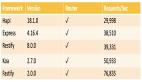
爬虫是数据抓取的重要手段之一,而以 Scrapy、Crawler4j、Nutch 为代表的开源框架能够帮我们快速构建分布式爬虫系统;就笔者浅见,我们在开发大规模爬虫系统时可能会面临以下挑战:
- 网页抓取:最简单的抓取就是使用 HTTPClient 或者 fetch 或者 request 这样的 HTTP 客户端。现在随着单页应用这样富客户端应用的流行,我们可以使用 Selenium、PhantomJS 这样的 Headless Brwoser 来动态执行脚本进行渲染。
- 网页解析:对于网页内容的抽取与解析是个很麻烦的问题,DOM4j、Cherrio、beautifulsoup 这些为我们提供了基本的解析功能。笔者也尝试过构建全配置型的爬虫,类似于 Web-Scraper,然而还是输给了复杂多变,多层嵌套的 iFrame 页面。这里笔者秉持代码即配置的理念,对于使用配置来声明的内建复杂度比较低,但是对于那些业务复杂度较高的网页,整体复杂度会以几何倍数增长。而使用代码来声明其内建复杂度与门槛相对较高,但是能较好地处理业务复杂度较高的网页。笔者在构思未来的交互式爬虫生成界面时,也是希望借鉴 FaaS 的思路,直接使用代码声明整个解析流程,而不是使用配置。
- 反爬虫对抗:类似于淘宝这样的主流网站基本上都有反爬虫机制,它们会对于请求频次、请求地址、请求行为与目标的连贯性等多个维度进行分析,从而判断请求者是爬虫还是真实用户。我们常见的方式就是使用多 IP 或者多代理来避免同一源的频繁请求,或者可以借鉴 GAN 或者增强学习的思路,让爬虫自动地针对目标网站的反爬虫策略进行自我升级与改造。另一个常见的反爬虫方式就是验证码,从最初的混淆图片到现在常见的拖动式验证码都是不小的障碍,我们可以使用图片中文字提取、模拟用户行为等方式来尝试绕过。
- 分布式调度:单机的吞吐量和性能总是有瓶颈的,而分布式爬虫与其他分布式系统一样,需要考虑分布式治理、数据一致性、任务调度等多个方面的问题。笔者个人的感觉是应该将爬虫的工作节点尽可能地无状态化,以 Redis 或者 Consul 这样的能保证高可用性的中心存储存放整个爬虫集群的状态。
- 在线有价值页面预判:Google 经典的 PageRank 能够基于网络中的连接信息判断某个 URL 的有价值程度,从而优先索引或者抓取有价值的页面。而像 Anthelion 这样的智能解析工具能够基于之前的页面提取内容的有价值程度来预判某个 URL 是否有抓取的必要。
- 页面内容提取与存储:对于网页中的结构化或者非结构化的内容实体提取是自然语言处理中的常见任务之一,而自动从海量数据中提取出有意义的内容也涉及到机器学习、大数据处理等多个领域的知识。我们可以使用 Hadoop MapReduce、Spark、Flink 等离线或者流式计算引擎来处理海量数据,使用词嵌入、主题模型、LSTM 等等机器学习技术来分析文本,可以使用 HBase、ElasticSearch 来存储或者对文本建立索引。
笔者本意并非想重新造个轮子,不过在改造我司某个简单的命令式爬虫的过程中发现,很多的调度与监控操作应该交由框架完成。Node.js 在开发大规模分布式应用程序的一致性(JavaScript 的不规范)与性能可能不如 Java 或者 Go。但是正如笔者在上文中提及,JavaScript 的优势在于能够通过同构代码同时运行在客户端与服务端,那么未来对于解析这一步完全可以在客户端调试完毕然后直接将代码运行在服务端,这对于构建灵活多变的解析可能有一定意义。
总而言之,我只是想有一个可扩展、能监控、简单易用的爬虫框架,所以我快速撸了一个 declarative-crawler,目前只是处于原型阶段,尚未发布到 npm 中;希望有兴趣的大大不吝赐教,特别是发现了有同类型的框架可以吱一声,我看看能不能拿来主义,多多学习。
设计思想与架构概览
当笔者几年前编写***个爬虫时,整体思路是典型的命令式编程,即先抓取再解析,***持久化存储,就如下述代码:
- await fetchListAndContentThenIndex(
- 'jsgc',
- section.name,
- section.menuCode,
- section.category
- ).then(() => {
- }).catch(error => {
- console.log(error);
- });
命令式编程相较于声明式编程耦合度更高,可测试性与可控性更低;就好像从 jQuery 切换到 React、Angular、Vue.js 这样的框架,我们应该尽可能将业务之外的事情交由工具,交由框架去管理与解决,这样也会方便我们进行自定义地监控。总结而言,笔者的设计思想主要包含以下几点:
- 关注点分离,整个架构分为了爬虫调度 CrawlerScheduler、Crawler、Spider、dcEmitter、Store、KoaServer、MonitorUI 等几个部分,尽可能地分离职责。
- 声明式编程,每个蜘蛛的生命周期包含抓取、抽取、解析与持久化存储这几个部分;开发者应该独立地声明这几个部分,而完整的调用与调度应该由框架去完成。
- 分层独立可测试,以爬虫的生命周期为例,抽取与解析应当声明为纯函数,而抓取与持久化存储更多的是面向业务,可以进行 Mock 或者包含副作用进行测试。
整个爬虫网络架构如下所示,目前全部代码参考这里。
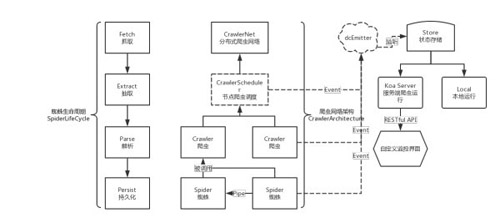
自定义蜘蛛与爬虫
我们以抓取某个在线列表与详情页为例,首先我们需要针对两个页面构建蜘蛛,注意,每个蜘蛛负责针对某个 URL 进行抓取与解析,用户应该首先编写列表爬虫,其需要声明 model 属性、复写 before_extract、parse 与 persist 方法,各个方法会被串行调用。另一个需要注意的是,我们爬虫可能会外部传入一些配置信息,统一的声明在了 extra 属性内,这样在持久化时也能用到。
