本篇文章介绍使用python抓取贷款及理财平台的数据,并将数据拼接和汇总。最终通过tableau进行可视化。与之前的python爬虫文章 不同之处在于之前是一次性抓取生产数据表,本次的数据需要每天重复抓取及存储,并汇总在一起进行分析和可视化。

开始前的准备工作
开始之前先导入所需使用的库文件,各个库文件在整个抓取和拼表过程中负责不同的部分。Requests负责页面抓取,re负责从抓取下
来的页面中提取有用的信息,pandas负责拼接并生成数据表以及最终的数据表导出。
- </pre>
- #导入requests库(请求和页面抓取)
- import requests
- #导入正则库(从页面代码中提取信息)
- import re
- #导入科学计算库(拼表及各种分析汇总)
- import pandas as pd
- <pre>
设置一个头文件信息,方便后面的抓取。这个头文件有两个作用,第一防止抓取时被封,第二方便后面对页面源文件的转码。
- </pre>
- #设置请求中头文件的信息
- headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64
- Safari/537.11',
- 'Accept':'text/html;q=0.9,*/*;q=0.8',
- 'Accept-Charset':'ISO-8859-1,utf-8;q=0.7,*;q=0.3',
- 'Connection':'close',
- 'Referer':'https://www.bluewhale.cc/'
- }
- <pre>
抓取贷款及理财信息
准备工作完成后开始对贷款和理财信息进行抓取,这里我们偷个懒,直接抓取p2peye.com的信息。p2peye.com是一个网贷咨询及数据
平台,内容很丰富。他们定期更新各平台的贷款及理财数据。
因为所有的网贷平台信息都在一页上,所以抓取起来比较简单,不需要翻页。下面是抓取并保存页面信息的代码。
- </pre>
- #抓取并保存页面信息
- r=requests.get('http://www.p2peye.com/shuju/ptsj/',headers=headers)
- html=r.content
- <pre>
抓取下来的信息需要进行转码才能变成有用的信息,下面对页面源代码进行GBK转码。
- </pre>
- #对抓取的页面进行编码
- html=str(html, encoding = "GBK")
- <pre>
查看一下转码后的页面,我们需要的信息都包含在里面了。后面只需要使用正则表达式逐个提取出来就可以了。
- </pre>
- #查看抓取的页面源码
- html
- <pre>

提取信息并进行数据清洗
使用正则表达式对应着页面中的字段逐个将关键数据从页面源码中提取出来,下面是具体的过程,首先提取的是平台名称字段。在页
面源码中平台名称在title中。
- </pre>
- #使用正则提取title字段信息
- title=re.findall(r'"return false".*?title="(.*?)"',html)
- <pre>
提取后查看下结果,内容很干净,不需要进行清洗可以直接使用。
- </pre>
- #查看title字段信息
- title
- <pre>

这里有一点要注意的是每个提取出来的字段最好都要检查下,并且查看下数据的条目。因为有时候提取的条目中包含有其他的信息,
导致字段间条目数量不一致,这种情况下后面是无法拼接成数据表的。
- </pre>
- #查看title字段数量
- len(title)
- 607
- <pre>
按照提取平台名称title的方法,后面我们依次提取了贷款利率,贷款金额,满标时间等关键信息。下面是具体的代码。
- </pre>
- #使用正则提取total字段信息
- total=re.findall(r'"total">(.*?)万<',html)
- #使用正则提取rate字段信息
- rate=re.findall(r'"rate">(.*?)<',html)
- #使用正则提取pnum字段信息
- pnum=re.findall(r'"pnum">(.*?)人<',html)
- #使用正则提取cycle字段信息
- cycle=re.findall(r'"cycle">(.*?)月<',html)
- #使用正则提取plnum字段信息
- p1num=re.findall(r'"p1num">(.*?)人<',html)
- #使用正则提取fuload字段信息
- fuload=re.findall(r'"fuload">(.*?)分钟<',html)
- #使用正则提取alltotal字段信息
- alltotal=re.findall(r'"alltotal">(.*?)万<',html)
- #使用正则提取captial字段信息
- capital=re.findall(r'"capital">(.*?)万<',html)
- <pre>
