异步是怎么一回事?
在传统的顺序编程中, 所有发送给解释器的指令会一条条被执行。此类代码的输出容易显现和预测。 但是…
譬如说你有一个脚本向3个不同服务器请求数据。 有时,谁知什么原因,发送给其中一个服务器的请求可能意外地执行了很长时间。想象一下从第二个服务器获取数据用了10秒钟。在你等待的时候,整个脚本实际上什么也没干。如果你可以写一个脚本可以不去等待第二个请求而是仅仅跳过它,然后开始执行第三个请求,然后回到第二个请求,执行之前离开的位置会怎么样呢。就是这样。你通过切换任务最小化了空转时间。尽管如此,当你需要一个几乎没有I/O的简单脚本时,你不想用异步代码。
还有一件重要的事情要提,所有代码在一个线程中运行。所以如果你想让程序的一部分在后台执行同时干一些其他事情,那是不可能的。
准备开始
这是 asyncio 主概念最基本的定义:
- 协程— 消费数据的生成器,但是不生成数据。Python 2.5 介绍了一种新的语法让发送数据到生成器成为可能。我推荐查阅David Beazley “A Curious Course on Coroutines and Concurrency” 关于协程的详细介绍。
- 任务— 协程调度器。如果你观察下面的代码,你会发现它只是让 event_loop 尽快调用它的_step ,同时 _step 只是调用协程的下一步。
- class Task(futures.Future):
- def __init__(self, coro, loop=None):
- super().__init__(loop=loop)
- ...
- self._loop.call_soon(self._step)
- def _step(self):
- ...
- try:
- ...
- result = next(self._coro)
- except StopIteration as exc:
- self.set_result(exc.value)
- except BaseException as exc:
- self.set_exception(exc)
- raise
- else:
- ...
- self._loop.call_soon(self._step)
- 事件循环— 把它想成 asyncio 的中心执行器。
现在我们看一下所有这些如何融为一体。正如我之前提到的,异步代码在一个线程中运行。
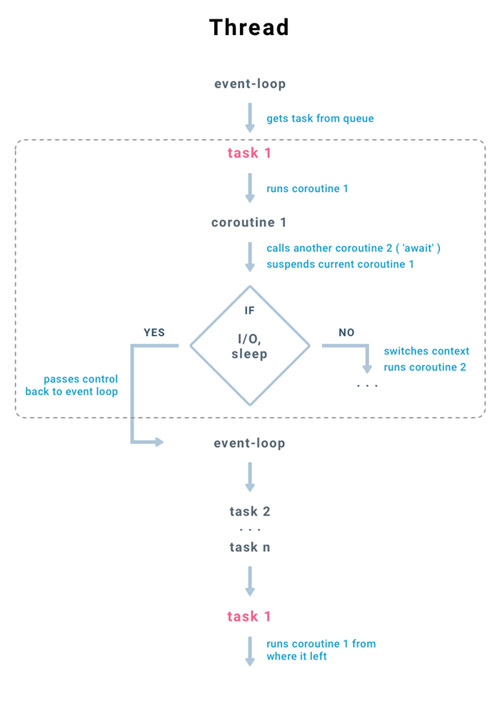
从上图可知:
1.消息循环是在线程中执行
2.从队列中取得任务
3.每个任务在协程中执行下一步动作
4.如果在一个协程中调用另一个协程(await <coroutine_name>),会触发上下文切换,挂起当前协程,并保存现场环境(变量,状态),然后载入被调用协程
5.如果协程的执行到阻塞部分(阻塞I/O,Sleep),当前协程会挂起,并将控制权返回到线程的消息循环中,然后消息循环继续从队列中执行下一个任务...以此类推
6.队列中的所有任务执行完毕后,消息循环返回***个任务
异步和同步的代码对比
现在我们实际验证异步模式的切实有效,我会比较两段 python 脚本,这两个脚本除了 sleep 方法外,其余部分完全相同。在***个脚本里,我会用标准的 time.sleep 方法,在第二个脚本里使用 asyncio.sleep 的异步方法。
这里使用 Sleep 是因为它是一个用来展示异步方法如何操作 I/O 的最简单办法。
使用同步 sleep 方法的代码:
- import asyncio
- import time
- from datetime import datetime
- async def custom_sleep():
- print('SLEEP', datetime.now())
- time.sleep(1)
- async def factorial(name, number):
- f = 1
- for i in range(2, number+1):
- print('Task {}: Compute factorial({})'.format(name, i))
- await custom_sleep()
- f *= i
- print('Task {}: factorial({}) is {}\n'.format(name, number, f))
- start = time.time()
- loop = asyncio.get_event_loop()
- tasks = [
- asyncio.ensure_future(factorial("A", 3)),
- asyncio.ensure_future(factorial("B", 4)),
