












去年开始,工作中需要做许多有关 AI 科普的事情。很长时间里一直在想,该如何给一个没有 CS 背景的人讲解什么是深度学习,以便让一个非技术的投资人、企业管理者、行业专家、媒体记者乃至普通大众明白深度学习为什么会特别有效,理解 AI 是如何帮助人们解决具体问题的。中间经由 Quora 一篇简短回答的启发,大致形成了用水流脉络来比拟神经网络的想法。曾经在面向银行界、教育界、投资界人士的演讲中,尝试过基于这个比喻的讲解方法,效果很不错。慢慢就形成了这样一篇文章,最近也被收进了李开复和我合著的科普书《人工智能》中。
【注】特别需要说明的是,本文对深度学习的概念阐述刻意避免了数学公式和数学论证,这种用水管网络来普及深度学习的方法只适合一般公众。对于懂数学、懂计算机科学的专业人士来说,这样的描述相当不完备也不精确。流量调节阀的比喻与深度神经网络中每个神经元相关的权重调整,在数学上并非完全等价。对水管网络的整体描述也有意忽略了深度学习算法中的代价函数、梯度下降、反向传播等重要概念。专业人士要学习深度学习,还是要从专业教程看起。
从根本上说,深度学习和所有机器学习方法一样,是一种用数学模型对真实世界中的特定问题进行建模,以解决该领域内相似问题的过程。
首先,深度学习是一种机器学习。既然名为“学习”,那自然与我们人类的学习过程有某种程度的相似。回想一下,一个人类小朋友是如何学习的?
人类小朋友是如何学习的?机器又是如何学习的?
比如,很多小朋友都用识字卡片来认字。从古时候人们用的“上大人、孔乙己”之类的描红本,到今天在手机、平板电脑上教小朋友认字的识字卡片APP,最基本的思路就是按照从简单到复杂的顺序,让小朋友反复看每个汉字的各种写法(大一点的小朋友甚至要学着认识不同的书法字体),看得多了,自然就记住了。下次再见到同一个字,就很容易能认出来。
这个有趣的识字过程看似简单,实则奥妙无穷。认字时,一定是小朋友的大脑在接受许多遍相似图像的刺激后,为每个汉字总结出了某种规律性的东西,下次大脑再看到符合这种规律的图案,就知道是什么字了。
其实,要教计算机认字,差不多也是同样的道理。计算机也要先把每一个字的图案反复看很多很多遍,然后,在计算机的大脑(处理器加上存储器)里,总结出一个规律来,以后计算机再看到类似的图案,只要符合之前总结的规律,计算机就能知道这图案到底是什么字。
用专业的术语来说,计算机用来学习的、反复看的图片叫“训练数据集”;“训练数据集”中,一类数据区别于另一类数据的不同方面的属性或特质,叫做“特征”;计算机在“大脑”中总结规律的过程,叫“建模”;计算机在“大脑”中总结出的规律,就是我们常说的“模型”;而计算机通过反复看图,总结出规律,然后学会认字的过程,就叫“机器学习”。
到底计算机是怎么学习的?计算机总结出的规律又是什么样的呢?这取决于我们使用什么样的机器学习算法。
有一种算法非常简单,模仿的是小朋友学识字的思路。家长和老师们可能都有这样的经验:小朋友开始学识字,比如先教小朋友分辨“一”、“二”、“三”时,我们会告诉小朋友说,一笔写成的字是“一”,两笔写成的字是“二”,三笔写成的字是“三”。这个规律好记又好用。但是,开始学新字时,这个规律就未必奏效了。比如,“口”也是三笔,可它却不是“三”。我们通常会告诉小朋友,围成个方框儿的是“口”,排成横排的是“三”。这规律又丰富了一层,但仍然禁不住识字数量的增长。很快,小朋友就发现,“田”也是个方框儿,可它不是“口”。我们这时会告诉小朋友,方框里有个“十”的是“田”。再往后,我们多半就要告诉小朋友,“田”上面出头是“由”,下面出头是“甲”,上下都出头是“申”。很多小朋友就是在这样一步一步丰富起来的特征规律的指引下,慢慢学会自己总结规律,自己记住新的汉字,并进而学会几千个汉字的。
