一、前言
现在网上有很多被动式扫描器,配置一个代理给浏览器设置,然后人去点击浏览器上的网页,在这种模式下抓到的URL数量没有用爬虫的效果好。
我个人是比较懒的,先也写了个被动的扫描器,不想改以前写的东西,而且被动也有被动的优点,所以就想可不可以让爬虫也设置个代理。就有了下面的东西,很方便。
二、实操
如何在不改变原被动扫描器的情况下让被动变成主动。
主结构:
以phantomjs为核心,用JS模仿人对页面的操作,代理软件抓链接。以下流程是通用pychon脚本实现的。
1打开浏览器并设置代理->2输入网址->3填充表单->4点击按钮->5点击超链拉->6关闭标签->7关闭浏览器,循环2-6。
1. 打开浏览器并设置代理
- proxy_config = [
- '--proxy=127.0.0.1:8080',
- '--proxy-type=http',
- '--ignore-ssl-errors=yes',
- ]
- phantomjs_path='/home/ubuntu_235/proxyscan/phantomjs/phantomjs/bin/phantomjs'
- driver = webdriver.PhantomJS(executable_path=phantomjs_path,service_args=sys_config)
2. 输入网址
- driver.get('http://demo.aisec.cn')
3. 填充表单
- _input_text = """
- var input_list=document.getElementsByTagName("input");
- for (i_i=0;i_i<input_list.length;i_i++){
- var input_type=input_list[i_i].attributes["type"].value
- if (input_type == "text" || input_type == "password"){
- input_list[i_i].value="ascan@ascan.com";
- continue;
- }
- if (input_type == "radio" || input_type == "checkbox"){
- input_list[i_i].setAttribute('target','_blank');
- input_list[i_i].checked="True";
- }
- }
- """
4. 点击按钮
- _but_click = """
- var but_list=document.getElementsByTagName("input");
- for (b_i=0;b_i<but_list.length;b_i++){
- var but_type=but_list[b_i].attributes["type"].value
- if (but_type == "button" || but_type == "submit"){
- but_list[b_i].setAttribute('target','_blank');
- but_list[b_i].click();
- }
- }
- """
5. 点击超链接
- _a_click = """
- var a_list=document.getElementsByTagName("a");
- for (a_i=0;a_i<a_list.length;a_i++){
- a_list[a_i].setAttribute('target','_blank');
- a_list[a_i].click();
- }
- """
这里注意下,我在click前给标签加了一个target=”_blank”,在新的标签页打开链接
6. 关闭标签
- for h in driver.window_handles[1:]:
- driver.switch_to_window(h)
- driver.close()
注意:应该先获取有标签页的handle在用switch_to_window
切换到该标签页,执行quit()操作。driver.window_handles[1:]保留的是第一个页面。
在完成所有操作后关闭浏览器
- driver.close()
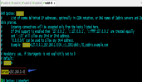
通过burpsuite抓到的请求包

最终实现的结果展示

一些注意点:
如何获取当前页面的所有标签的href?
- url_list=[]
- a_list=self.driver.find_elements_by_xpath("//a[@href]")
- for a in a_list:
- url_list.append(a.get_attribute("href"))
- print(url_list)
如何获取当前标签的URL? 有什么坑? a.浏览器打页面要时间,但python不知道(不是真不知道) b.会不明原因的卡死,没有报错 c.页面跳转