












背景
最近发现我们产品在打开广告链接(Webview)时有一定概率会非常慢,白屏时间超过 10s,追查广告的过程中遇到不少有意思的事情,感觉颇有收获。在这里分享一下,主要想聊一聊追查 bug 时的那些方法论,当然也不能太虚,还是要带一点干货,比如 WireShark 的使用。
Bug 复现
遇到 bug 后的***件事当然是复现。经过一番测试我发现 bug 几乎只会主要出现在 iPhone6 这种老旧机型上,而笔者的 7Plus 则基本没有问题。4G 和 Wifi 下都有一定概率出现,Wifi 似乎更加频繁。
其实有点经验的开发者看到这里心里应该有点谱了,这应该不是客户端的 bug,更可能是由于广告主网页质量太低或者网络环境不稳定导致。但作为一个靠谱的程序员,怎么能把这种毫无根据的猜测向上级汇报呢?
关注点分离
我们知道加载网页可以由两部分时间组成,一个是本地的处理时间,另一个是网络加载的时间。两者的分水岭应该在 UIWebview 的 shouldStartLoadWithRequest 方法上。这个方法调用之前是本地处理耗时,调用之后是网络加载的请求。所以我们可以把事情分成两部分来看:
从 cell 接受点击事件的 didSelectedRowAtIndexPath 起到 UIWebview 的 shouldStartLoadWithRequest 为止。
从 shouldStartLoadWithRequest 起到 UIWebview 的 webViewDidFinishLoad 为止。
由于 Bug 是偶现,所以不可能长时间用 Xcode 调试,所以还要注意写一个简单的工具,将每次的 Log 日志持久化存下来,保留每一步的函数调用、耗时、具体参数等。这样一旦复现出来,可以连上电脑读取手机中的日志。
本地处理
本地处理的耗时相对较短,但逻辑一点都不简单。在我个人看来,从展示 UITableview 到处理点击事件的流程,足以反映出一个团队的技术实力。毫不夸张的说,能把这个小业务做到***的团队***,其中必然涉及到 MVC/MVVM 等架构的选型设计与具体实现、网络层与持久化层的封装、项目模块化的拆分等核心知识点。我会尽快抽空专门一些篇文章来聊聊这些,这里就不再赘述。
花了一番功夫整理好业务流程、做好统计以后还真有一些收获。客户端的逻辑是 pushViewController 动画执行完后才发送请求,白白浪费了大约 0.5s 的动画时间,这些时间原本可以用来加载网页。
网络请求
借助日志我还发现,本地处理虽然浪费了时间,但这个时间相对稳定,大约在 1s 左右。更大的耗时来自于网络请求部分。一般情况下,打开网页会有短暂的白屏时间,这段时间内系统会加载 HTML 等资源并进行渲染,同时界面上有菊花在转动。
白屏什么时候消失取决于系统什么时候加载完网页,我们无法控制。但菊花消失的时间是已知的,我们的逻辑是写在 webViewDidFinishLoad 中。这么做不一定准确,因为网页重定向时也会调用 webViewDidFinishLoad 方法导致客户端误以为已经加载完成。更加准确的做法可以参考: 如何准确判断 WebView 加载完成,当然这也也仅仅是更准确一些,就 UIWebview 而言,想准确的判断网络是否加载完成几乎是不可能的(感谢 @JackAlan 的实践)。
所以说网络加载还可以细分为两部分,一个是纯白屏时间,另一部分则是出现了网页但还在转动菊花的时间。这是因为一个 Frame(可以是 HTML 也可以是 iFrame) 全部加载完成(包括 CSS/JS 等)后才会调用 webViewDidFinishLoad 方法,所以存在网页已经渲染但还在执行 JS 请求的情况,反映在用户端,就是能看到网页但菊花还在转动。这种情况如果持续时间过久会导致用户不耐烦,但相比于纯粹的白屏时间来说更能被接受一些。
同时我们也可以确定,如果网页已经加载,但 JS 请求还在继续,这就是广告主的网页质量太差导致的。损失应该由他们承担,我们无能为力。而长时间的白屏则是我们应该重点考虑的问题。
小结
其实分析到这里已经可以向领导汇报了。网络加载的耗时一共是三段,***段是本地处理时间,存在性能浪费但时间比较稳定,第二段是网页白屏时间,这段时间内系统的 UIWebView 在请求资源并渲染,第三段是加载网页后的菊花转动时间,一般耗时较少,我们也无法控制。
我们还知道 UIWebView 提供的 API 很少,从开始请求到网页加载结束完全是黑盒模式,几乎无从下手。但作为一名有追求,有理想,有抱负,有技术的四有程序员,怎么能轻言放弃呢?
