机器学习数据集
机器学习中重要的一步是创建或寻找合适的数据来训练和检验算法。使用好的数据集可以帮助你规避或发现算法中的错误,改善程序的结果。在多数情况下,创建自己的数据集是一件费时的事。本文会向介绍一些有用的数据集,用于文本分类和图像分类问题。
文本分类
本节将介绍一些用于普通文本分类任务的数据集,如垃圾信息检测、情感分析和文档主题分类。
• 垃圾信息 – 非垃圾信息
垃圾信息过滤任务在文本分类中很常见,因此,用于这类任务的数据集很多。
SMS 垃圾短信语料库
SMS 垃圾短信语料库由两类文本信息组成,每个短信都被标记为垃圾信息或正常信息。这个数据集有大(1002条正常信息,322条垃圾信息)、小(1002条正常信息,82条垃圾信息)两种版本可下载。
Enron 数据集
如果想研究垃圾电子邮件过滤,你可能会对 Enron 数据集感兴趣,该数据集收集了成千上万的邮件,都被分为垃圾邮件和正常邮件。有未处理和经过预处理的版本可供下载。
其它你可能会感兴趣的垃圾邮件分类的数据集有:SpamAssassin 公共邮件语料库、TREC 公共垃圾邮件语料库 、Spambase 数据集。
• 情感分析
可通过机器学习解决的另一个任务是文本情感分析,其中一个例子就是判断文本对某个主题陈述的是支持意见还是反对意见。
Twitter 情感分析训练语料库
如果你对推文(tweet)的情感分类感兴趣,Twitter 情感分析训练语料库可能是你需要的。它由超过 100 万条 tweets 组成,存于一个 .csv 文件中,每条语料都被标记为支持(1)或反对(0)。
影评数据集
影评数据集包含更复杂的文本,收集了 1,000 条正面影评和 1,000 条负面影评,未处理的 .html 文件形式和已处理的文本形式皆可获得。这个数据集的一部分作为语句集,还被标记了主观或客观的标签。
更多关于情感分类的更好用的数据集被整理形成一个列表,放在 Kavita Ganesan 的博客中。
• 主题分类
文档主题分类是一个复杂的问题。根据待研究的文档种类不同,所需的合适的数据集也不相同。一个经常研究的案例是报刊文章的分类。
20 Newsgroups
20 Newsgroups 数据集包含大约 20,000 份文档,几乎平均分布于 20 个类别。数据被分为训练集和测试集。这些新闻组有些密切相关,而另一些毫不相关。数据集中的新闻组如下:
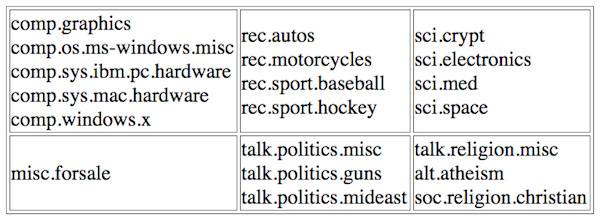
20 newsgroups 数据集的组织形式,资源: http://qwone.com/~jason/20Newsgroups/
路透社-21578
一个经常使用的用于评估文本分类算法的数据集是路透社-21578, 它由出现在 1987 年路透社新闻专线中的文本组成,由路透社公司员工整理。通常只是使用这个数据集的一些子集,作为类别不均匀分布的文档使用。通常情况下,使用最频繁的文档只占了10或90个类别。
在 Ana Cardoso Cachopo 的主页提供了一个很有用的收集单标记文本的数据集,不仅可以找到有用数据的概览,还提供了数据集的可读版本和预处理版本,可以为你省去很多时间和麻烦。
图像分类
这一节将介绍一些在用机器学习解决图像分类问题时有用的数据集,列出的数据集从简单的手写数字,到复杂物体的图像,会对学习图像分类和测试算法很有帮助。
• 数字和字母
MNIST
MNIST 数据集是学习图像分类经常使用的数据集,包含上千张从 0 到 9 的手写数字的小二进制图像,划分为训练集和测试集。可以从 YannLeCun 的网站下载 IDX 文件格式,如果你想使用 png 格式的图像做数据,可以从这找到转化的版本。
MNIST 数据集摘录
Chars74K
另一个可通过机器学习解决的任务是字符识别,基于这个目的,可以用 Chars74K 数据集可用来训练和测试。它拥有超过 74,000 张字母和数字图像,被分成 64 个不同的种类。字母都是手写体,通过自然图片和电脑字体获得。由于种类更多,并且数据是彩色图像,这个数据集比 MNIST 集复杂得多。

Chars74K 数据集摘录, 资源: http://www.ee.surrey.ac.uk/CVSSP/demos/chars74k/Samples/english.png
• 人脸
正面人脸图像
正面人脸图像数据集是为评估图像中正面人脸识别程序而建立的,包含人的图像以及通过 x、y 坐标给出的人脸在图片中的位置信息。这里可以下载该数据集。

正面人脸图像数据集摘录
复杂场景中标记人脸
面部检测中经常使用的数据集是复杂场景中标记人脸数据集,拥有从网络中收集的超过 13,000 张图片。很多人不止一次出现在数据集中的图片中,对面部识别评估很有用。

复杂场景中标记人脸数据集摘录
• 动物
Oxford-IIIT 宠物数据集
如果你在找大规模的猫狗数据集,你可以看看牛津- IIIT宠物数据集,有 37 个包含不同种类猫狗的类别,每个类别有 200 张图片。与很多其它数据集不同,它的图片的大小不一,更酷的是这个数据集不仅提供图像,还有动物的面部位置信息,以及图像的前景、背景信息(见下图)。

牛津-IIIT 宠物数据集示例, 资源: http://www.robots.ox.ac.uk/~vgg/data/pets/
KTH-ANIMALS
如果你需要更普遍的动物数据集,KTH-ANIMALS 值得一看。它可以从这下载,提供了 19 种不同类别的图像。每一类有大约 100 张不同大小的图片,和 牛津-IIIT 宠物数据集一样,也提供了前景、背景信息。

KTH-Animals 数据集概览,资源: http://www.csc.kth.se/~att/Site/Animals.html
• 各种物体
CIFAR-10 and CIFAR-100
对于更高级的图像分类应用,你可能对 CIFAR 数据集感兴趣。这些数据集包含大小为 32×32 像素的彩色图像,可以从 Alex Krizhevsky 的网站下载。
CIFAR-10 数据集由 60,000 张图片组成,平均分布于 10 个种类。如果你需要拥有更多种类的更复杂的数据集,你可以使用 CIFAR-100 数据集,它提供了100个类,20个超类的图片。

CIFAR-10 数据集摘录,资源: https://www.cs.toronto.edu/~kriz/cifar.html
这两个 CIFAR 数据集都有 python、matlab 或二进制版本提供下载。如果你更喜欢用 png 图像作为数据,可以使用这个工具进行转换。
STL-10
CIFAR 数据集提供的图片很小,因此如果你想使用更高分辨率的图片,STL-10 数据集可能更吸引你。这个数据集包含 10 个类的标记图片,与 CIFAR-10 数据集相似,但是图像大小有 96×96 像素。每个类含有较少的标记样例,但却有很大的未标记图像集,可以用作非监督训练。

STL-10 数据集摘录, 资源: https://cs.stanford.edu/~acoates/stl10/images.png