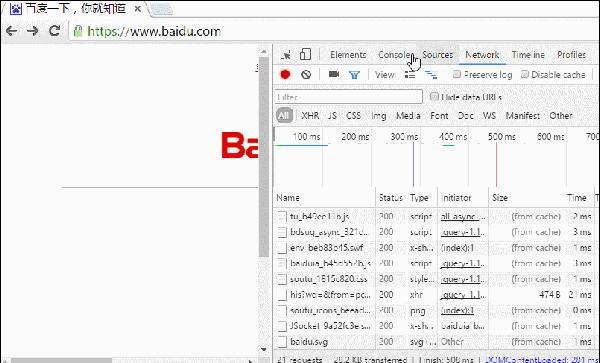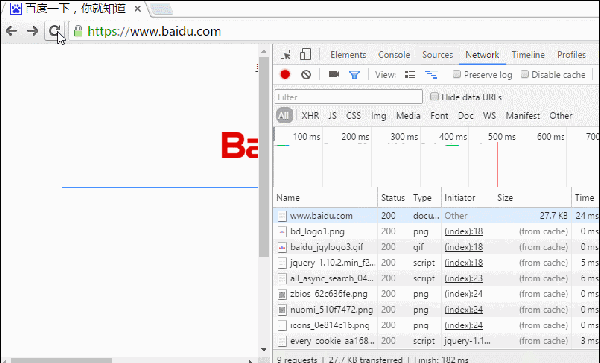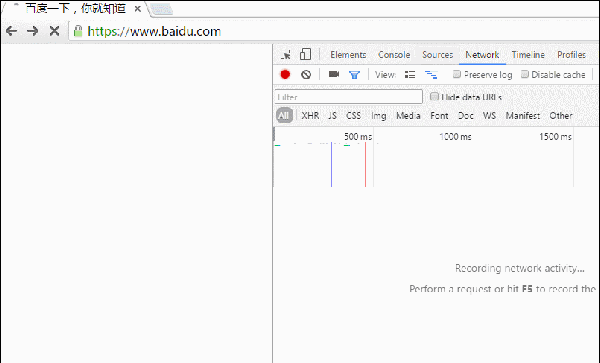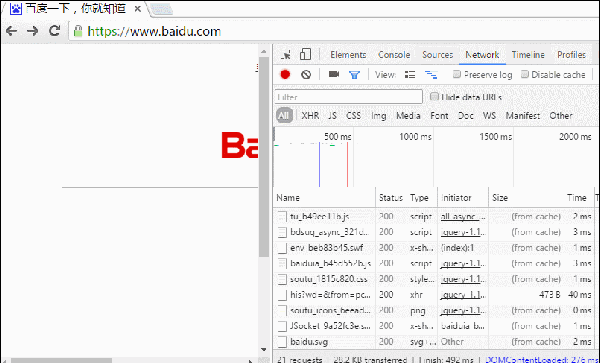
随便点开一个静态资源是酱的:
哎哟有Response报头数据呢,看来服务器也正常返回了etag什么鬼的应有尽有,那状态200不是应该对应的非缓存状态么?要from cache的话不是应该返回304才合理么?
难道是度娘的服务器故障了吗?
