从外表来看,数据科学通常被认为完全是由高等统计学和机器学习技术组成。然而,另一个重要组成部分往往被低估或遗忘:探索性数据分析(EDA)。EDA指对已有的数据(特别是调查或观察得来的原始数据)在尽量少的先验假定下进行探索,通过作图、制表、方程拟合、计算特征量等手段探索数据的结构和规律的一种数据分析方法。在深入机器学习或统计建模之前,EDA是一个重要的步骤,这是因为它提供了为现有问题开发适当模型并正确解释其结果所需的来龙去脉。
但随着工具的兴起,只需要简单的将数据提供给黑盒就可以轻松实现强大的机器学习算法,因此略过EDA这一步将变得异常诱惑。然而简单地将数据提供给黑盒并不总是一个好主意——这是因为EDA对于所有类型的数据科学问题具有关键价值。
EDA对数据科学家而言是有价值的,这是因为EDA能确保他们生成的结果是有效的、能被正确解析以及适用于所需的业务环境。在确保技术交付成果之外,EDA还通过确认正在提出正确的问题而不是基于假设调查以及通过提供问题的背景来确保数据科学家的输的出潜在的价值可以***化。
这篇文章将高度概述EDA通常涉及的内容,然后描述EDA对于成功建模和解释其结果至关重要的三个主要方式。无论您是数据科学家还是数据科学的消费者,希望在阅读本文后,您将了解为什么EDA应该是在项目数据科学操作中的关键一部分。
什么是EDA?
尽管EDA已经存在于数据分析,据说1977年约翰·图克(John W. Tukey)写的“探索性数据分析”一书中已经创造了这个词并发展了这个领域。概括来讲,EDA用于理解和总结数据集的内容,通常用于调查特定问题或更高级的建模。EDA通常很大程度上依赖于可视化数据来评估模式并利用一些定量方法来描述数据。
EDA通常涉及以下几种方法的组合:
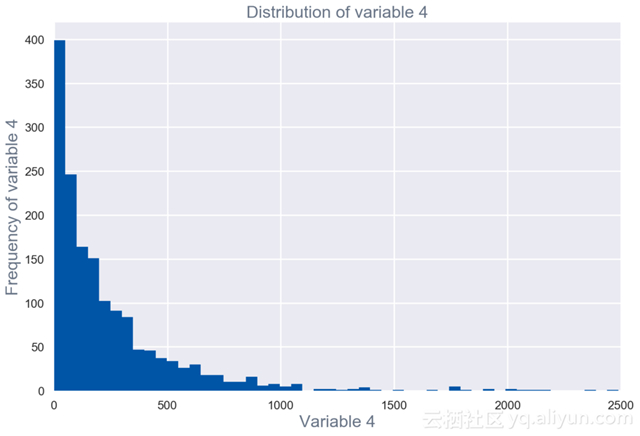
原始数据集中每个字段的单变量可视化和汇总统计(见图1)
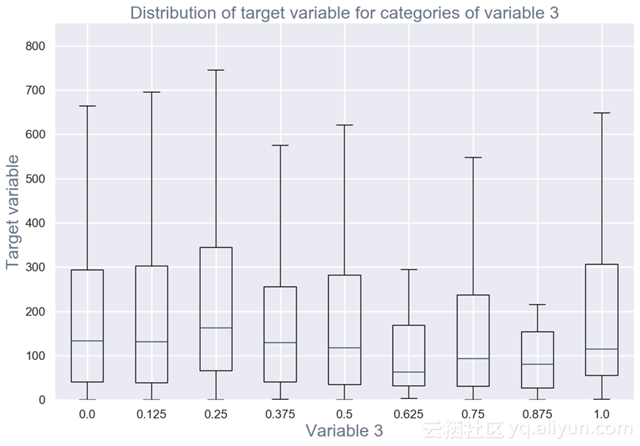
用于评估数据集中每个变量与感兴趣目标变量之间的关系的双变量可视化和汇总统计(例如,时间流失,花费)(见图2)
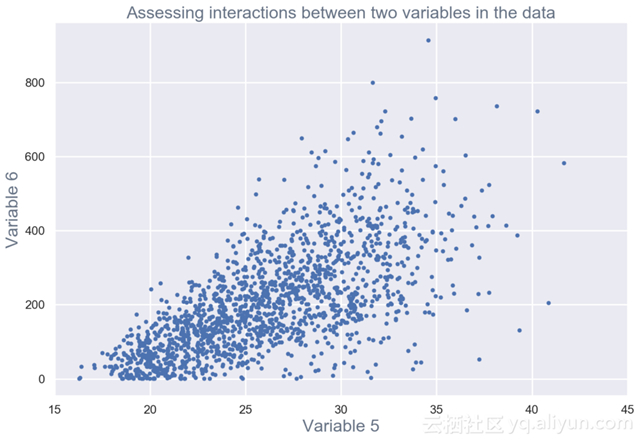
多元可视化以了解数据中不同字段之间的交互作用(见图3)。
降维以了解数据中的字段,这些字段占据了观察值之间的***差异,并允许处理减少的数据量。
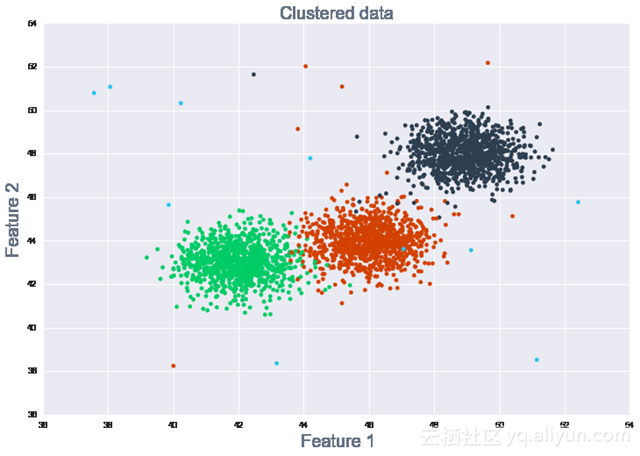
通过将数据折叠成几个小数据点让观察值聚类成有区别的小组,可以更容易地识别行为模式(参见图4)
通过这些方法,数据科学家验证假设并识别有助于理解问题和模型选择的模式,为数据建立直觉以确保高质量分析,并验证数据是按预期的方式生成。
验证假设和模式识别
EDA的主要目的之一是在假设任何事情之前查看数据,这是很重要的。首先,数据科学家可以验证在构建模型时可能已经做出的任何假设,或者是使用某些算法所必需的假设。其次,对数据的自由假设探索可以帮助识别模式以及观察到行为的潜在原因,这可能有助于回答遇到的问题或告知建模的选择。
通常有两种类型的假设可能影响分析的有效性:技术和商业。正确使用特定的分析模型和算法依赖于具体的技术假设是否正确,例如变量之间没有共线性、数据中的方差与数据值无关以及数据是否以某种方式丢失或损坏。在EDA中,评估各种技术假设以帮助选择对手头数据和任务而言的***模型。如果没有这样的评估,可以使用一个模型来违反那些假设使得该模型不再适用于有关数据,并可能导致对组织有负面影响的不良预测和不正确的结论。
