在近些年,深度学习领域的卷积神经网络(CNNs或ConvNets)在各行各业为我们解决了大量的实际问题。但是对于大多数人来说,CNN仿佛戴上了神秘的面纱。我经常会想,要是能将神经网络的过程分解,看一看每一个步骤是什么样的结果该有多好!这也就是这篇博客存在的意义。
高级CNN
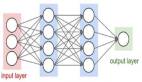
首先,我们要了解一下卷积神经网络擅长什么。CNN主要被用来找寻图片中的模式。这个过程主要有两个步骤,首先要对图片做卷积,然后找寻模式。在神经网络中,前几层是用来寻找边界和角,随着层数的增加,我们就能识别更加复杂的特征。这个性质让CNN非常擅长识别图片中的物体。
CNN是什么
CNN是一种特殊的神经网络,它包含卷积层、池化层和激活层。
卷积层
要想了解什么是卷积神经网络,你首先要知道卷积是怎么工作的。想象你有一个5*5矩阵表示的图片,然后你用一个3*3的矩阵在图片中滑动。每当3*3矩阵经过的点就用原矩阵中被覆盖的矩阵和这个矩阵相乘。这样一来,我们可以使用一个值来表示当前窗口中的所有点。下面是一个过程的动图:
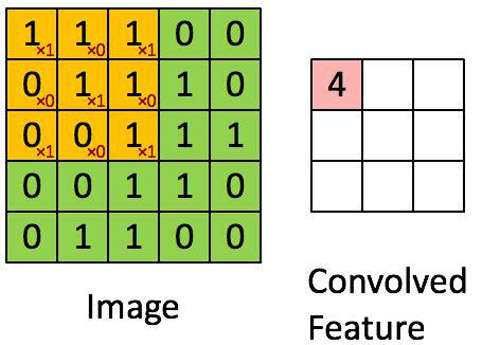
正如你所见的那样,特征矩阵中的每一个项都和原图中的一个区域相关。
在图中像窗口一样移动的叫做核。核一般都是方阵,对于小图片来说,一般选用3*3的矩阵就可以了。每次窗口移动的距离叫做步长。值得注意的是,一些图片在边界会被填充零,如果直接进行卷积运算的话会导致边界处的数据变小(当然图片中间的数据更重要)。
卷积层的主要目的是滤波。当我们在图片上操作时,我们可以很容易得检查出那部分的模式,这是由于我们使用了滤波,我们用权重向量乘以卷积之后的输出。当训练一张图片时,这些权重会不断改变,而且当遇到之前见过的模式时,相应的权值会提高。来自各种滤波器的高权重的组合让网络预测图像的内容的能力。 这就是为什么在CNN架构图中,卷积步骤由一个框而不是一个矩形表示; 第三维代表滤波器。
注意事项:
卷积运算后的输出无论在宽度上还是高度上都比原来的小
核和图片窗口之间进行的是线性的运算
滤波器中的权重是通过许多图片学习的
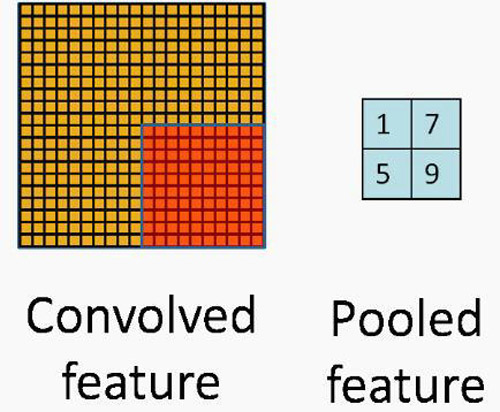
池化层
池化层和卷积层很类似,也是用一个卷积核在图上移动。唯一的不同就是池化层中核和图片窗口的操作不再是线性的。
***池化和平均池化是最常见的池化函数。***池化选取当前核覆盖的图片窗口中***的数,而平均池化则是选择图片窗口的均值。
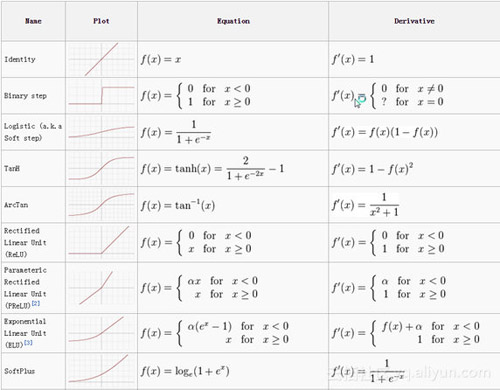
激活层
在CNN中,激活函数和其他网络一样,函数将数值压缩在一个范围内。下面列出了一些常见的函数。
在CNN中最常用的是relu(修正线性单元)。人们有许多喜欢relu的理由,但是最重要的一点就是它非常的易于实现,如果数值是负数则输出0,否则输出本身。这种函数运算简单,所以训练网络也非常快。
回顾:
CNN中主要有三种层,分别是:卷积层、池化层和激活层。
卷积层使用卷积核和图片窗口相乘,并使用梯度下降法去优化卷积核。
池化层使用***值或者均值来描述一个图形窗口。
激活层使用一个激活函数将输入压缩到一个范围中,典型的[0,1][-1,1]。
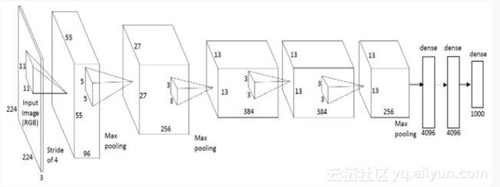
CNN是什么样的呢?
在我们深入了解CNN之前,让我们先补充一些背景知识。早在上世纪90年代,Yann LeCun就使用CNN做了一个手写数字识别的程序。而随着时代的发展,尤其是计算机性能和GPU的改进,研究人员有了更加丰富的想象空间。 2010年斯坦福的机器视觉实验室发布了ImageNet项目。该项目包含1400万带有描述标签的图片。这个几乎已经成为了比较CNN模型的标准。目前,***的模型在这个数据集上能达到94%的准确率。人们不断的改善模型来提高准确率。在2014年GoogLeNet 和VGGNet成为了***的模型,而在此之前是ZFNet。CNN应用于ImageNet的***个可行例子是AlexNet,在此之前,研究人员试图使用传统的计算机视觉技术,但AlexNet的表现要比其他一切都高出15%。让我们一起看一下LeNet:
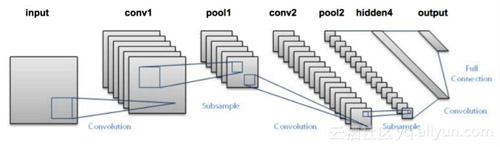
这个图中并没有显示激活层,整个的流程是:
输入图片 →卷积层 →Relu → ***池化→卷积层 →Relu→ ***池化→隐藏层 →Softmax (activation)→输出层。
让我们一起看一个实际的例子
下图是一个猫的图片:
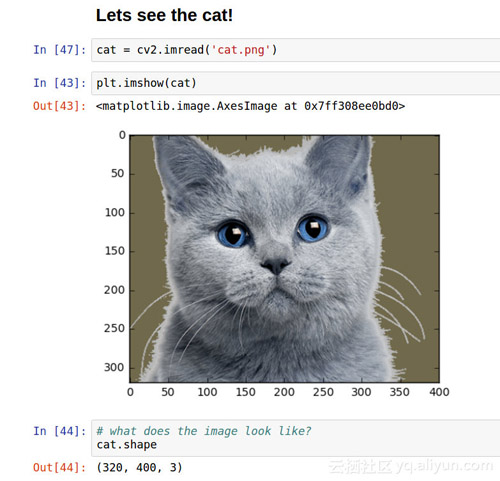
这张图长400像素宽320像素,有三个通道(rgb)的颜色。
那么经过一层卷积运算之后会变成什么样子呢?
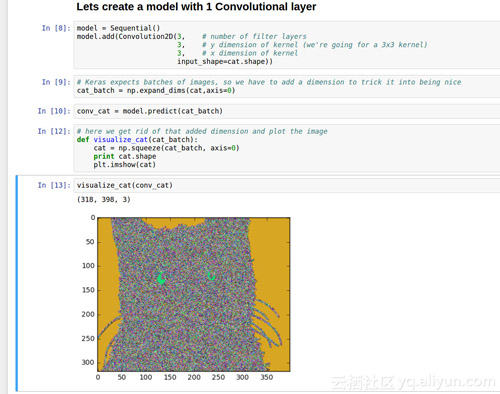
这是用一个3*3的卷积核和三个滤波器处理的效果(如果我们有超过3个的滤波器,那么我可以画出猫的2d图像。更高维的话就很难处理)
我们可以看到,图中的猫非常的模糊,因为我们使用了一个随机的初始值,而且我们还没有训练网络。他们都在彼此的顶端,即使每层都有细节,我们将无法看到它。但我们可以制作出与眼睛和背景相同颜色的猫的区域。如果我们将内核大小增加到10x10,会发生什么呢?
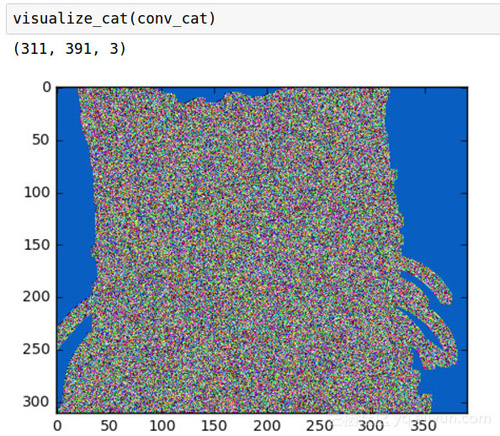
我们可以看到,由于内核太大,我们失去了一些细节。还要注意,从数学角度来看,卷积核越大,图像的形状会变得越小。
如果我们把它压扁一点,我们可以更好的看到色彩通道会发生什么?
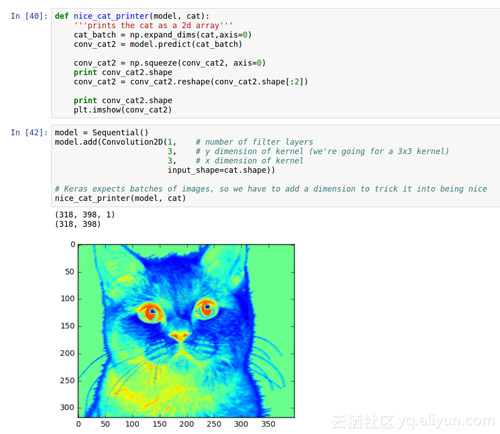
这张看起来好多了!现在我们可以看到我们的过滤器看到的一些事情。看起来红色替换掉了黑色的鼻子和黑色眼睛,蓝色替换掉了猫边界的浅灰色。我们可以开始看到图层如何捕获照片中的一些更重要的细节。
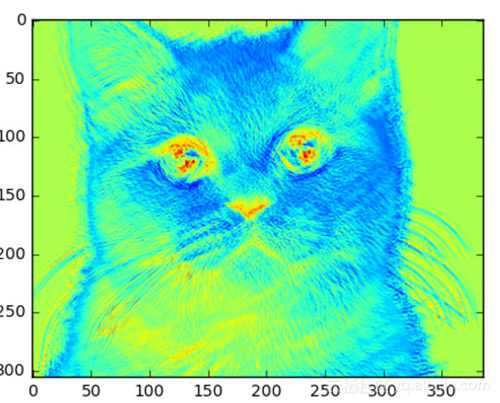
如果我们增加内核大小,我们得到的细节就会越来越明显,当然图像也比其他两个都小。
