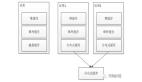
前面已经介绍了Java缓存的使用。对于我们来说如果有人总结一些缓存使用模式/模板的话,我们在使用时直接照着模式写即可。而实际确实已经有总结好的模式,主要分两大类:Cache-Aside和Cache-As-SoR(Read-through、Write-through、Write-behind)。
首先,同步两个名词。
- SoR(system-of-record):记录系统,或者可以叫做数据源,即实际存储原始数据的系统。
- Cache:缓存,是SoR的快照数据,Cache的访问速度比SoR要快,放入Cache的目的是提升访问速度,减少回源到SoR的次数。
- 回源:即回到数据源头获取数据,Cache没有***时,需要从SoR读取数据,这叫做回源。
本文主要以Guava Cache和Ehcache3.x作为实践框架来讲解。
一、Cache-Aside
Cache-Aside即业务代码围绕着Cache写,是由业务代码直接维护缓存,示例代码如下所示。
读场景,先从缓存获取数据,如果没有***,则回源到SoR并将源数据放入缓存供下次读取使用。
- //1、先从缓存中获取数据
- value = myCache.getIfPresent(key);
- if(value == null) {
- //2.1、如果缓存没有***,则回源到SoR获取源数据
- value = loadFromSoR(key);
- //2.2、将数据放入缓存,下次即可从缓存中获取数据
- myCache.put(key, value);
- }
写场景,先将数据写入SoR,写入成功后立即将数据同步写入缓存。
- //1、先将数据写入SoR
- writeToSoR(key,value);
- //2、执行成功后立即同步写入缓存
- myCache.put(key, value);
或者先将数据写入SoR,写入成功后将缓存数据过期,下次读取时再加载缓存。
- //1、先将数据写入SoR
- writeToSoR(key,value);
- //2、失效缓存,然后下次读时再加载缓存
- myCache.invalidate(key);
Cache-Aside适合使用AOP模式去实现,可以参考笔者的博客《Spring Cache抽象详解》去实现。
对于Cache-Aside可能存在并发更新情况,即如果多个应用实例同时更新,那么缓存怎么办?
● 如果是用户维度的数据(如订单数据、用户数据),则出现这种几率非常小,因为并发的情况很少,可以不考虑这个问题,加上过期时间来解决即可。
● 对于如商品这种基础数据,可以考虑使用canal订阅binlog进行增量更新分布式缓存,这样不会存在缓存数据不一致的情况,但是,缓存更新会存在延迟。而本地缓存根据不一致容忍度设置合理的过期时间。
● 读服务场景,可以考虑使用一致性哈希,将相同的操作负载均衡到同一个实例,从而减少并发几率。或者设置比较短的过期时间,可参考“第17章 京东商品详情页服务闭环实践”。
二、Cache-As-SoR
Cache-As-SoR即把Cache看作为SoR,所有操作都是对Cache进行,然后Cache再委托给SoR进行真实的读/写。即业务代码中只看到Cache的操作,看不到关于SoR相关的代码。有三种实现:read-through、write-through、write-behind。
1. Read-Through
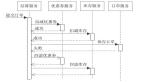
Read-Through,业务代码首先调用Cache,如果Cache不***由Cache回源到SoR,而不是业务代码(即由Cache读SoR)。使用Read-Through模式,需要配置一个CacheLoader组件用来回源到SoR加载源数据。Guava Cache和Ehcache 3.x都支持该模式。
Guava Cache实现
- LoadingCache<Integer,Result<Category>> getCache =
- CacheBuilder.newBuilder()
- .softValues()
- .maximumSize(5000).expireAfterWrite(2, TimeUnit.MINUTES)
- .build(new CacheLoader<Integer,Result<Category>>() {
- @Override
- public Result<Category> load(final Integer sortId) throwsException {
- return categoryService.get(sortId);
- }
- });
在build Cache时,传入一个CacheLoader用来加载缓存,操作流程如下。
- 应用业务代码直接调用getCache.get(sortId)。
- 首先查询Cache,如果缓存中有,则直接返回缓存数据。
- 如果缓存没有***,则委托给CacheLoader,CacheLoader会回源到SoR查询源数据(返回值必须不为null,可以包装为Null对象),然后写入缓存。
使用CacheLoader后有几个好处。
● 应用业务代码更简洁了,不需要像Cache-Aside模式那样缓存查询代码和SoR代码交织在一起。如果缓存使用逻辑散落在多处,则使用这种方式很简单的消除了重复代码。
● 解决Dog-pile effect,即当某个缓存失效时,又有大量相同的请求没***缓存,从而同时请求到后端,导致后端压力太大,此时限制一个请求去拿即可。
- if (firstCreateNewEntry) {//***个请求加载缓存的线程去SoR加载源数据
- try {
- synchronized (e) {
- returnloadSync(key, hash, loadingValueReference, loader);
- }
- } finally{
- statsCounter.recordMisses(1);
- }