- ]
- loop.run_until_complete(asyncio.wait(tasks))
- loop.close()
- end = time.time()
- print("Total time: {}".format(end - start))
脚本输出:
- Task A: Compute factorial(2)
- SLEEP 2017-04-06 13:39:56.207479
- Task A: Compute factorial(3)
- SLEEP 2017-04-06 13:39:57.210128
- Task A: factorial(3) is 6
- Task B: Compute factorial(2)
- SLEEP 2017-04-06 13:39:58.210778
- Task B: Compute factorial(3)
- SLEEP 2017-04-06 13:39:59.212510
- Task B: Compute factorial(4)
- SLEEP 2017-04-06 13:40:00.217308
- Task B: factorial(4) is 24
- Total time: 5.016386032104492
使用异步 Sleep 的代码:
- import asyncio
- import time
- from datetime import datetime
- async def custom_sleep():
- print('SLEEP {}\n'.format(datetime.now()))
- await asyncio.sleep(1)
- async def factorial(name, number):
- f = 1
- for i in range(2, number+1):
- print('Task {}: Compute factorial({})'.format(name, i))
- await custom_sleep()
- f *= i
- print('Task {}: factorial({}) is {}\n'.format(name, number, f))
- start = time.time()
- loop = asyncio.get_event_loop()
- tasks = [
- asyncio.ensure_future(factorial("A", 3)),
- asyncio.ensure_future(factorial("B", 4)),
- ]
- loop.run_until_complete(asyncio.wait(tasks))
- loop.close()
- end = time.time()
- print("Total time: {}".format(end - start))
脚本输出:
- Task A: Compute factorial(2)
- SLEEP 2017-04-06 13:44:40.648665
- Task B: Compute factorial(2)
- SLEEP 2017-04-06 13:44:40.648859
- Task A: Compute factorial(3)
- SLEEP 2017-04-06 13:44:41.649564
- Task B: Compute factorial(3)
- SLEEP 2017-04-06 13:44:41.649943
- Task A: factorial(3) is 6
- Task B: Compute factorial(4)
- SLEEP 2017-04-06 13:44:42.651755
- Task B: factorial(4) is 24
- Total time: 3.008226156234741
从输出可以看到,异步模式的代码执行速度快了大概两秒。当使用异步模式的时候(每次调用 await asyncio.sleep(1) ),进程控制权会返回到主程序的消息循环里,并开始运行队列的其他任务(任务A或者任务B)。
当使用标准的 sleep方法时,当前线程会挂起等待。什么也不会做。实际上,标准的 sleep 过程中,当前线程也会返回一个 python 的解释器,可以操作现有的其他线程,但这是另一个话题了。
推荐使用异步模式编程的几个理由
很多公司的产品都广泛的使用了异步模式,如 Facebook 旗下著名的 React Native 和 RocksDB 。像 Twitter 每天可以承载 50 亿的用户访问,靠的也是异步模式编程。所以说,通过代码重构,或者改变模式方法,就能让系统工作的更快,为什么不去试一下呢?