有一种名叫决策树的机器学习方法,就和上面根据特征规律来识字的过程非常相似。当计算机只需要认识“一”、“二”、“三”这三个字时,计算机只要数一下要识别的汉字的笔画数量,就可以分辨出来了。当我们为待识别汉字集(训练数据集)增加“口”和“田”时,计算机之前的判定方法失败,就必须引入其他判定条件。由此一步步推进,计算机就能认识越来越多的字。
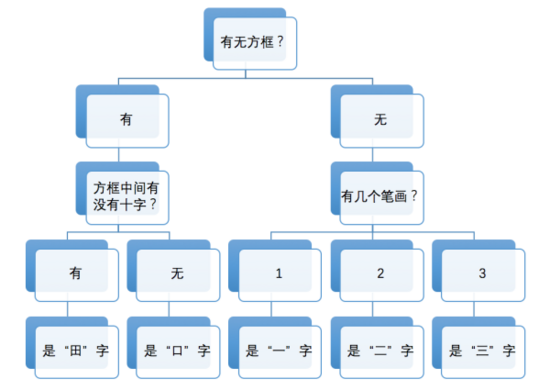
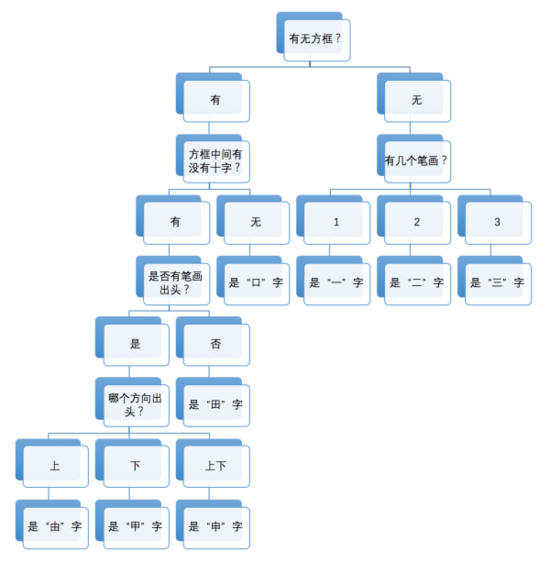
附图显示了计算机学习“由”、“甲”、“申”这三个新汉字前后,计算机内部的决策树的不同。这说明,当我们给计算机“看”了三个新汉字及其特征后,计算机就像小朋友那样,总结并记住了新的规律,“认识”了更多的汉字。这个过程,就是一种最基本的机器学习了。
当然,这种基于决策树的学习方法太简单了,很难扩展,也很难适应现实世界的不同情况。于是,科学家和工程师们陆续发明出了许许多多不同的机器学习方法。
例如,我们可以把汉字“由”、“甲”、“申”的特征,包括有没有出头,笔画间的位置关系等,映射到某个特定空间里的一个点(我知道,这里又出现数学术语了。不过这不重要,是否理解“映射”的真实含义,完全不影响后续阅读)。也就是说,训练数据集中,这三个字的大量不同写法,在计算机看来就变成了空间中的一大堆点。只要我们对每个字的特征提取得足够好,空间中的一大堆点就会大致分布在三个不同的范围里。
这时,让计算机观察这些点的规律,看能不能用一种简明的分割方法(比如在空间中画直线),把空间分割成几个相互独立的区域,尽量使得训练数据集中每个字对应的点都位于同一个区域内。如果这种分割是可行的,就说明计算机“学”到了这些字在空间中的分布规律,为这些字建立了模型。
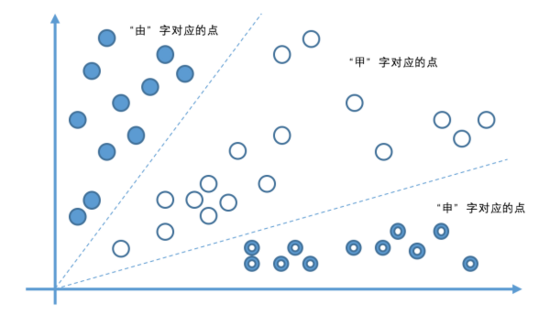
接下来,看见一个新的汉字图像时,计算机就简单把图像换算成空间里的一个点,然后判断这个点落在了哪个字的区域里,这下,不就能知道这个图像是什么字了吗?
很多人可能已经看出来了,使用画直线的方法来分割一个平面空间(如附图所示),很难适应几千个汉字以及总计至少数万种不同的写法。如果想把每个汉字的不同变形都对应为空间中的点,那就极难找到一种数学上比较直截了当的方法,来将每个汉字对应的点都分割包围在不同区域里。
很多年里,数学家和计算机科学家就是被类似的问题所困扰。人们不断改进机器学习方法。比如,用复杂的高阶函数来画出变化多端的曲线,以便将空间里相互交错的点分开来,或者,干脆想办法把二维空间变成三维空间、四维空间甚至几百维、几千维、几万维的高维空间。在深度学习实用化之前,人们发明了许多种传统的、非深度的机器学习方法。这些方法虽然在特定领域取得了一定成就,但这个世界实在是复杂多样、变化万千,无论人们为计算机选择了多么优雅的建模方法,都很难真正模拟世界万物的特征规律。这就像一个试图用有限几种颜色画出世界真实面貌的画家,即便画艺再高明,他也很难做到“写实”二字。
那么,如何大幅扩展计算机在描述世界规律时的基本手段呢?有没有可能为计算机设计一种灵活度极高的表达方式,然后让计算机在大规模的学习过程里不断尝试和寻找,自己去总结规律,直到最终找到符合真实世界特征的一种表示方法呢?
