MaxCompute
大数据计算服务 (MaxCompute) 是一种快速、完全托管的 PB/EB 级数据仓库服务。具备万台服务器扩展能力和跨地域容灾能力,是阿里巴巴内部核心大数据计算平台,支撑每日***作业规模。
MaxCompute 是一种统一的大数据计算平台, MaxCompute 向用户提供了完善的数据导入方案以及多种经典的分布式计算模型,比如 SQL 、图计算、流计算和机器学习等,能够更快速的解决用户海量数据计算问题,有效降低企业成本,并保障数据安全。
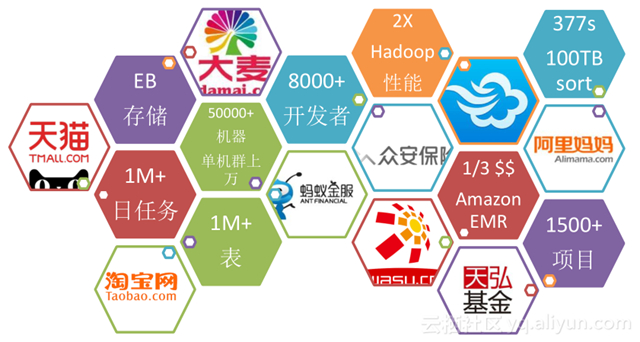
MaxCompute 不只对阿里集团内部用户开放,也向外部开放。天猫、淘宝、蚂蚁金服等都在使用 MaxCompute , MaxCompute 是阿里集团内部最关键的大数据平台,目前, MaxCompute 机器已经有五万多台,数据表是***以上,开发者有 8000 多个,性能上是 hadoop2 倍等,从数据上可以感受到 MaxCompute 是名副其实的海量大数据平台,在业内能处理的数据量以及计算能力也是处于领先地位的。
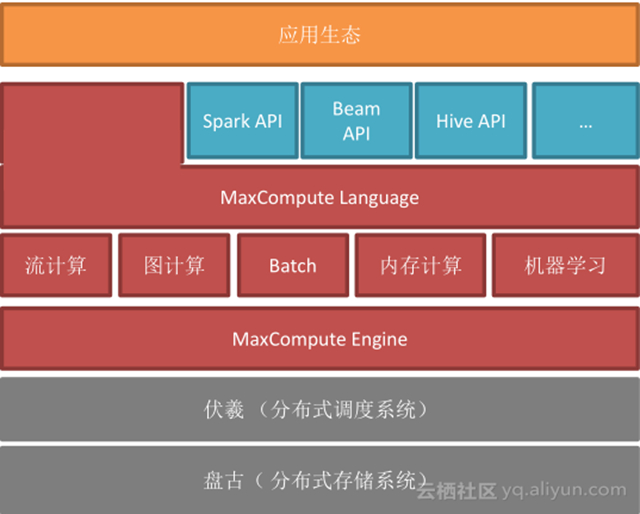
MaxCompute 底层是由阿里自主开发的盘古分布式存储系统和伏羲分布式调度系统组成,在此基础上,我们也开发了 MaxCompute 执行引擎, MaxCompute 是统一的大数据计算平台,既能支持传统经典的批处理,也支持流计算、图计算、内存计算以及机器学习等,从这个角度来看,MaxCompute 与 spark 定位非常相似;在此之上, MaxCompute 支持灵活的语言,为了让用户能够无缝接入 MaxCompute ,我们也支持开源系统好多的 API ,包括 spark API 和 Hive API 等。
批处理计算

目前,对于阿里巴巴甚至业界来说, SQL 类型的批处理是最经典最广泛的应用了, SQL 批处理的流程如下:
用户提交一条类似 SQL 的脚本到 MaxCompute 后, MaxCompute 会对 SQL 脚本进行编译并优化,然后用 Runtime 运行。
大数据计算服务
MaxCompute 要做大数据计算的服务,并不像业界开源的 hadoop 、 spark 提供一套解决方案,我们需要提供一个 365 (天) x24 (小时)的高可靠,高可用的共享大数据计算服务。
那么,有什么好处呢?它可以:
– 使用门槛大大降低,用户不用关心运维升级等
– 共享细粒度使用资源,从而做到低成本,高效率
大数据计算服务强调稳定性,与持续发展之间存在天然的矛盾。在一个稳定运行的大数据计算服务上改进和发布新功能就像“空中换车”,在高速飞行的飞机上替换引擎而同时要保持平稳飞行,其中的挑战难度可想而知。
持续改进和发布中的挑战
- MaxCompute 每天都有***作业。如何能够平稳安全,用户无感知的发布新的功能?如何保证新版本的稳定性,没有 bug ,没有性能的回退?出现问题后如何能够快速止损等等?