如果你知道答案,那就可以忽略本文了。
http报文中与缓存相关的首部字段
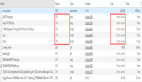
我们先来瞅一眼RFC2616规定的47种http报文首部字段中与缓存相关的字段,事先了解一下能让咱在心里有个底:
1. 通用首部字段(就是请求报文和响应报文都能用上的字段)
2. 请求首部字段
3. 响应首部字段
4. 实体首部字段
后续大体也会依次介绍它们。
场景模拟
为方便模拟各种缓存效果,我们建个非常简单的场景。
1. 页面文件
我们建个非常简单的html页面,上面只有一个本地样式文件和图片:
<!DOCTYPE html>
<html>
<head>
<title>缓存测试</title>
<link rel="stylesheet" href="css/reset.css">
</head>
<body>
<h1>哥只是一个标题</h1>
<p><img src="img/dog.jpg" /></p>
</body>
</html>
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
2. 首部字段修改
有时候一些浏览器会自行给请求首部加上一些字段(如chrome使用F5会强制加上“cache-control:max-age=0”),会覆盖掉一些字段(比如pragma)的功能;另外有时候我们希望服务器能多/少返回一些响应字段。
这种情况我们就希望可以手动来修改请求或响应报文上的内容了。那么如何实现呢?这里我们使用Fiddler来完成任务。
在Fiddler中我们可以通过“bpu XXX”指令来拦截指定请求,然后手动修改请求内容再发给服务器、修改响应内容再发给客户端。
以我们的example为例,页面文件走nginx通过 http://localhost/ 可直接访问,所以我们直接执行“bpu localhost”拦截所有地址中带有该字样的请求:
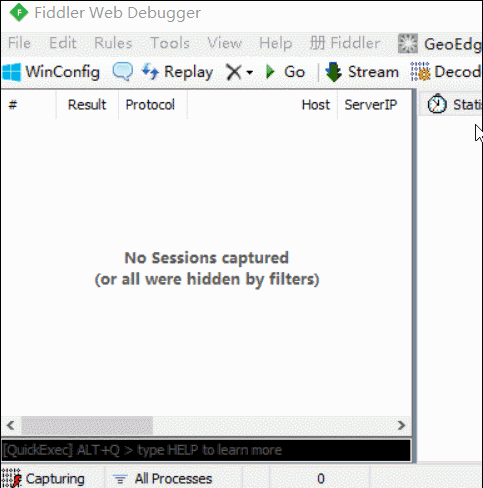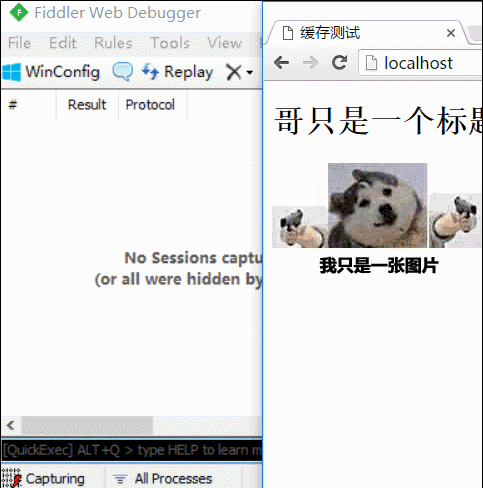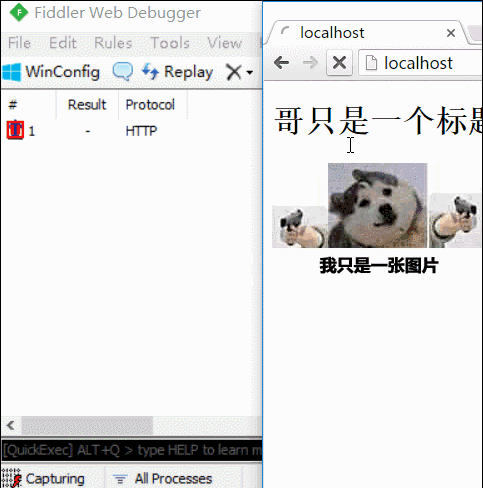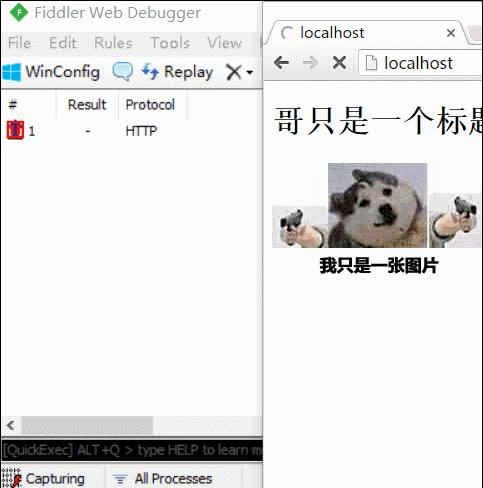
点击被拦截的请求,可以在右栏直接修改报文内容(上半区域是请求报文,下半区域是响应报文),点击黄色的“Break on Response”按钮可以执行下一步(把请求发给服务器),点击绿色的按钮“Run to Completion”可以直接完成整个请求过程:
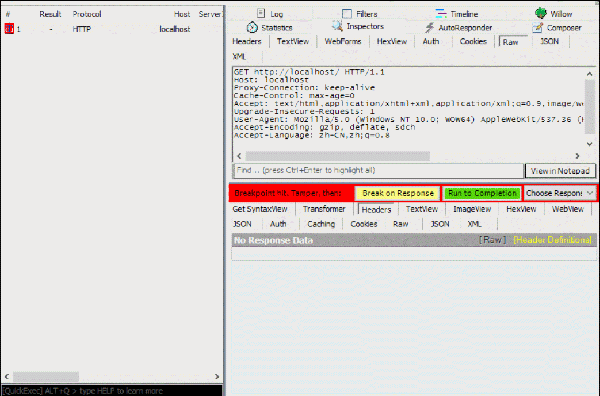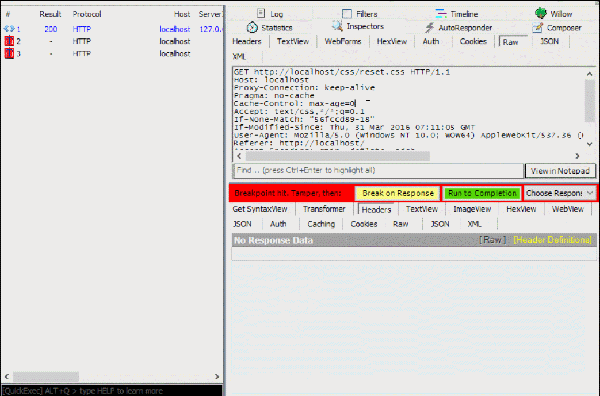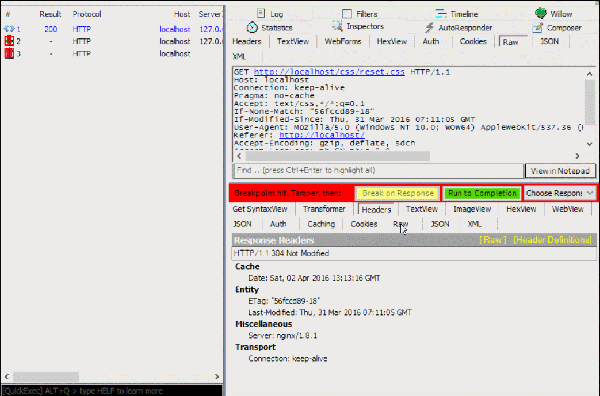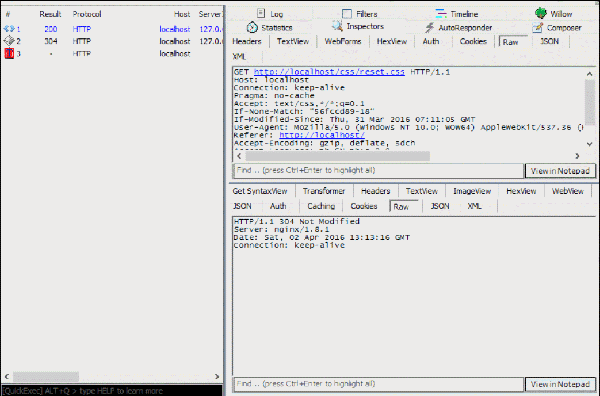
通过这个方法我们可以很轻松地模拟出各种http缓存场景。
3. 浏览器的强制策略
如上述,当下大多数浏览器在点击刷新按钮或按F5时会自行加上“Cache-Control:max-age=0”请求字段,所以我们先约定成俗——后文提及的“刷新”多指的是选中url地址栏并按回车键(这样不会被强行加上Cache-Control)。
事实上有的浏览器还有一些更奇怪的行为,在后续我们回答文章开头问题的时候会提到。
石器时代的缓存方式
在 http1.0 时代,给客户端设定缓存方式可通过两个字段——“Pragma”和“Expires”来规范。虽然这两个字段早可抛弃,但为了做http协议的向下兼容,你还是可以看到很多网站依旧会带上这两个字段。
1. Pragma
当该字段值为“no-cache”的时候(事实上现在RFC中也仅标明该可选值),会知会客户端不要对该资源读缓存,即每次都得向服务器发一次请求才行。
Pragma属于通用首部字段,在客户端上使用时,常规要求我们往html上加上这段meta元标签(而且可能还得做些hack放到body后面去):
<meta http-equiv="Pragma" content="no-cache">
- 1.