现在,我们终于要谈到深度学习了!
深度学习就是这样一种在表达能力上灵活多变,同时又允许计算机不断尝试,直到最终逼近目标的一种机器学习方法。从数学本质上说,深度学习与前面谈到的传统机器学习方法并没有实质性差别,都是希望在高维空间中,根据对象特征,将不同类别的对象区分开来。但深度学习的表达能力,与传统机器学习相比,却有着天壤之别。
简单地说,深度学习就是把计算机要学习的东西看成一大堆数据,把这些数据丢进一个复杂的、包含多个层级的数据处理网络(深度神经网络),然后检查经过这个网络处理得到的结果数据是不是符合要求——如果符合,就保留这个网络作为目标模型,如果不符合,就一次次地、锲而不舍地调整网络的参数设置,直到输出满足要求为止。
这么说还是太抽象,太难懂。我们换一种更直观的讲法。
假设深度学习要处理的数据是信息的“水流”,而处理数据的深度学习网络是一个由管道和阀门组成的巨大的水管网络。网络的入口是若干管道开口,网络的出口也是若干管道开口。这个水管网络有许多层,每一层有许多个可以控制水流流向与流量的调节阀。根据不同任务的需要,水管网络的层数、每层的调节阀数量可以有不同的变化组合。对复杂任务来说,调节阀的总数可以成千上万甚至更多。水管网络中,每一层的每个调节阀都通过水管与下一层的所有调节阀连接起来,组成一个从前到后,逐层完全连通的水流系统(这里说的是一种比较基本的情况,不同的深度学习模型,在水管的安装和连接方式上,是有差别的)。
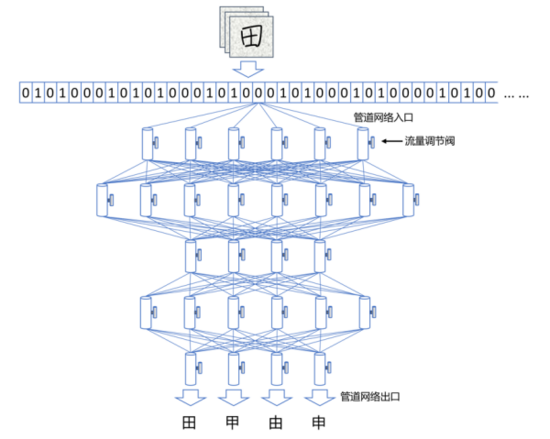
那么,计算机该如何使用这个庞大的水管网络,来学习识字呢?
比如,当计算机看到一张写有“田”字的图片时,就简单将组成这张图片的所有数字(在计算机里,图片的每个颜色点都是用“0”和“1”组成的数字来表示的)全都变成信息的水流,从入口灌进水管网络。
我们预先在水管网络的每个出口都插一块字牌,对应于每一个我们想让计算机认识的汉字。这时,因为输入的是“田”这个汉字,等水流流过整个水管网络,计算机就会跑到管道出口位置去看一看,是不是标记有“田”字的管道出口流出来的水流最多。如果是这样,就说明这个管道网络符合要求。如果不是这样,我们就给计算机下达命令:调节水管网络里的每一个流量调节阀,让“田”字出口“流出”的数字水流最多。
这下,计算机可要忙一阵子了,要调节那么多阀门呢!好在计算机计算速度快,暴力计算外加算法优化(其实,主要是精妙的数学方法了,不过我们这里不讲数学公式,大家只要想象计算机拼命计算的样子就可以了),总是可以很快给出一个解决方案,调好所有阀门,让出口处的流量符合要求。
下一步,学习“申”字时,我们就用类似的方法,把每一张写有“申”字的图片变成一大堆数字组成的水流,灌进水管网络,看一看,是不是写有“申”字的那个管道出口流出来的水最多,如果不是,我们还得再次调整所有的调节阀。这一次,要既保证刚才学过的“田”字不受影响,也要保证新的“申”字可以被正确处理。
如此反复进行,直到所有汉字对应的水流都可以按照期望的方式流过整个水管网络。这时,我们就说,这个水管网络已经是一个训练好的深度学习模型了。
例如,附图显示了“田”字的信息水流被灌入水管网络的过程。为了让水流更多地从标记有“田”字的出口流出,计算机需要用特定方式近乎疯狂地调节所有流量调节阀,不断实验、摸索,直到水流符合要求为止。
当大量识字卡片被这个管道网络处理,所有阀门都调节到位后,整套水管网络就可以用来识别汉字了。这时,我们可以把调节好的所有阀门都“焊死”,静候新的水流到来。
与训练时做的事情类似,未知的图片会被计算机转变成数据的水流,灌入训练好的水管网络。这时,计算机只要观察一下,哪个出口流出来的水流最多,这张图片写的就是哪个字。
简单吗?神奇吗?难道深度学习竟然就是这样的一个靠疯狂调节阀门来“凑”出最佳模型的学习方法?整个水管网络内部,每个阀门为什么要如此调节,为什么要调节到如此程度,难道完全由最终每个出口的水流量来决定?这里面,真的没有什么深奥的道理可言?