- 面对外部用户,在测试时如何保证数据安全可靠呢?
针对以上挑战,我们提出在高可用服务下持续改进和发布了以下技术手段来克服:
– MaxCompute Playback 工具
– MaxCompute Flighting 工具
– MaxCompute 灰度上线,细粒度回滚
编译器Playback工具
MaxCompute 目前主流的仍然是 SQL 类型应用,其中非常关键的模块就是编译优化器,我们需要快速提高我们编译器、优化器的表达能力,以及性能优化水平。
那么,如何能够保证升级过程中没有大的 Regression ?
每天有 100 万 + 个 job ,每天都在变化,如果人工分析的话,每个 script 仅需要 2 分钟,需要91 人年,这是不现实的,所以,我们开发了编译器 Playback 工具。
Playback 工具用来解决编译器和优化器的测试验证功能,利用大数据计算平台的运算能力来自我验证新的编译优化器。
具体原理如下:
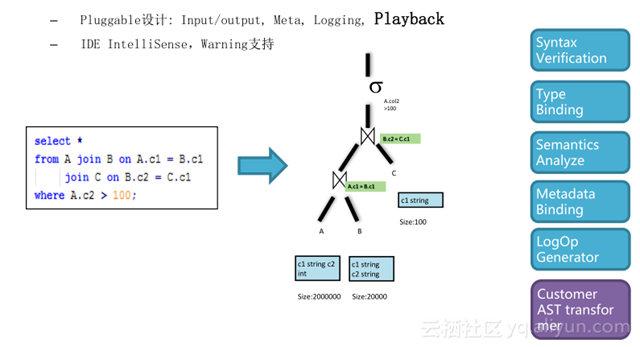
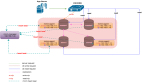
基于 MaxCompute 强大而灵活的编译扩展能力,编译器基于 AST 的编译器模型,使用了经典的 Visitor 模式。 SQL 脚本提交到系统后会将 SQL 脚本转化成抽象语法树,正常情况下的语法验证和分析等实现了标准的 visitor , visitor 对应于 AST 的验证等扩展性是非常好的,除了标准的 visitor 加入后,还可以加入一些有针对性的检查验证抽象语法树的新 visitor ,将这些 visitor 加到语法树上,就可以验证新的编译器和优化器生成出来的各种各样的产出是否 OK ,以此来验证新的编译器和优化器的能力。
自我验证
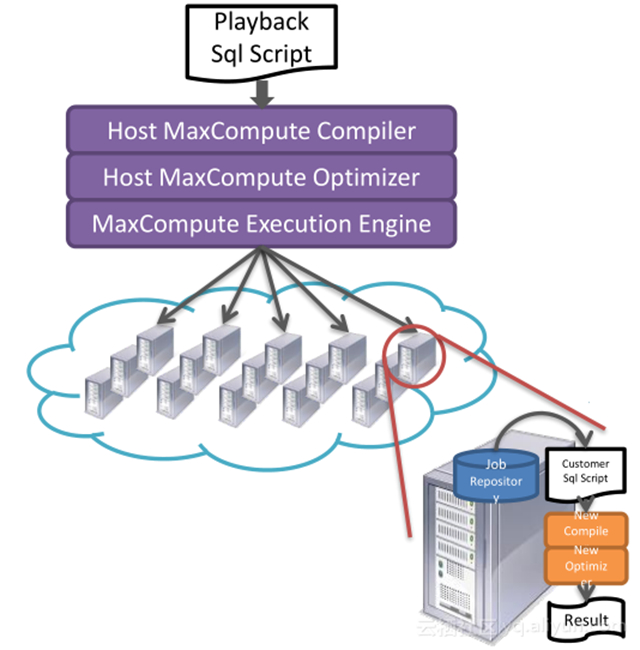
整个验证过程如下:
1. 当用户提交一条 SQL 脚本发给 MaxCompute ,利用 MaxCompute 本身灵活数据处理语言来构造分析任务;
2. 利用 MaxCompute 本身超大规模计算能力来并行分析海量用户任务,将一段时间用户作业抽出;
3. 利用 MaxCompute 灵活的 UDF 支持且良好的隔离方案,在 UDF 中拉起待测的编译器进行编译,之后再进行详细的结果分析。
整个过程都在 MaxCompute 完善的安全体系保护下,保障用户的知识产权。
Playback 工具还有其它很丰富的作用,比如:
- 进行新版本的验证
- 精确制导找到触发新的优化规则的 query ,验证其查询优化是否符合预期
- 在语义层面对于 query 进行整体数据分析
– 对相应的用户发 warning 推动用户下线过时的语法
– 对 query 整体进行分析来确定下一步开发的重点
– 评估新版本在查询优化在执行计划上的提高程度
Flighting 工具
除了编译器和优化器外,另外有一个关键模块就是执行器。那么,如何保证 MaxCompute 运行器是正确执行的?避免在快速迭代中的正确性问题,从而避免重大的事故?同时,如何保证数据的安全性呢?