它告诉浏览器每次请求页面时都不要读缓存,都得往服务器发一次请求才行。
BUT!!! 事实上这种禁用缓存的形式用处很有限:
1. 仅有IE才能识别这段meta标签含义,其它主流浏览器仅能识别“Cache-Control: no-store”的meta标签(见出处)。
2. 在IE中识别到该meta标签含义,并不一定会在请求字段加上Pragma,但的确会让当前页面每次都发新请求(仅限页面,页面上的资源则不受影响)。
做了测试后发现也的确如此,这种客户端定义Pragma的形式基本没起到多少作用。
不过如果是在响应报文上加上该字段就不一样了:
如上图红框部分是再次刷新页面时生成的请求,这说明禁用缓存生效,预计浏览器在收到服务器的Pragma字段后会对资源进行标记,禁用其缓存行为,进而后续每次刷新页面均能重新发出请求而不走缓存。
2. Expires
有了Pragma来禁用缓存,自然也需要有个东西来启用缓存和定义缓存时间,对http1.0而言,Expires就是做这件事的首部字段。
Expires的值对应一个GMT(格林尼治时间),比如“Mon, 22 Jul 2002 11:12:01 GMT”来告诉浏览器资源缓存过期时间,如果还没过该时间点则不发请求。
在客户端我们同样可以使用meta标签来知会IE(也仅有IE能识别)页面(同样也只对页面有效,对页面上的资源无效)缓存时间:
<meta http-equiv="expires" content="mon, 18 apr 2016 14:30:00 GMT">
如果希望在IE下页面不走缓存,希望每次刷新页面都能发新请求,那么可以把“content”里的值写为“-1”或“0”。
注意的是该方式仅仅作为知会IE缓存时间的标记,你并不能在请求或响应报文中找到Expires字段。
如果是在服务端报头返回Expires字段,则在任何浏览器中都能正确设置资源缓存的时间:
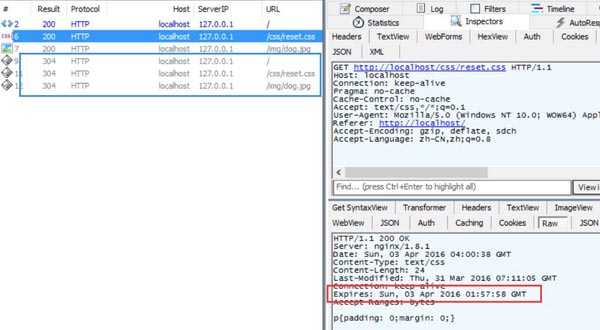
在上图里,缓存时间设置为一个已过期的时间点(见红框),则刷新页面将重新发送请求(见蓝框)。
那么如果Pragma和Expires一起上阵的话,听谁的?我们试一试就知道了:
我们通过Pragma禁用缓存,又给Expires定义一个还未到期的时间(红框),刷新页面时发现均发起了新请求(蓝框),这意味着Pragma字段的优先级会更高。
BUT,响应报文中Expires所定义的缓存时间是相对服务器上的时间而言的,如果客户端上的时间跟服务器上的时间不一致(特别是用户修改了自己电脑的系统时间),那缓存时间可能就没啥意义了。
Cache-Control
针对上述的“Expires时间是相对服务器而言,无法保证和客户端时间统一”的问题,http1.1新增了 Cache-Control 来定义缓存过期时间,若报文中同时出现了 Pragma、Expires 和 Cache-Control,会以 Cache-Control 为准。
Cache-Control也是一个通用首部字段,这意味着它能分别在请求报文和响应报文中使用。在RFC中规范了 Cache-Control 的格式为:
"Cache-Control" ":" cache-directive
作为请求首部时,cache-directive 的可选值有:
作为响应首部时,cache-directive 的可选值有:
我们依旧可以在HTML页面加上meta标签来给请求报头加上 Cache-Control 字段:
另外 Cache-Control 允许自由组合可选值,例如:
Cache-Control: max-age=3600, must-revalidate
它意味着该资源是从原服务器上取得的,且其缓存(新鲜度)的有效时间为一小时,在后续一小时内,用户重新访问该资源则无须发送请求。
当然这种组合的方式也会有些限制,比如 no-cache 就不能和 max-age、min-fresh、max-stale 一起搭配使用。
组合的形式还能做一些浏览器行为不一致的兼容处理。例如在IE我们可以使用 no-cache 来防止点击“后退”按钮时页面资源从缓存加载,但在 Firefox 中,需要使用 no-store 才能防止历史回退时浏览器不从缓存中去读取数据,故我们在响应报头加上如下组合值即可做兼容处理:
Cache-Control: no-cache, no-store
缓存校验字段
上述的首部字段均能让客户端决定是否向服务器发送请求,比如设置的缓存时间未过期,那么自然直接从本地缓存取数据即可(在chrome下表现为200 from cache),若缓存时间过期了或资源不该直接走缓存,则会发请求到服务器去。
我们现在要说的问题是,如果客户端向服务器发了请求,那么是否意味着一定要读取回该资源的整个实体内容呢?
我们试着这么想——客户端上某个资源保存的缓存时间过期了,但这时候其实服务器并没有更新过这个资源,如果这个资源数据量很大,客户端要求服务器再把这个东西重新发一遍过来,是否非常浪费带宽和时间呢?
答案是肯定的,那么是否有办法让服务器知道客户端现在存有的缓存文件,其实跟自己所有的文件是一致的,然后直接告诉客户端说“这东西你直接用缓存里的就可以了,我这边没更新过呢,就不再传一次过去了”。
为了让客户端与服务器之间能实现缓存文件是否更新的验证、提升缓存的复用率,Http1.1新增了几个首部字段来做这件事情。
1. Last-Modified
服务器将资源传递给客户端时,会将资源最后更改的时间以“Last-Modified: GMT”的形式加在实体首部上一起返回给客户端。
客户端会为资源标记上该信息,下次再次请求时,会把该信息附带在请求报文中一并带给服务器去做检查,若传递的时间值与服务器上该资源最终修改时间是一致的,则说明该资源没有被修改过,直接返回304状态码即可。
至于传递标记起来的最终修改时间的请求报文首部字段一共有两个:
⑴ If-Modified-Since: Last-Modified-value
示例为 If-Modified-Since: Thu, 31 Mar 2016 07:07:52 GMT
该请求首部告诉服务器如果客户端传来的最后修改时间与服务器上的一致,则直接回送304 和响应报头即可。
当前各浏览器均是使用的该请求首部来向服务器传递保存的 Last-Modified 值。
⑵ If-Unmodified-Since: Last-Modified-value
告诉服务器,若Last-Modified没有匹配上(资源在服务端的最后更新时间改变了),则应当返回412(Precondition Failed) 状态码给客户端。
当遇到下面情况时,If-Unmodified-Since 字段会被忽略:
1. Last-Modified值对上了(资源在服务端没有新的修改);
2. 服务端需返回2XX和412之外的状态码;
3. 传来的指定日期不合法
Last-Modified 说好却也不是特别好,因为如果在服务器上,一个资源被修改了,但其实际内容根本没发生改变,会因为Last-Modified时间匹配不上而返回了整个实体给客户端(即使客户端缓存里有个一模一样的资源)。
2. ETag
为了解决上述Last-Modified可能存在的不准确的问题,Http1.1还推出了 ETag 实体首部字段。
服务器会通过某种算法,给资源计算得出一个唯一标志符(比如md5标志),在把资源响应给客户端的时候,会在实体首部加上“ETag: 唯一标识符”一起返回给客户端。
客户端会保留该 ETag 字段,并在下一次请求时将其一并带过去给服务器。服务器只需要比较客户端传来的ETag跟自己服务器上该资源的ETag是否一致,就能很好地判断资源相对客户端而言是否被修改过了。
如果服务器发现ETag匹配不上,那么直接以常规GET 200回包形式将新的资源(当然也包括了新的ETag)发给客户端;如果ETag是一致的,则直接返回304知会客户端直接使用本地缓存即可。
那么客户端是如何把标记在资源上的 ETag 传去给服务器的呢?请求报文中有两个首部字段可以带上 ETag 值:
⑴ If-None-Match: ETag-value
示例为 If-None-Match: "56fcccc8-1699"
告诉服务端如果 ETag 没匹配上需要重发资源数据,否则直接回送304 和响应报头即可。
当前各浏览器均是使用的该请求首部来向服务器传递保存的 ETag 值。
⑵ If-Match: ETag-value
告诉服务器如果没有匹配到ETag,或者收到了“*”值而当前并没有该资源实体,则应当返回412(Precondition Failed) 状态码给客户端。否则服务器直接忽略该字段。
If-Match 的一个应用场景是,客户端走PUT方法向服务端请求上传/更替资源,这时候可以通过 If-Match 传递资源的ETag。
需要注意的是,如果资源是走分布式服务器(比如CDN)存储的情况,需要这些服务器上计算ETag唯一值的算法保持一致,才不会导致明明同一个文件,在服务器A和服务器B上生成的ETag却不一样。
如果 Last-Modified 和 ETag 同时被使用,则要求它们的验证都必须通过才会返回304,若其中某个验证没通过,则服务器会按常规返回资源实体及200状态码。
缓存实践
当我们在一个项目上做http缓存的应用时,我们还是会把上述提及的大多数首部字段均使用上,例如使用 Expires 来兼容旧的浏览器,使用 Cache-Control 来更精准地利用缓存,然后开启 ETag 跟 Last-Modified 功能进一步复用缓存减少流量。
那么这里会有一个小问题——Expires 和 Cache-Control 的值应设置为多少合适呢?
答案是不会有过于精准的值,均需要进行按需评估。
例如页面链接的请求常规是无须做长时间缓存的,从而保证回退到页面时能重新发出请求,百度首页是用的 Cache-Control:private,腾讯首页则是设定了60秒的缓存,即 Cache-Control:max-age=60。
而静态资源部分,特别是图片资源,通常会设定一个较长的缓存时间,而且这个时间最好是可以在客户端灵活修改的。以腾讯的某张图片为例:
http://i.gtimg.cn/vipstyle/vipportal/v4/img/common/logo.png?max_age=2592000
客户端可以通过给图片加上“max_age”的参数来定义服务器返回的缓存时间:
当然这需要有一个前提——静态资源能确保长时间不做改动。如果一个脚本文件响应给客户端并做了长时间的缓存,而服务端在近期修改了该文件的话,缓存了此脚本的客户端将无法及时获得新的数据。
解决该困扰的办法也简单——把服务侧ETag的那一套也搬到前端来用——页面的静态资源以版本形式发布,常用的方法是在文件名或参数带上一串md5或时间标记符:
https://hm.baidu.com/hm.js?e23800c454aa573c0ccb16b52665ac26
http://tb1.bdstatic.com/tb/_/tbean_safe_ajax_94e7ca2.js
http://img1.gtimg.com/ninja/2/2016/04/ninja145972803357449.jpg
如果文件被修改了,才更改其标记符内容,这样能确保客户端能及时从服务器收取到新修改的文件。
关于开头的问题
现在回过头来看文章开头的问题,可能会觉得答案很容易回答出来。
百度首页的资源在刷新后实际没有发送任何请求,因为 Cache-Control 定义的缓存时间段还没到期。在Chrome中即使没发送请求,但只要从本地的缓存中取,都会在Network面板显示一条状态为200且注明“from cache”的伪请求,其Response内容只是上一次回包留下的数据。
然而这并不是问题的全部答案,我们前面提到过,在Chrome中如果点击“刷新”按钮,Chrome会强制给所有资源加上“Cache-Control: max-age=0”的请求首部并向服务器发送验证请求的,而在文章开头的动图中,我们的确点击了“刷新”按钮,却不见浏览器发去新请求(并返回304)。
关于这个问题其实在组内跟小伙伴们讨论过,通过Fiddler抓包发现,如果关闭Chrome的开发者面板再点击“刷新”按钮,浏览器是会按预期发送验证请求且接收返回的304响应的,另外这个奇怪的情况在不同的网站甚至不同的电脑下出现频率都不一致,所以暂时将其归咎于浏览器的怪异反应。
那么有这么一个问题——是否有办法在浏览器点击“刷新”按钮的时候不让浏览器去发新的验证请求呢?