- type ExtraType = {
- module?: string,
- name?: string,
- menuCode?: string,
- category?: string
- };
- export default class UAListSpider extends Spider {
- displayName = "通用公告列表蜘蛛";
- extra: ExtraType = {};
- model = {
- $announcements: 'tr[height="25"]'
- };
- constructor(extra: ExtraType) {
- super();
- this.extra = extra;
- }
- before_extract(pageHTML: string) {
- return pageHTML.replace(/<TR height=\d*>/gim, "<tr height=25>");
- }
- parse(pageElements: Object) {
- let announcements = [];
- let announcementsLength = pageElements.$announcements.length;
- for (let i = 0; i < announcementsLength; i++) {
- let $announcement = $(pageElements.$announcements[i]);
- let $a = $announcement.find("a");
- let title = $a.text();
- let href = $a.attr("href");
- let date = $announcement.find('td[align="right"]').text();
- announcements.push({ title: title, date: date, href: href });
- }
- return announcements;
- }
- /**
- * @function 对采集到的数据进行持久化更新
- * @param pageObject
- */
- async persist(announcements): Promise<boolean> {
- let flag = true;
- // 这里每个 URL 对应一个公告数组
- for (let announcement of announcements) {
- try {
- await insertOrUpdateAnnouncement({
- ...this.extra,
- ...announcement,
- infoID: href2infoID(announcement.href)
- });
- } catch (err) {
- flag = false;
- }
- }
- return flag;
- }
- }
我们可以针对这个蜘蛛进行单独测试,这里使用 Jest。注意,这里为了方便描述没有对抽取、解析等进行单元测试,在大型项目中我们是建议要加上这些纯函数的测试用例。
- var expect = require("chai").expect;
- import UAListSpider from "../../src/universal_announcements/UAListSpider.js";
- let uaListSpider: UAListSpider = new UAListSpider({
- module: "jsgc",
- name: "房建市政招标公告-服务类",
- menuCode: "001001/001001001/00100100100",
- category: "1"
- }).setRequest(
- "http://ggzy.njzwfw.gov.cn/njggzy/jsgc/001001/001001001/001001001001/?Paging=1",
- {}
- );
- test("抓取公共列表", async () => {
- let announcements = await uaListSpider.run(false);
- expect(announcements, "返回数据为列表并且长度大于10").to.have.length.above(2);
- });
- test("抓取公共列表 并且进行持久化操作", async () => {
- let announcements = await uaListSpider.run(true);
- expect(announcements, "返回数据为列表并且长度大于10").to.have.length.above(2);
- });
同理,我们可以定义对于详情页的蜘蛛:
- export default class UAContentSpider extends Spider {
- displayName = "通用公告内容蜘蛛";
- model = {
- // 标题
- $title: "#tblInfo #tdTitle b",
- // 时间
- $time: "#tblInfo #tdTitle font",
- // 内容
- $content: "#tblInfo #TDContent"
- };
- parse(pageElements: Object) {
- ...
