在使用Impala这种所谓大数据引擎的时候,总会感觉有些地方设计的不是那么尽善尽美,比如说缓存,Impala的查询结果是没有经过缓存的,也就是说每次都相当于需要重新对文件执行一遍查询。
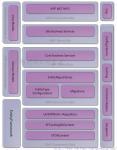
MySQL基本架构如下图,是MySQL的逻辑架构图:

最上层的服务并不是MySQL所独有的,大多数基于网络的客户端/服务器的工具或者服务都有类似的架构,比如连接处理、授权认证、安全等等。
第二层架构是MySQL比较有意思的部分大多数MySQL的核心服务功能都在这一层。包括查询解析、分析、优化、缓存以及所有的内置函数,所有跨存储引擎的功能都在这一层实现:存储过程、触发器、视图等。
第三层包含了存储引擎。存储引擎负责MySQL中数据的存储和提取。和GNU/Linux下的各种文件系统一样,每个存储引擎都有它的优势和劣势。服务器通过API与存储引擎进行通信。这些接口屏蔽了不同存储引擎之间的差异。
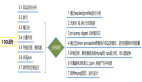
下面挑几个模块解释一下:
1.解析器
SQL命令传递到解析器的时候会被解析器验证和解析。解析器是由Lex和YACC实现的,是一个很长的脚本。
主要功能:
将SQL语句分解成数据结构,并将这个结构传递到后续步骤,以后SQL语句的传递和处理就是基于这个结构的
如果在分解构成中遇到错误,那么就说明这个sql语句是不合理的
2.优化器
SQL语句在查询之前会使用查询优化器对查询进行优化。他使用的是“选取-投影-联接”策略进行查询。
用一个例子就可以理解:select uid,name from user where gender = 1;
这个select 查询先根据where 语句进行选取,而不是先将表全部查询出来以后再进行gender过滤
这个select查询先根据uid和name进行属性投影,而不是将属性全部取出以后再进行过滤
将这两个查询条件联接起来生成最终查询结果。
3.缓存
如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据。
这个缓存机制是由一系列小缓存组成的。比如表缓存,记录缓存,key缓存,权限缓存等。
补充知识
1.查询优化和执行(Optimization and Execution)
MySQL将用户的查询语句进行解析,并创建一个内部的数据结构——分析树,然后进行各种优化,例如重写查询、选择读取表的顺序,以及使用哪个索引等。
查询优化器不关心一个表所使用的存储引擎,但是存储引擎会影响服务器如何优化查询。优化器通过存储引擎获取一些参数、某个操作的执行代价、以及统计信息等。在解析查询之前,服务器会先访问查询缓存(query cache)——它存储SELECT语句以及相应的查询结果集。如果某个查询结果已经位于缓存中,服务器就不会再对查询进行解析、优化、以及执行。它仅仅将缓存中的结果返回给用户即可,这将大大提高系统的性能。
2.并发控制(锁粒度)
MySQL提供两个级别的并发控制:服务器级(the server level)和存储引擎级(the storage engine level)。加锁是实现并发控制的基本方法,MySQL中锁的粒度:
表级锁:MySQL独立于存储引擎提供表锁,例如,对于ALTER TABLE语句,服务器提供表锁(table-level lock)。
行级锁:InnoDB和Falcon存储引擎提供行级锁,此外,BDB支持页级锁。InnoDB的并发控制机制,下节详细讨论。
另外,值得一提的是,MySQL的一些存储引擎(如InnoDB、BDB)除了使用封锁机制外,还同时结合MVCC机制,即多版本两阶段封锁协议(Multiversion two-phrase locking protocal),来实现事务的并发控制,从而使得只读事务不用等待锁,提高了事务的并发性。
注意: 行级锁只在存储引擎层实现,而MySQL服务器层没有实现。服务器层完全不了解存储引种的锁实现。
3.事务
MySQL中,InnoDB和BDB都支持事务处理。这里主要讨论InnoDB的事务处理。
事务的ACID特性:
事务是由一组SQL语句组成的逻辑处理单元,事务具有以下4个属性,通常简称为事务的ACID属性。
原子性(Atomicity):事务是一个原子操作单元,其对数据的修改,要么全都执行,要么全都不执行。
一致性(Consistent):在事务开始和完成时,数据都必须保持一致状态。这意味着所有相关的数据规则都必须应用于事务的修改,以保持数据的完整性;事务结束时,所有的内部数据结构(如B树索引或双向链表)也都必须是正确的。
隔离性(Isolation):数据库系统提供一定的隔离机制,保证事务在不受外部并发操作影响的“独立”环境执行。这意味着事务处理过程中的中间状态对外部是不可见的,反之亦然。
持久性(Durable):事务完成之后,它对于数据的修改是永久性的,即使出现系统故障也能够保持。
事务处理带来的相关问题:
由于事务的并发执行,带来以下一些著名的问题:
更新丢失(Lost Update):当两个或多个事务选择同一行,然后基于最初选定的值更新该行时,由于每个事务都不知道其他事务的存在,就会发生丢失更新问题--最后的更新覆盖了由其他事务所做的更新。
脏读(Dirty Reads):一个事务正在对一条记录做修改,在这个事务完成并提交前,这条记录的数据就处于不一致状态;这时,另一个事务也来读取同一条记录,如果不加控制,第二个事务读取了这些“脏”数据,并据此做进一步的处理,就会产生未提交的数据依赖关系。这种现象被形象地叫做”脏读”。
不可重复读(Non-Repeatable Reads):一个事务在读取某些数据后的某个时间,再次读取以前读过的数据,却发现其读出的数据已经发生了改变、或某些记录已经被删除了!这种现象就叫做“不可重复读”。
幻读(Phantom Reads):一个事务按相同的查询条件重新读取以前检索过的数据,却发现其他事务插入了满足其查询条件的新数据,这种现象就称为“幻读”。