深度学习大致就是这么一个用人类的数学知识与计算机算法构建起整体架构,再结合尽可能多的训练数据,以及计算机的大规模运算能力去调节内部参数,尽可能逼近问题目标的半理论、半经验的建模方式。
指导深度学习的基本是一种实用主义的思想。
不是要理解更复杂的世界规律吗?那我们就不断增加整个水管网络里可调节的阀门的个数(增加层数或增加每层的调节阀数量)。不是有大量训练数据和大规模计算能力吗?那我们就让许多CPU和许多GPU(图形处理器,俗称显卡芯片,原本是专用于作图和玩游戏的,碰巧也特别适合深度学习计算)组成庞大计算阵列,让计算机在拼命调节无数个阀门的过程中,学到训练数据中的隐藏的规律。也许正是因为这种实用主义的思想,深度学习的感知能力(建模能力)远强于传统的机器学习方法。
实用主义意味着不求甚解。即便一个深度学习模型已经被训练得非常“聪明”,可以非常好地解决问题,但很多情况下,连设计整个水管网络的人也未必能说清楚,为什么管道中每一个阀门要调节成这个样子。也就是说,人们通常只知道深度学习模型是否工作,却很难说出,模型中某个参数的取值与最终模型的感知能力之间,到底有怎样的因果关系。
这真是一件特别有意思的事。有史以来最有效的机器学习方法,在许多人看来,竟然是一个只可意会、不可言传的“黑盒子”。
由此引发的一个哲学思辨是,如果人们只知道计算机学会了做什么,却说不清计算机在学习过程中掌握的是一种什么样的规律,那这种学习本身会不会失控?
比如,很多人由此担心,按照这样的路子发展下去,计算机会不会悄悄学到什么我们不希望它学会的知识?另外,从原理上说,如果无限增加深度学习模型的层数,那计算机的建模能力是不是就可以与真实世界的终极复杂度有一比呢?如果这个答案是肯定的,那只要有足够的数据,计算机就能学会宇宙中所有可能的知识——接下来会发生什么?大家是不是对计算机的智慧超越人类有了些许的忧虑?还好,关于深度学习到底是否有能力表达宇宙级别的复杂知识,专家们尚未有一致看法。人类至少在可见的未来还是相对安全的。
补充一点:目前,已经出现了一些可视化的工具,能够帮助我们“看见”深度学习在进行大规模运算时的“样子”。比如说,谷歌著名的深度学习框架TensorFlow就提供了一个网页版的小工具( Tensorflow — Neural Network Playground ),用人们易于理解的图示,画出了正在进行深度学习运算的整个网络的实时特征。
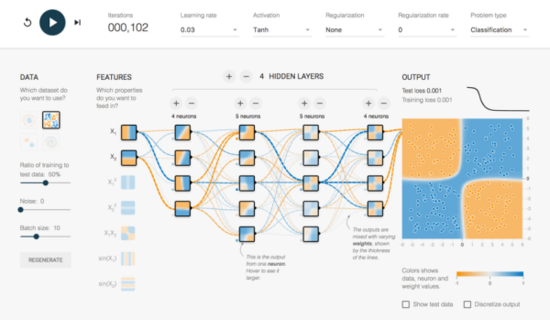
附图显示了一个包含4层中间层级(隐含层)的深度神经网络针对某训练数据集进行学习时的“样子”。图中,我们可以直观地看到,网络的每个层级与下一个层级之间,数据“水流”的方向与大小。我们还可以随时在这个网页上改变深度学习框架的基本设定,从不同角度观察深度学习算法。这对我们学习和理解深度学习大有帮助。
附图显示了一个包含4层中间层级(隐含层)的深度神经网络针对某训练数据集进行学习时的“样子”。图中,我们可以直观地看到,网络的每个层级与下一个层级之间,数据“水流”的方向与大小。我们还可以随时在这个网页上改变深度学习框架的基本设定,从不同角度观察深度学习算法。这对我们学习和理解深度学习大有帮助。
注:本文摘自李开复、王咏刚 《人工智能》 一书
