传统方式验证运行器,最经典的是用测试集群来验证,该方式验证的缺点如下:
– 调度或者 scalability 等方面的改进往往需要建立一个相同规模的测试集群
- 没有相应的任务负载,无法构造对应场景
- 数据安全问题,使得我们需要脱敏的方式从生产集群拖数据
– 容易人为疏忽,造成数据泄露风险
– 脱敏数据可能造成用户程序 crash ,并且往往不能反映用户运行场景
– 整个测试过程冗长,不能达到测试的目的
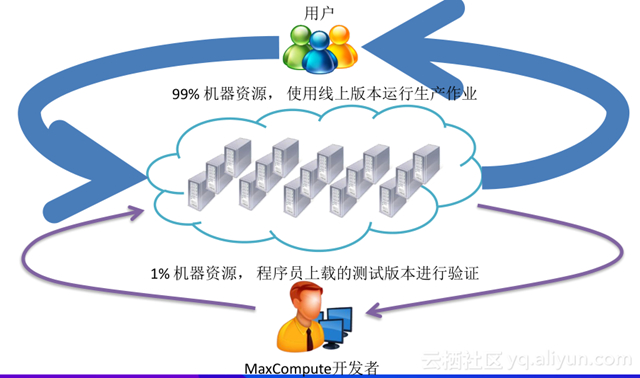
所以我们引入了 flighting 工具来做测试和验证,将 99% 机器资源使用线上版本运行生产作业,1% 机器资源用来为程序员上载的测试版本进行验证。
资源隔离
那么,怎么保证测试验证的作业不去影响线上生产的作业呢?这就需要我们完善资源隔离,具体包括:
- CPU/Memory: 增强 cgroup ,任务优先级
- Disk :统一的存储管理,存储的优先级
- Network : Scalable Traffic Control
- Quota 管理
所以我们能够在保障线上核心业务需求情况下进行 flighting 的测试。
数据安全
从数据安全角度来说,我们的测试不需要人工干预进行数据脱敏; Flighting 的任务的结果不落盘,而是直接对接分析任务产生测试报告:
– 结果正确性: MD5 计算,浮点等不确定性类型的处理
– 执行性能的分析: straggler , data-skew , schedule quality
灰度上线
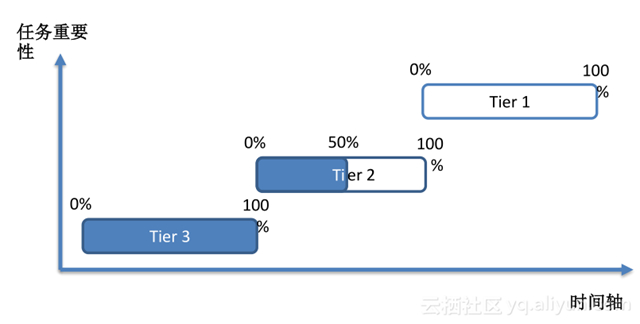
SQL 的关键模块如编译优化和执行都可以得到有效测试和验证,接下来就可以上线了,上线时也会有很大风险,因此,我们实行灰度上线。按照任务的重要性进行分级,支持细粒度发布,并且支持瞬时回滚,控制风险到最小。
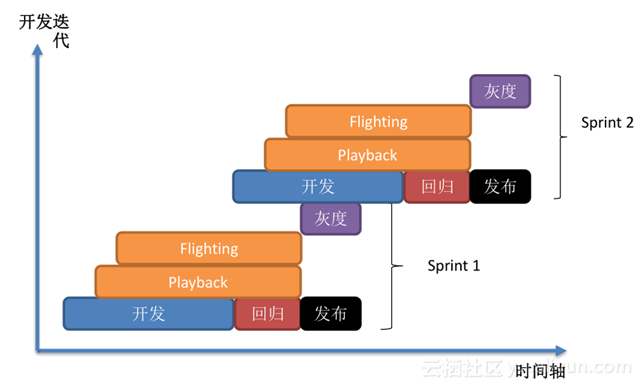
开发新功能后做回归,回归后发布,开始时往往有新功能后,就进行验证,如果新功能是针对编译器、优化器,就用 playback 验证,针对 Runtime 就用 flighting 验证,所有测试验证结束后,就到灰度发布阶段,直到所有任务***发布上线后,我们就认为这一次开发迭代是成功的,以此类推,不停的向前演进,既能保证服务可靠稳定运行的同时,将我们的性能提升,以满足用户的各种需求。