- }
- async persist(announcement: Object) {
- ...
- }
- }
在定义完蜘蛛之后,我们可以定义负责爬取整个系列任务的 Crawler,注意,Spider 仅负责爬取单个页面,而分页等操作是由 Crawler 进行:
- /**
- * @function 通用的爬虫
- */
- export default class UACrawler extends Crawler {
- displayName = "通用公告爬虫";
- /**
- * @构造函数
- * @param config
- * @param extra
- */
- constructor(extra: ExtraType) {
- super();
- extra && (this.extra = extra);
- }
- initialize() {
- // 构建所有的爬虫
- let requests = [];
- for (let i = startPage; i < endPage + 1; i++) {
- requests.push(
- buildRequest({
- ...this.extra,
- page: i
- })
- );
- }
- this.setRequests(requests)
- .setSpider(new UAListSpider(this.extra))
- .transform(announcements => {
- if (!Array.isArray(announcements)) {
- throw new Error("爬虫连接失败!");
- }
- return announcements.map(announcement => ({
- url: `http://ggzy.njzwfw.gov.cn/${announcement.href}`
- }));
- })
- .setSpider(new UAContentSpider(this.extra));
- }
- }
一个 Crawler 最关键的就是 initialize 函数,需要在其中完成爬虫的初始化。首先我们需要构造所有的种子链接,这里既是多个列表页;然后通过 setSpider 方法加入对应的蜘蛛。不同蜘蛛之间通过自定义的 Transformer 函数来从上一个结果中抽取出所需要的链接传入到下一个蜘蛛中。至此我们爬虫网络的关键组件定义完毕。
本地运行
定义完 Crawler 之后,我们可以通过将爬虫注册到 CrawlerScheduler 来运行爬虫:
- const crawlerScheduler: CrawlerScheduler = new CrawlerScheduler();
- let uaCrawler = new UACrawler({
- module: "jsgc",
- name: "房建市政招标公告-服务类",
- menuCode: "001001/001001001/00100100100",
- category: "1"
- });
- crawlerScheduler.register(uaCrawler);
- dcEmitter.on("StoreChange", () => {
- console.log("-----------" + new Date() + "-----------");
- console.log(store.crawlerStatisticsMap);
- });
- crawlerScheduler.run().then(() => {});
这里的 dcEmitter 是整个状态的中转站,如果选择使用本地运行,可以自己监听 dcEmitter 中的事件:
- -----------Wed Apr 19 2017 22:12:54 GMT+0800 (CST)-----------
- { UACrawler:
- CrawlerStatistics {
- isRunning: true,
- spiderStatisticsList: { UAListSpider: [Object], UAContentSpider: [Object] },
- instance:
- UACrawler {
- name: 'UACrawler',
- displayName: '通用公告爬虫',
- spiders: [Object],
- transforms: [Object],
- requests: [Object],
- isRunning: true,
- extra: [Object] },
- lastStartTime: 2017-04-19T14:12:51.373Z } }
服务端运行
我们也可以以服务的方式运行爬虫:
- const crawlerScheduler: CrawlerScheduler = new CrawlerScheduler();
- let uaCrawler = new UACrawler({
- module: "jsgc",
- name: "房建市政招标公告-服务类",
- menuCode: "001001/001001001/00100100100",
- category: "1"
- });
- crawlerScheduler.register(uaCrawler);
- new CrawlerServer(crawlerScheduler).run().then(()=>{},(error)=>{console.log(error)});
此时会启动框架内置的 Koa 服务器,允许用户通过 RESTful 接口来控制爬虫网络与获取当前状态。
接口说明
关键字段
- 爬虫
- // 判断爬虫是否正在运行
- isRunning: boolean = false;
- // 爬虫***一次激活时间
- lastStartTime: Date;
- // 爬虫***一次运行结束时间
- lastFinishTime: Date;
- // 爬虫***的异常信息
- lastError: Error;
- 蜘蛛
- // ***一次运行时间
- lastActiveTime: Date;
- // 平均总执行时间 / ms
- executeDuration: number = 0;
- // 爬虫次数统计
- count: number = 0;
- // 异常次数统计
- errorCount: number = 0;
- countByTime: { [number]: number } = {};
localhost:3001/ 获取当前爬虫运行状态
- 尚未启动
- [
- {
- name: "UACrawler",
- displayName: "通用公告爬虫",
- isRunning: false,
- }
- ]
- 正常返回
- [
- {
- name: "UACrawler",
- displayName: "通用公告爬虫",
- isRunning: true,
- lastStartTime: "2017-04-19T06:41:55.407Z"
- }
- ]
- 出现错误
- [
- {
- name: "UACrawler",
- displayName: "通用公告爬虫",
- isRunning: true,
- lastStartTime: "2017-04-19T06:46:05.410Z",
- lastError: {
- spiderName: "UAListSpider",
- message: "抓取超时",
- url: "http://ggzy.njzwfw.gov.cn/njggzy/jsgc/001001/001001001/001001001001?Paging=1",
- time: "2017-04-19T06:47:05.414Z"
- }
- }
- ]
localhost:3001/start 启动爬虫
- {
- message:"OK"
- }
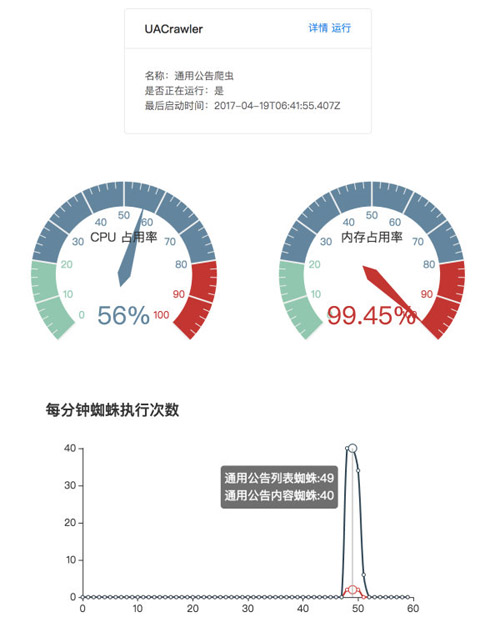
localhost:3001/status 返回当前系统状态
- {
- "cpu":0,
- "memory":0.9945211410522461
- }
localhost:3001/UACrawler 根据爬虫名查看爬虫运行状态
- [
- {
- "name":"UAListSpider",
- "displayName":"通用公告列表蜘蛛",
- "count":6,
- "countByTime":{
- "0":0,
- "1":0,
- "2":0,
- "3":0,
- ...
- "58":0,
- "59":0
- },
- "lastActiveTime":"2017-04-19T06:50:06.935Z",
- "executeDuration":1207.4375,
- "errorCount":0
- },
- {
- "name":"UAContentSpider",
- "displayName":"通用公告内容蜘蛛",
- "count":120,
- "countByTime":{
- "0":0,
- ...
- "59":0
- },
- "lastActiveTime":"2017-04-19T06:51:11.072Z",
- "executeDuration":1000.1596102359835,
- "errorCount":0
- }
- ]
自定义监控界面
CrawlerServer 提供了 RESTful API 来返回当前爬虫的状态信息,我们可以利用 React 或者其他框架来快速搭建监控界面。
【本文是51CTO专栏作者“张梓雄 ”的原创文章,如需转载请通过51CTO与作者联系】