由于后面我们要对数据进行累计追加及趋势分析,因此在这里导入time库生成当天的日期,并将日期作为一个字段一起放在数据表。
- </pre>
- #导入time库(获取日期)
- import time
- date=time.strftime('%Y-%m-%d',time.localtime(time.time()))
- <pre>
- 当天的日期信息将和数据一起生成数据表。
- </pre>
- #日期
- date
- '2017-04-13'
- <pre>
创建贷款及理财数据表
将前面提取出来的数据和日期信息一起生成数据表,首先使用columns参数设置数据表中各字段的排列顺序。
- </pre>
- #设置数据表各字段顺序
- columns = ['采集日期','平台名称','成交额(万)','综合利率','投资人(人)','借款周期(月)','借款人(人)','满标速度(分钟)','
- 累计贷款余额(万)','净资金流入(万)']
- <pre>
然后设置各字段的名称,并生成数据表。
- </pre>
- #创建数据表
- table=pd.DataFrame({'采集日期':date,
- '平台名称':title,
- '成交额(万)':total,
- '综合利率':rate,
- '投资人(人)':pnum,
- '借款周期(月)':cycle,
- '借款人(人)':p1num,
- '满标速度(分钟)':fuload,
- '累计贷款余额(万)':alltotal,
- '净资金流入(万)':capital},
- columns=columns)
- <pre>
查看生成的数据表,字段顺序与我们设置的一致,下一步把数据表导出为csv文件。便于后续的处理和分析。
- </pre>
- #查看数据表
- table
- <pre>
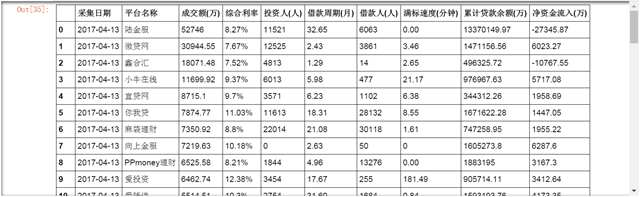
导出及追加数据
将生成的数据表导出为csv文件。这里有两种导出方式。第一是新建数据表。但比较麻烦,后续要需要手动将每天的数据进行拼接。因
此还有第二种导出方式就是在一个数据表中不断追加新数据。
第一种方式将数据表导出为一个新的csv文件,文件名为wdty加上数据抓取的具体日期,也就是date中的值。
- </pre>
- #导出csv文件
- table.to_csv('C:\\Users\\ Desktop\\wdty'+date+'.csv',index=False)
- <pre>
第二种方式是在一个csv文件中持续追加导出新的数据表。这里我们建立一个wdty的csv文件,每天抓取的数据都会追加到这个csv文件
中。代码与之前的新建csv文件类似,唯一的区别是增加了mode参数,这个参数默认值是w,也就是新建。把值改为a就是追加导出。
- </pre>
- #在历史csv文件中追加新信息
- table.to_csv('wdty.csv',index=False,mode='a')
- <pre>
以下是导出后的数据表截图。内容与前面创建的数据表内容一致。
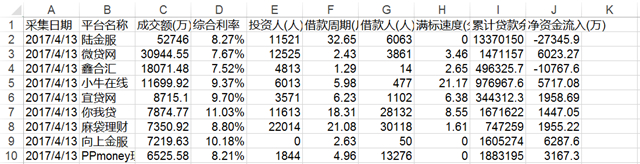
创建自定义函数
从导入所需的库文件,到提取数据拼接和导出,我们一共进行了30+步的操作。为了简化步骤,我们把这些步骤放在一个loan_data自
定义函数中。以后每次只需要执行以下这个自定义函数就可以将数据抓取下来并导出到csv里了。下面是具体的代码,其中为了获得代
码执行中的过程信息,我们在一些关键步骤后使用print输出了一些状态信息。并计算了整个代码执行所耗费的时间。
- </pre>
- def loan_data():
- import os
- import requests
- import re
- import pandas as pd
- import time
- start = time.clock()
- headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64
- Safari/537.11',
- 'Accept':'text/html;q=0.9,*/*;q=0.8',
- 'Accept-Charset':'ISO-8859-1,utf-8;q=0.7,*;q=0.3',
- 'Connection':'close',
- 'Referer':'https://www.bluewhale.cc/'
- }
- r=requests.get('http://www.p2peye.com/shuju/ptsj/',headers=headers)
- status=r.status_code
- if status == 200:
- print('页面抓取状态正常。')
- else:
- os._exit(0)
- html=r.content
- html=str(html, encoding = "GBK")
- print('编码转换完成!')
- title=re.findall(r'"return false".*?title="(.*?)"',html)
- total=re.findall(r'"total">(.*?)万<',html)
- rate=re.findall(r'"rate">(.*?)<',html)
- pnum=re.findall(r'"pnum">(.*?)人<',html)
- cycle=re.findall(r'"cycle">(.*?)月<',html)
- p1num=re.findall(r'"p1num">(.*?)人<',html)
- fuload=re.findall(r'"fuload">(.*?)分钟<',html)
- alltotal=re.findall(r'"alltotal">(.*?)万<',html)
- capital=re.findall(r'"capital">(.*?)万<',html)
- date=time.strftime('%Y-%m-%d',time.localtime(time.time()))
- print('数据提取完成!')
- columns = ['采集日期','平台名称','成交额(万)','综合利率','投资人(人)','借款周期(月)','借款人(人)','满标速度(分
- 钟)','累计贷款余额(万)','净资金流入(万)']
- table=pd.DataFrame({'采集日期':date,
- '平台名称':title,
- '成交额(万)':total,
- '综合利率':rate,
- '投资人(人)':pnum,
- '借款周期(月)':cycle,
- '借款人(人)':p1num,
- '满标速度(分钟)':fuload,
- '累计贷款余额(万)':alltotal,
- '净资金流入(万)':capital},
- columns=columns)
- print('数据表创建完成!')
- table.to_csv('C:\\Users\\cliffwang\\Desktop\\wdty'+date+'.csv',index=False)
- print(date+'日数据导出完毕!')
- table.to_csv('wdty.csv',index=False,mode='a')
- print('累计数据追加导出完毕!')
- end = time.clock()
- print ("执行时间: %f s" % (end-start))
- <pre>
自定义函数写好后,每次只需要执行loan_data()就可以完成之前的30+步骤的工作了。下面是代码和输出的状态信息以及代码执行时间信息。
- </pre>
- loan_data()
- 页面抓取状态正常。
- 编码转换完成!
- 数据提取完成!
- 数据表创建完成!
- 2017-04-19日数据导出完毕!
- 累计数据追加导出完毕!
- 执行时间: 0.933262 s
- <pre>
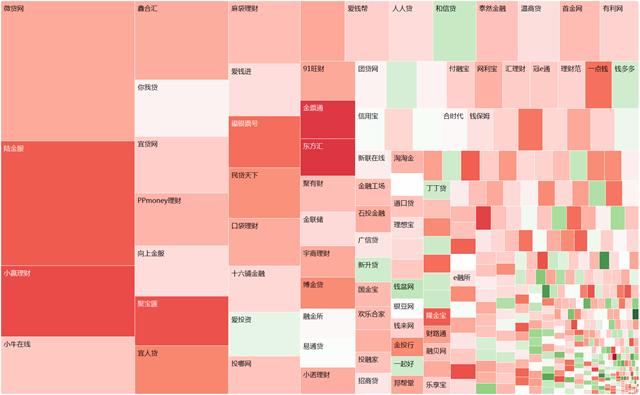
使用tableau进行可视化
导出的数据虽然为csv格式,但使用excel进行可视化并不理想,主要问题在于excel对图表行列数的限制(每张图最多只能容纳255个数
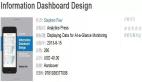
量列)。因此,我们将数据表导入到tableau中进行可视化。下面是对600+家网贷平台数据的可视化截图。尺寸为各平台总成交额,颜色为综合利率。
所有文章及图片版权归 蓝鲸(王彦平)所有。