第二种假设,商业假设有点更难以捉摸。通过对模型的了解,数据科学家知道每种类型的假设必须对其使用有效并可以系统地检查它们。另一方面,商业假设可以完全无法识别并深深地纠缠于问题及其框架。有一次,我们正在与一位正在试图了解用户与他们的应用程序如何进行互动以及发生什么交互信号可能会流失的用户的客户进行合作,他们深深地嵌入在假设出现问题的框架中,他们的假设是用户群是由有经验的厨师组成,并希望通过复杂的食谱提高他们的烹饪水平。事实上,用户群主要由无经验的用户组成,试图找到快速、易于准备的食物的食谱。当我们发现客户假设是错误后,他们不得不开始理解一整套新的问题以告知之后的应用开发。
在验证这些技术和商业假设的同时,数据科学家将系统地评估每个数据字段的内容及其与其他变量的相互作用,特别是表示企业想要了解或预测的行为的关键度量(例如使用生命周期、支出)。人类是自然模式识别器,通过以不同的方式对数据进行详尽的可视化,并将这些可视化策略性地配置在一起,数据科学家可以利用其模式识别能力来识别行为的潜在原因、识别潜在的有问题或虚假的数据点以及开发可以通知其分析和模式的假设。
建立对数据的直觉
为什么EDA是更先进的建模前采取的必要步骤,还有一个较为具体的原因是数据科学家需要亲自熟练掌握数据,并为培养一种对数据是什么的直觉,这种直觉对于能够快速识别何时出现问题尤为重要。比如在EDA中,绘制使用寿命与年龄曲线并进行比较,可以发现年轻用户倾向于停留某个产品的时间更长,那么结论是当年龄下降时会增加使用周期。如果训练的模型显示不同的行为,就会很快意识到应该调查发生了什么,并确保没有犯任何的错误。没有EDA,数据突出的问题或模型的实施中的错误会被长时间忽视,这可能会导致基于错误信息做出决策。
验证数据是不是像你认为的那样
在Tukey风格的EDA中,分析师通常很清楚他们分析的数据是如何生成的。然而,现在随着组织内部生成大量数据集以及获取的第三方数据,分析师通常远离数据生成的过程。如果数据不是你认为的那样,那么你的结果可能会受到不良影响,更糟的是误解后采取的行动。
这个例子会展示数据生成的方式可能被误解,让我们来具体看看该例子:A公司正在尝试预测哪些用户将订阅新产品以瞄准其产品定位。他们正在努力开发一个模型,但每次尝试都会导致糟糕的预测结果。然后有人认为执行广泛的EDA,他们最初认为这是没有必要的。但结果表明,预测的用户是控制员工订阅的产品的较大企业账户的一部分。这种控制意味着用户可以以各种方式在数据中看起来完全相同,但具有不同的目标结果,这意味着个人层面的数据几乎没有能力告知预测。在这种情形中,EDA不仅在技术问题上暴露了所采取方法的技术问题,而且还表明出现的错误问题。如果用户的行为受到其组织的控制,则无法对用户进行定位。该公司需要瞄准并预测新产品订阅的企业帐户。
我们已经看到数据生成过程中被错误地假设的其他例子:
- 数据在产品的相同版本或跨平台上生成。
- 数据根据X时区或相同的跨时区被盖上时间戳。
- 记录所有活动的数据,但仅在用户登录时记录。
- 用户标识符保持不变或标识符唯一。
如何去获得这些所有的价值呢?
既然知道了EDA为什么是有价值的,你可能想知道如何去实现EDA。一种方法是参加4月3号举办的TDWI讨论会,会上将探讨EDA的***方法,另外还有一些针对各种EDA方法发布的博客。以下博客强调了EDA获得的见解: