有时候人们并不关注这些细节,但这方面的知识肯定有用,尤其是当你正在编写与测试或errors相关的库。例如这个星期我们的chai中出现了一个令人惊叹的Pull Request,它大大改进了我们处理堆栈跟踪的方式,并在用户断言失败时提供了更多的信息。

操作堆栈记录可以让你清理无用数据,并集中精力处理重要事项。此外,当你真正弄清楚Error及其属性,你将会更有信心地利用它。
本文开头部分或许太过于简单,但当你开始处理堆栈记录时,它将变得稍微有些复杂,所以请确保你在开始这个那部分章节之前已经充分理解前面的内容。
堆栈调用如何工作
在谈论errors之前我们必须明白堆栈调用如何工作。它非常简单,但对于我们将要深入的内容而言却是至关重要的。如果你已经知道这部分内容,请随时跳过本节。
每当函数被调用,它都会被推到堆栈的顶部。函数执行完毕,便会从堆栈顶部移除。
这种数据结构的有趣之处在于***一个入栈的将会***个从堆栈中移除,这也就是我们所熟悉的LIFO(后进,先出)特性。
这也就是说我们在函数x中调用函数y,那么对应的堆栈中的顺序为x y。
假设你有下面这样的代码:
- function c() {
- console.log('c');
- }
- function b() {
- console.log('b');
- c();
- }
- function a() {
- console.log('a');
- b();
- }
- a();
在上面这里例子中,当执行a函数时,a便会添加到堆栈的顶部,然后当b函数在a函数中被调用,b也会被添加到堆栈的顶部,依次类推,在b中调用c也会发生同样的事情。
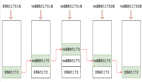
当c执行时,堆栈中的函数的顺序为a b c
c执行完毕后便会从栈顶移除,这时控制流重新回到了b中,b执行完毕同样也会从栈顶移除,***控制流又回到了a中,***a执行完毕,a也从堆栈中移除。
我们可以利用console.trace()来更好的演示这种行为,它会在控制台打印出当前堆栈中的记录。此外,通常而言你应该从上到下读取堆栈记录。想想下面的每一行代码都是在哪调用的。
- function c() {
- console.log('c');
- console.trace();
- }
- function b() {
- console.log('b');
- c();
- }
- function a() {
- console.log('a');
- b();
- }
- a();
在Node REPL服务器上运行上述代码会得到如下结果:
- Trace
- at c (repl:3:9)
- at b (repl:3:1)
- at a (repl:3:1)
- at repl:1:1 // <-- For now feel free to ignore anything below this point, these are Node's internals
- at realRunInThisContextScript (vm.js:22:35)
- at sigintHandlersWrap (vm.js:98:12)
- at ContextifyScript.Script.runInThisContext (vm.js:24:12)
- at REPLServer.defaultEval (repl.js:313:29)
- at bound (domain.js:280:14)
- at REPLServer.runBound [as eval] (domain.js:293:12)
如你所见,当我们在c中打印堆栈,堆栈中的记录为a,b,c。
如果我们现在在b中并且在c执行完之后打印堆栈,我们将会发现c已经从堆栈的顶部移除,只剩下了a和b。
- function c() {
- console.log('c');
- }
- function b() {
- console.log('b');
- c();
- console.trace();
- }
- function a() {
- console.log('a');
- b();
- }
- a();
正如你看到的那样,堆栈中已经没有c,因为它已经完成运行,已经被弹出去了。
- Trace
- at b (repl:4:9)
- at a (repl:3:1)
- at repl:1:1 // <-- For now feel free to ignore anything below this point, these are Node's internals
- at realRunInThisContextScript (vm.js:22:35)
- at sigintHandlersWrap (vm.js:98:12)
- at ContextifyScript.Script.runInThisContext (vm.js:24:12)
- at REPLServer.defaultEval (repl.js:313:29)
- at bound (domain.js:280:14)
- at REPLServer.runBound [as eval] (domain.js:293:12)
- at REPLServer.onLine (repl.js:513:10)
总结:调用方法,方法便会添加到堆栈顶部,执行完毕之后,它就会从堆栈中弹出。
Error对象 和 Error处理
当程序发生错误时,通常都会抛出一个Error对象。Error对象也可以作为一个原型,用户可以扩展它并创建自定义错误。
Error.prototype对象通常有以下属性:
- constructor- 实例原型的构造函数。
- message - 错误信息
- name - 错误名称
以上都是标准属性,(但)有时候每个环境都有其特定的属性,在例如Node,Firefox,Chorme,Edge,IE 10+,Opera 和 Safari 6+ 中,还有一个包含错误堆栈记录的stack属性。错误堆栈记录包含从(堆栈底部)它自己的构造函数到(堆栈顶部)所有的堆栈帧。
如果想了解更多关于Error对象的具体属性,我强烈推荐MDN上的这篇文章。
抛出错误必须使用throw关键字,你必须将可能抛出错误的代码包裹在try代码块内并紧跟着一个catch代码块来捕获抛出的错误。
正如Java中的错误处理,try/catch代码块后紧跟着一个finally代码块在JavaScript中也是同样允许的,无论try代码块内是否抛出异常,finally代码块内的代码都会执行。在完成处理之后,***实践是在finally代码块中做一些清理的事情,(因为)无论你的操作是否生效,都不会影响到它的执行。
(鉴于)上面所谈到的所有事情对大多数人来讲都是小菜一碟,那么就让我们来谈一些不为人所知的细节。
try代码块后面不必紧跟着catch,但(此种情况下)其后必须紧跟着finally。这意味着我们可以使用三种不同形式的try语句:
- try...catch
- try...finally
- try...catch...finally
Try语句可以像下面这样互相嵌套:
- try {
- try {
- throw new Error('Nested error.'); // The error thrown here will be caught by its own `catch` clause
- } catch (nestedErr) {
- console.log('Nested catch'); // This runs
- }
- } catch (err) {
- console.log('This will not run.');
- }
你甚至还可以在catch和finally代码块中嵌套try语句:
- try {
- throw new Error('First error');
- } catch (err) {
- console.log('First catch running');
- try {
- throw new Error('Second error');
- } catch (nestedErr) {
- console.log('Second catch running.');
- }
- }
- try {
- console.log('The try block is running...');
- } finally {
- try {
- throw new Error('Error inside finally.');
- } catch (err) {
- console.log('Caught an error inside the finally block.');
- }
- }
还有很重要的一点值得注意,那就是我们甚至可以大可不必抛出Error对象。尽管这看起来非常cool且非常自由,但实际并非如此,尤其是对开发第三方库的开发者来说,因为他们必须处理用户(使用库的开发者)的代码。由于缺乏标准,他们并不能把控用户的行为。你不能相信用户并简单的抛出一个Error对象,因为他们不一定会那么做而是仅仅抛出一个字符串或者数字(鬼知道用户会抛出什么)。这也使得处理必要的堆栈跟踪和其他有意义的元数据变得更加困难。
假设有以下代码:
- function runWithoutThrowing(func) {
- try {
- func();
- } catch (e) {
- console.log('There was an error, but I will not throw it.');
- console.log('The error\'s message was: ' + e.message)
- }
- }
- function funcThatThrowsError() {
- throw new TypeError('I am a TypeError.');
- }
- runWithoutThrowing(funcThatThrowsError);
如果你的用户像上面这样传递一个抛出Error对象的函数给runWithoutThrowing函数(那就谢天谢地了),然而总有些人偷想懒直接抛出一个String,那你就麻烦了:
- function runWithoutThrowing(func) {
- try {
- func();
- } catch (e) {
- console.log('There was an error, but I will not throw it.');
- console.log('The error\'s message was: ' + e.message)
- }
- }
- function funcThatThrowsString() {
- throw 'I am a String.';
- }
- runWithoutThrowing(funcThatThrowsString);
现在第二个console.log会打印出 the error’s message is undefined.这么看来也没多大的事(后果)呀,但是如果您需要确保某些属性存在于Error对象上,或以另一种方式(例如Chai的throws断言 does))处理Error对象的特定属性,那么你做需要更多的工作,以确保它会正常工资。
此外,当抛出的值不是Error对象时,你无法访问其他重要数据,例如stack,在某些环境中它是Error对象的一个属性。
Errors也可以像其他任何对象一样使用,并不一定非得要抛出他们,这也是它们为什么多次被用作回调函数的***个参数(俗称 err first)。 在下面的fs.readdir()例子中就是这么用的。
- const fs = require('fs');
- fs.readdir('/example/i-do-not-exist', function callback(err, dirs) {
- if (err instanceof Error) {
- // `readdir` will throw an error because that directory does not exist
- // We will now be able to use the error object passed by it in our callback function
- console.log('Error Message: ' + err.message);
- console.log('See? We can use Errors without using try statements.');
- } else {
- console.log(dirs);
- }
- });
***,在rejecting promises时也可以使用Error对象。这使得它更容易处理promise rejections:
- new Promise(function(resolve, reject) {
- reject(new Error('The promise was rejected.'));
- }).then(function() {
- console.log('I am an error.');
- }).catch(function(err) {
- if (err instanceof Error) {
- console.log('The promise was rejected with an error.');
- console.log('Error Message: ' + err.message);
- }
- });
操纵堆栈跟踪
上面啰嗦了那么多,***的重头戏来了,那就是如何操纵堆栈跟踪。
本章专门针对那些像NodeJS支Error.captureStackTrace的环境。
Error.captureStackTrace函数接受一个object作为***个参数,第二个参数是可选的,接受一个函数。capture stack trace 捕获当前堆栈跟踪,并在目标对象中创建一个stack属性来存储它。如果提供了第二个参数,则传递的函数将被视为调用堆栈的终点,因此堆栈跟踪将仅显示调用该函数之前发生的调用。
让我们用例子来说明这一点。首先,我们将捕获当前堆栈跟踪并将其存储在公共对象中。
- const myObj = {};
- function c() {
- }
- function b() {
- // Here we will store the current stack trace into myObj
- Error.captureStackTrace(myObj);
- c();
- }
- function a() {
- b();
- }
- // First we will call these functions
- a();
- // Now let's see what is the stack trace stored into myObj.stack
- console.log(myObj.stack);
- // This will print the following stack to the console:
- // at b (repl:3:7) <-- Since it was called inside B, the B call is the last entry in the stack
- // at a (repl:2:1)
- // at repl:1:1 <-- Node internals below this line
- // at realRunInThisContextScript (vm.js:22:35)
- // at sigintHandlersWrap (vm.js:98:12)
- // at ContextifyScript.Script.runInThisContext (vm.js:24:12)
- // at REPLServer.defaultEval (repl.js:313:29)
- // at bound (domain.js:280:14)
- // at REPLServer.runBound [as eval] (domain.js:293:12)
- // at REPLServer.onLine (repl.js:513:10)
不知道你注意到没,我们首先调用了a(a入栈),然后我们a中又调用了b(b入栈且在a之上)。然后在b中我们捕获了当前堆栈记录并将其存储在myObj中。因此在控制台中才会按照b a的顺序打印堆栈。
现在让我们给Error.captureStackTrace传递一个函数作为第二个参数,看看会发生什么:
- const myObj = {};
- function d() {
- // Here we will store the current stack trace into myObj
- // This time we will hide all the frames after `b` and `b` itself
- Error.captureStackTrace(myObj, b);
- }
- function c() {
- d();
- }
- function b() {
- c();
- }
- function a() {
- b();
- }
- // First we will call these functions
- a();
- // Now let's see what is the stack trace stored into myObj.stack
- console.log(myObj.stack);
- // This will print the following stack to the console:
- // at a (repl:2:1) <-- As you can see here we only get frames before `b` was called
- // at repl:1:1 <-- Node internals below this line
- // at realRunInThisContextScript (vm.js:22:35)
- // at sigintHandlersWrap (vm.js:98:12)
- // at ContextifyScript.Script.runInThisContext (vm.js:24:12)
- // at REPLServer.defaultEval (repl.js:313:29)
- // at bound (domain.js:280:14)
- // at REPLServer.runBound [as eval] (domain.js:293:12)
- // at REPLServer.onLine (repl.js:513:10)
- // at emitOne (events.js:101:20)
当把b传给Error.captureStackTraceFunction时,它隐藏了b本身以及它之后所有的调用帧。因此控制台仅仅打印出一个a。
至此你应该会问自己:“这到底有什么用?”。这非常有用,因为你可以用它来隐藏与用户无关的内部实现细节。在Chai中,我们使用它来避免向用户显示我们是如何实施检查和断言本身的不相关的细节。
操作堆栈追踪实战
正如我在上一节中提到的,Chai使用堆栈操作技术使堆栈跟踪更加与我们的用户相关。下面将揭晓我们是如何做到的。
首先,让我们来看看当断言失败时抛出的AssertionError的构造函数:
- // `ssfi` stands for "start stack function". It is the reference to the
- // starting point for removing irrelevant frames from the stack trace
- function AssertionError (message, _props, ssf) {
- var extend = exclude('name', 'message', 'stack', 'constructor', 'toJSON')
- , props = extend(_props || {});
- // Default values
- this.message = message || 'Unspecified AssertionError';
- this.showDiff = false;
- // Copy from properties
- for (var key in props) {
- this[key] = props[key];
- }
- // Here is what is relevant for us:
- // If a start stack function was provided we capture the current stack trace and pass
- // it to the `captureStackTrace` function so we can remove frames that come after it
- ssf = ssf || arguments.callee;
- if (ssf && Error.captureStackTrace) {
- Error.captureStackTrace(this, ssf);
- } else {
- // If no start stack function was provided we just use the original stack property
- try {
- throw new Error();
- } catch(e) {
- this.stack = e.stack;
- }
- }
- }
如你所见,我们使用Error.captureStackTrace捕获堆栈追踪并将它存储在我们正在创建的AssertError实例中(如果存在的话),然后我们将一个起始堆栈函数传递给它,以便从堆栈跟踪中删除不相关的调用帧,它只显示Chai的内部实现细节,最终使堆栈变得清晰明了。
现在让我们来看看@meeber在这个令人惊叹的PR中提交的代码。
在你开始看下面的代码之前,我必须告诉你addChainableMethod方法是干啥的。它将传递给它的链式方法添加到断言上,它也用包含断言的方法标记断言本身,并将其保存在变量ssfi(启动堆栈函数指示符)中。这也就意味着当前断言将会是堆栈中的***一个调用帧,因此我们不会在堆栈中显示Chai中的任何进一步的内部方法。我没有添加整个代码,因为它做了很多事情,有点棘手,但如果你想读它,点我阅读。
下面的这个代码片段中,我们有一个lengOf断言的逻辑,它检查一个对象是否有一定的length。我们希望用户可以像这样来使用它:expect(['foo', 'bar']).to.have.lengthOf(2)。
- function assertLength (n, msg) {
- if (msg) flag(this, 'message', msg);
- var obj = flag(this, 'object')
- , ssfi = flag(this, 'ssfi');
- // Pay close attention to this line
- new Assertion(obj, msg, ssfi, true).to.have.property('length');
- var len = obj.length;
- // This line is also relevant
- this.assert(
- len == n
- , 'expected #{this} to have a length of #{exp} but got #{act}'
- , 'expected #{this} to not have a length of #{act}'
- , n
- , len
- );
- }
- Assertion.addChainableMethod('lengthOf', assertLength, assertLengthChain);
Assertion.addChainableMethod('lengthOf', assertLength, assertLengthChain);
在上面的代码片段中,我突出强调了与我们现在相关的代码。让我们从调用this.assert开始说起。
以下是this.assert方法的源代码:
- Assertion.prototype.assert = function (expr, msg, negateMsg, expected, _actual, showDiff) {
- var ok = util.test(this, arguments);
- if (false !== showDiff) showDiff = true;
- if (undefined === expected && undefined === _actual) showDiff = false;
- if (true !== config.showDiff) showDiff = false;
- if (!ok) {
- msg = util.getMessage(this, arguments);
- var actual = util.getActual(this, arguments);
- // This is the relevant line for us
- throw new AssertionError(msg, {
- actual: actual
- , expected: expected
- , showDiff: showDiff
- }, (config.includeStack) ? this.assert : flag(this, 'ssfi'));
- }
- };
assert方法负责检查断言布尔表达式是否通过。如果不通过,我们则实例化一个AssertionError。不知道你注意到没,在实例化AssertionError时,我们也给它传递了一个堆栈追踪函数指示器(ssfi),如果配置的includeStack处于开启状态,我们通过将this.assert本身传递给它来为用户显示整个堆栈跟踪。反之,我们则只显示ssfi标记中存储的内容,隐藏掉堆栈跟踪中更多的内部实现细节。
现在让我们来讨论下一行和我们相关的代码吧:
- `new Assertion(obj, msg, ssfi, true).to.have.property('length');`
As you can see here we are passing the content we’ve got from the ssfi flag when creating our nested assertion. This means that when the new assertion gets created it will use this function as the starting point for removing unuseful frames from the stack trace. By the way, this is the Assertion constructor: 如你所见,我们在创建嵌套断言时将从ssfi标记中的内容传递给了它。这意味着新创建的断言会使用那个方法作为起始调用帧,从而可以从堆栈追踪中清除没有的调用栈。顺便也看下Assertion的构造器吧:
- function Assertion (obj, msg, ssfi, lockSsfi) {
- // This is the line that matters to us
- flag(this, 'ssfi', ssfi || Assertion);
- flag(this, 'lockSsfi', lockSsfi);
- flag(this, 'object', obj);
- flag(this, 'message', msg);
- return util.proxify(this);
- }
不知道你是否还记的我先前说过的addChainableMethod方法,它使用自己的父级方法设置ssfi标志,这意味着它始终处于堆栈的底部,我们可以删除它之上的所有调用帧。
通过将ssfi传递给嵌套断言,它只检查我们的对象是否具有长度属性,我们就可以避免重置我们将要用作起始指标器的调用帧,然后在堆栈中可以看到以前的addChainableMethod。
这可能看起来有点复杂,所以让我们回顾一下我们想从栈中删除无用的调用帧时Chai中所发生的事情:
- 当我们运行断言时,我们将它自己的方法作为移除堆栈中的下一个调用帧的参考
- 断言失败时,我们会移除所有我们在参考帧之后保存的内部调用帧。
- 如果存在嵌套的断言。我们必须依旧使用当前断言的父方法作为删除下一个调用帧的参考点,因此我们把当前的ssfi(起始函数指示器)传递给我们所创建的断言,以便它可以保存。