增加一个激活层
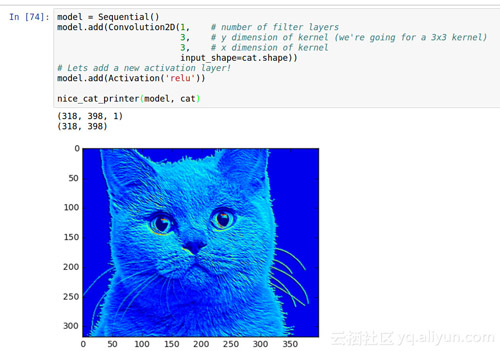
我们通过添加一个relu,去掉了很多不是蓝色的部分。
增加一个池化层
我们添加一个池化层(摆脱激活层***限度地让图片更加更容易显示)。
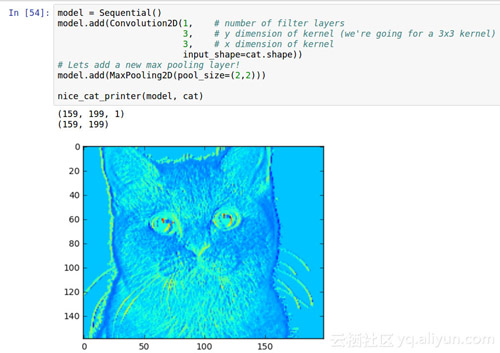
正如预期的那样,猫咪变成了斑驳的,而我们可以让它更加斑驳。
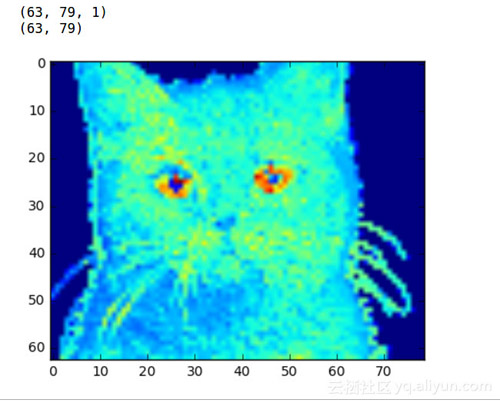
现在图片大约成了原来的三分之一。
激活和***池化
LeNet
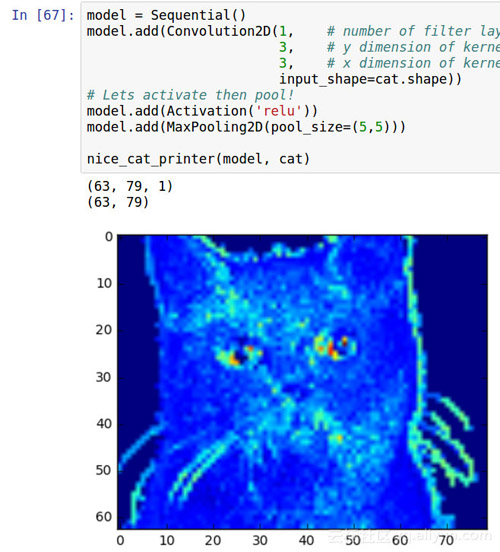
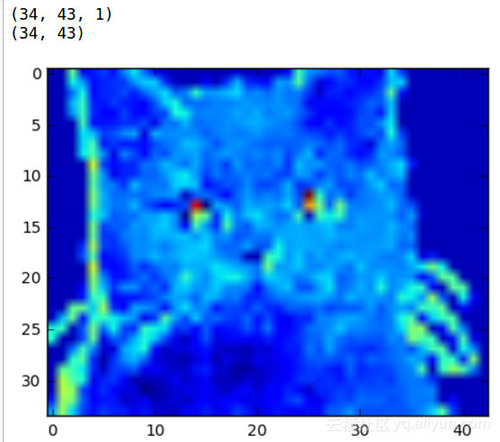
如果我们将猫咪的图片放到LeNet模型中做卷积和池化,那么效果会怎么样呢?
总结
ConvNets功能强大,因为它们能够提取图像的核心特征,并使用这些特征来识别包含其中的特征的图像。即使我们的两层CNN,我们也可以开始看到网络正在对猫的晶须,鼻子和眼睛这样的地区给予很多的关注。这些是让CNN将猫与鸟区分开的特征的类型。
CNN是非常强大的,虽然这些可视化并不***,但我希望他们能够帮助像我这样正在尝试更好地理解ConvNets的人。