- } else {//其他并发线程等待“***个线程”加载的数据
- return waitForLoadingValue(e, key,valueReference);
- }
- Guava Cache还支持get(K key, Callable<? extends V> valueLoader)方法,传入一个Callable实例,当缓存没***时,会调用Callable#call来查询SoR加载源数据。
- Ehcache 3.x实现
- CacheManager cacheManager = CacheManagerBuilder. newCacheManagerBuilder(). build(true);
- org.ehcache.Cache<String, String> myCache =cacheManager. createCache ("myCache",
- CacheConfigurationBuilder.newCacheConfigurationBuilder(String.class,String.class,
- ResourcePoolsBuilder.newResourcePoolsBuilder().heap(100,MemoryUnit.MB))
- .withDispatcherConcurrency(4)
- .withExpiry(Expirations.timeToLiveExpiration(Duration.of(10,TimeUnit.SECONDS)))
- .withLoaderWriter(newDefaultCacheLoaderWriter<String, String> () {
- @Override
- public String load(String key) throws Exception {
- return readDB(key);
- }
- @Override
- public Map<String, String> loadAll(Iterable<? extendsString> keys) throws BulkCacheLoadingException, Exception {
- return null;
- }
- }));
Ehcache 3.x使用CacheLoaderWriter来实现,通过load(K key)和loadAll(Iterable keys)分别来加载单个KEY和批量KEY。Ehcache 3.1没有自己去解决Dog-pile effect。
2. Write-Through
Write-Through,称之为穿透写模式/直写模式,业务代码首先调用Cache写(新增/修改)数据,然后由Cache负责写缓存和写SoR,而不是业务代码。使用Write-Through模式需要配置一个CacheWriter组件用来回写SoR。Guava Cache没有提供支持。Ehcache 3.x支持该模式。Ehcache需要配置一个CacheLoaderWriter,CacheLoaderWriter知道如何去写SoR。当Cache需要写(新增/修改)数据时,首先调用CacheLoaderWriter来同步(立即)到SoR,成功后会更新缓存。
- CacheManager cacheManager = CacheManagerBuilder.newCacheManagerBuilder().build(true);
- org.ehcache.Cache<String, String> myCache =cacheManager.createCache ("myCache",
- CacheConfigurationBuilder.newCacheConfigurationBuilder(String.class,String.class,
- ResourcePoolsBuilder.newResourcePoolsBuilder().heap(100,MemoryUnit.MB))
- .withDispatcherConcurrency(4)
- .withExpiry(Expirations.timeToLiveExpiration(Duration.of(10,TimeUnit.SECONDS)))
- .withLoaderWriter(newDefaultCacheLoaderWriter<String, String> () {
- @Override
- public void write(String key, String value) throws Exception{
- //write
- }
- @Override
- public void writeAll(Iterable<? extends Map.Entry<? extendsString, ? extends String>> entries) throws BulkCacheWritingException,Exception {
- for(Object entry: entries) {
- //batch write
- }
- }
- @Override
- public void delete(Stringkey) throws Exception {
- //delete
- }
- @Override
- public void deleteAll(Iterable<? extends String>keys) throws BulkCacheWritingException, Exception {
- for(Object key :keys) {
- //batch delete
- }
- }
- }).build());
Ehcache 3.x还是使用CacheLoaderWriter来实现,通过write(String key, String value)、writeAll(Iterable> entries)和delete(String key)、deleteAll(Iterable keys)分别来支持单个写、批量写和单个删除、批量删除操作。
操作流程如下。
- 当我们调用myCache.put("e","123")或者myCache.putAll(map)时,写缓存。
- 首先,Cache会将写操作立即委托给CacheLoaderWriter#write和#writeAll,然后由CacheLoaderWriter负责立即去写SoR。
- 当写SoR成功后,再写入Cache。
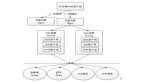
3. Write-Behind
Write-Behind,也叫Write-Back,称之为回写模式,不同于Write-Through是同步写SoR和Cache,Write-Behind是异步写。异步之后可以实现批量写、合并写、延时和限流。
(1) 异步写
- CacheManager cacheManager = CacheManagerBuilder. newCacheManagerBuilder()
- .using(PooledExecutionServiceConfigurationBuilder
- .newPooledExecutionServiceConfigurationBuilder()
- .pool("writeBehindPool", 1, 5)
- .build())
- .build(true);
- org.ehcache.Cache<String, String> myCache =cacheManager. createCache ("myCache",
- CacheConfigurationBuilder.newCacheConfigurationBuilder(String.class,String.class,
- ResourcePoolsBuilder.newResourcePoolsBuilder().heap(100,MemoryUnit.MB))
- .withDispatcherConcurrency(4)
- .withExpiry(Expirations.timeToLiveExpiration(Duration.of(10,TimeUnit.SECONDS)))
- .withLoaderWriter(new DefaultCacheLoaderWriter<String,String >() {
- @Override
- public void write(String key, String value) throws Exception{
- //write
- }
- @Override
- public void delete(String key) throws Exception {
- //delete
- }
- })
- .add(WriteBehindConfigurationBuilder
- .newUnBatchedWriteBehindConfiguration()
- .queueSize(5)
- .concurrencyLevel(2
- .useThreadPool("writeBehindPool")
- .build()));
几个重要配置如下。
- hreadPool:使用PooledExecutionServiceConfigurationBuilder配置线程池;然后WriteBehindConfigurationBuilder通过useThreadPool配置使用哪一个线程池;
- WriteBehindConfigurationBuilder:配置WriteBehind策略;
- CacheLoaderWriter:配置WriteBehind如何操作SoR。
WriteBehindConfigurationBuilder会进行如下几个配置。
- newUnBatchedWriteBehindConfiguration:表示不进行批量处理,那么所有批量操作都将会转换成单个操作,即CacheLoaderWriter只需要实现write和delete即可。
- queueSize(int size):因为操作是异步回写SoR,需要将操作先放入写操作等待队列,因此,使用queue size定义写操作等待队列***大小,即线程池队列大小。内部使用NonBatchingLocalHeapWriteBehindQueue。
- concurrencyLevel(int concurrency):配置使用多少个并发线程和队列进行WriteBehind。因为我们只传入一个线程池,这是如何实现该模式的呢?首先看如下代码片段。
- for (int i = 0; i < writeBehindConcurrency; i++) {
- if (config.getBatchingConfiguration()== null) {
- this.stripes.add(newNonBatchingLocalHeapWriteBehindQueue<K, V>(executionService,defaultThreadPool, config, cacheLoaderWriter));
- } else {
- this.stripes.add(newBatchingLocalHeapWriteBehindQueue<K, V>(executionService, defaultThreadPool,config, cacheLoaderWriter));
- }
- }
可以看到会创建concurrencyLevel个队列NonBatchingLocalHeapWriteBehindQueue,其又通过如下代码片段创建线程池和线程池队列。
- this.executorQueue = new LinkedBlockingQueue<Runnable>(config.getMaxQueueSize());
- if (config.getThreadPoolAlias() == null) {
- this.executor= executionService.getOrderedExecutor(defaultThreadPool, executorQueue);
- } else {
- this.executor= executionService.getOrderedExecutor(config. getThreadPoolAlias(), executorQueue);
- }
- ● CacheLoaderWriter:此处我们只配置了write和delete,而writeAll和deleteAll将会把批量操作委托给write和delete。
- PooledExecutionService#getOrderedExecutor方法会创建PartitionedOrderedExecutor实例。
- PartitionedOrderedExecutor(BlockingQueue<Runnable> queue,ExecutorService executor) {
- this.delegate= new PartitionedUnorderedExecutor(queue, executor, 1);
- }
其使用maxWorkers=1创建了PartitionedUnorderedExecutor,然后Partitioned UnorderedExecutor通过this.runnerPermit = newSemaphore(maxWorkers)来控制并发,即maxWorkers=1就实现了一个并发。
因此,Ehcache实际能写的***队列大小为concurrency level *queue size。
因为内部使用线程池去写,因此就实现了异步写,又因为使用了队列,因此控制了总的吞吐量(此处有注意根据实际场景给线程池配置Rejected Policy),接下来看下如何实现批量写。
(2) 批量写
- .withLoaderWriter(new DefaultCacheLoaderWriter<String,String>() {
- @Override
- publicvoid writeAll(Iterable<? extends Map.Entry<? extends String,? extends String>> entries) throws BulkCacheWritingException,Exception {
- for(Objectentry : entries) {
- //batchwrite
- }
- }
- @Override
- publicvoid deleteAll(Iterable<? extends String> keys) throws BulkCacheWritingException,Exception {
- for(Objectkey : keys) {
- //batchdelete
- }
- }
- })
- .add(WriteBehindConfigurationBuilder
- .newBatchedWriteBehindConfiguration(3,TimeUnit.SECONDS, 2)
- .queueSize(5)
- .concurrencyLevel(1)
- .enableCoalescing()
- .useThreadPool("writeBehindPool")
- .build()));
和上一个示例不同的地方是使用了newBatchedWriteBehindConfiguration进行批量配置。
● newBatchedWriteBehindConfiguration(longmaxDelay, TimeUnit maxDelayUnit, int batchSize):设置批处理大小和***延迟。batchSize用于定义批处理大小,当写操作数量等于批处理大小时,将把这一批数据发给CacheLoaderWriter进行处理。Ehcache使用BatchingLocalHeapWriteBehindQueue实现批量队列,其中操作批量的代码如下。
- if (openBatch.add(operation)) {//往batch里添加操作,添加的数量等于批处理大小时
- submit(openBatch);//异步提交批处理操作
- openBatch= null;
- }
因此,Ehcache实际能写的***队列大小为concurrency level * queue size * batch size。
maxDelay用于配置未完成的批处理***延迟,比如,我们设置批处理大小为3,而我们实际只写入了两个数据,当写第3个数据时,会触发提交批处理操作。但是,如果我们不写第3个,那么将造成这2个数据一直等待,我们可以设置maxDelay,当超时时也会将这两个数据提交批处理。
● enableCoalescing:是否需要合并写,即对于相同的Key只记录***一次数据。
● CacheLoaderWriter:write和delete会转换为writeAll和deleteAll,即批处理。
三、Copy Pattern
有两种Copy Pattern,Copy-On-Read(在读时复制)和Copy-On-Write(在写时复制),对于Guava Cache和Ehcache中堆缓存都是基于引用的,这样如果有人拿到缓存数据并修改了它,则可能发生不可预测的问题,笔者就见过因为这种情况造成数据错误。Guava Cache没有提供支持,Ehcache 3.x提供了支持。
- public interface Copier<T> {
- TcopyForRead(T obj); //Copy-On-Read,比如myCache.get()
- TcopyForWrite(T obj); //Copy-On-Write,比如myCache.put()
- }
通过如下方法来配置Key和Value的Copier。
- CacheConfigurationBuilder.withKeyCopier()
- CacheConfigurationBuilder.withValueCopier()
【本文是51CTO专栏作者张开涛的原创文章,作者微信公众号:开涛的博客( kaitao-1234567)】