办法还是有的,就是不怎么实用——在页面加载完毕后通过脚本动态地添加资源:
$(window).load(function() {
var bg='http://img.infinitynewtab.com/wallpaper/100.jpg';
setTimeout(function() { //setTimeout是必须的
$('#bgOut').css('background-image', 'url('+bg+')');
},0);
});
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
出处来自知乎,更具体的解释可以去看看。
其它相关的首部字段
事实上较常用和重要的缓存相关字段我们都介绍完了,这里顺带讲讲几个跟缓存有关系,但没那么主要的响应首部字段。
1. Vary
“vary”本身是“变化”的意思,而在http报文中更趋于是“vary from”(与。。。不同)的含义,它表示服务端会以什么基准字段来区分、筛选缓存版本。
我们先考虑这么一个问题——在服务端有着这么一个地址,如果是IE用户则返回针对IE开发的内容,否则返回另一个主流浏览器版本的内容。这很简单,服务端获取到请求的 User-Agent 字段做处理即可。但是用户请求的是代理服务器而非原服务器,且代理服务器如果直接把缓存的IE版本资源发给了非IE的客户端,这就出问题了。
因此 Vary 便是着手处理该问题的首部字段,我们可以在响应报文加上:
Vary: User-Agent
- 1.
便能知会代理服务器需要以 User-Agent 这个请求首部字段来区别缓存版本,防止传递给客户端的缓存不正确。
Vary 也接受条件组合的形式:
Vary: User-Agent, Accept-Encoding
- 1.
这意味着服务器应以 User-Agent 和 Accept-Encoding 两个请求首部字段来区分缓存版本。
2. Date 和 Age
HTTP并没有提供某种方法来帮用户区分其收到的资源是否命中了代理服务器的缓存,但在客户端我们可以通过计算响应报文中的 Date 和 Age 字段来得到答案。
Date 理所当然是原服务器发送该资源响应报文的时间(GMT格式),如果你发现 Date 的时间与“当前时间”差别较大,或者连续F5刷新发现 Date 的值都没变化,则说明你当前请求是命中了代理服务器的缓存。
上述的“当前时间”自然是相对于原服务器而言的时间,那么如何获悉原服务器的当前时间呢?
常规从页面地址请求的响应报文中可获得,以博客园首页为例:
每次你刷新页面,浏览器都会重新发出这条url的请求,你会发现其 Date 值是不断变化的,这说明该链接没有命中缓存,都是从原服务器返回过来的数据。
因此我们可以拿页面上其它静态资源请求回包中的 Date 与其进行对比,若静态资源的 Date 早于原服务端时间,则说明命中了代理服务器缓存。
通常还满足这么个条件:
静态资源Age + 静态资源Date = 原服务端Date
这里的 Age 也是响应报文中的首部字段,它表示该文件在代理服务器中存在的时间(秒),如文件被修改或替换,Age会重新由0开始累计。
我们在上面那张博客园首页报文截图的同个场景下,看看某个文件(jQuery.js)命中代理服务器缓存的回包数据:
会发现它满足我们上述的规则:
//return true
new Date('Mon, 04 Apr 2016 07:03:17 GMT')/1000 == new Date('Sat, 19 Dec 2015 01:29:14 GMT')/1000 + 9264843
- 1.
- 2.
- 3.
不过这条规则也不一定准确,特别是当原服务器经常修改系统时间的情况下。
关于http缓存原理的知识就整理到这,希望能让你有所收获,共勉~