WireShark
客户端在调试网络时最常用的工具要数 Charles,但它只能调试 HTTP/HTTPS 请求,对 TCP 层就无能为力了。要想了解 HTTP 请求过程中的细节,我们必须要使用威力更大(肯定也更复杂)的武器,也就是本文的主角 WireShark。
一般来说越牛X 的工具长得就越丑,WireShark 也毫不例外的有着一副让人懵逼的外表。
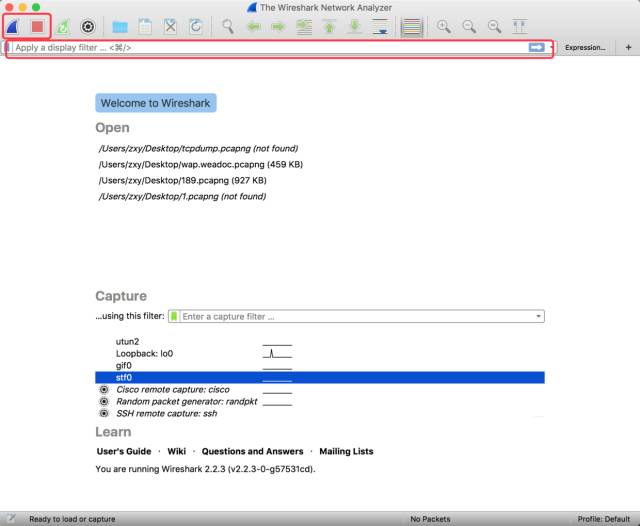
不过不用太急,我们要用到的东西不多,顶部红框里的蓝色鲨鱼标志表示开始监听网络数据,红色按钮一看也能猜出来是停止录制。与 Charles 只监听 HTTP 请求不同的是,WireShark 可以调试到 IP 层甚至更细节,所以它的数据包也更多,几秒钟的时间就会被上千个请求淹没,所以我建议用户略微控制一下监听的时长,或者我们可以在第二个红框中输入过滤条件来减少干扰,这个下文会详细介绍。
WireShark 可以监听本机的网卡,也可以监听手机的网络。使用 WireShark 调试真机时不用连接代理,只需要通过 USB 连接到电脑就行,否则就无法调试 4G 网络了。我们可以用 rvictl -s 设备 UDID 命令来创建一个虚拟的网卡:
rvictl -s 902a6a449af014086dxxxxxx346490aaa0a8739
当然,看手机 UDID 还是挺麻烦的,作为一个懒人,怎么能不用命令行来完成呢?
instruments -s | awk '{print $NR}' | sed -n 3p | awk '{print substr($0,2,length($0)-2)}' | xargs rvictl -s
这样只要连上手机,就可以直接获取到 UDID 了。
![]()
运行命令后会看到成功创建 rvi0 虚拟网卡的提示,双击 rvi0 那一行即可。
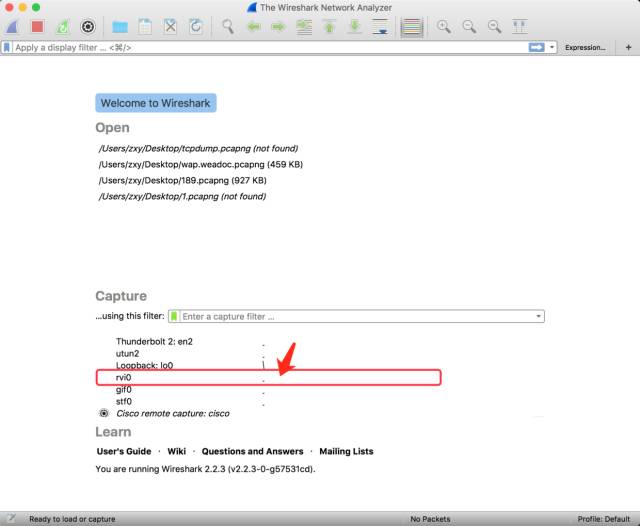
抓包界面
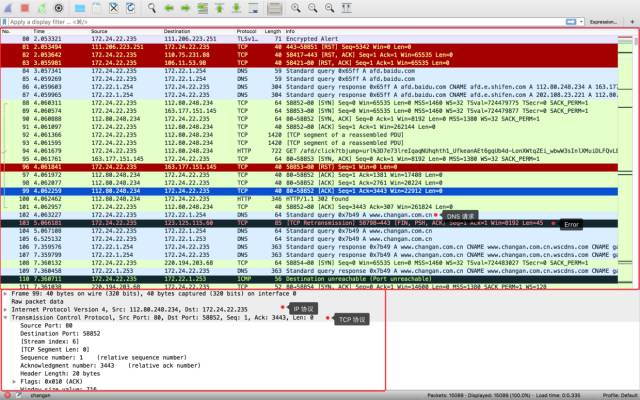
我们主要关注两个内容,上面的大红框里面是数据流,包含了 TCP、DNS、ICMP、HTTP 等协议,颜色花花绿绿,绚丽多彩。一般来说黑色的内容表示遇到错误,需要重点关注,其他内容则辅助理解。反复调试几次以后也就能基本记住各种颜色对应的含义了。
下面的小红框里面主要是某一个包的数据详解,会根据不同的协议层来划分,比如我选中的 99 号包时一个 TCP 包,可以很清楚的看到它的 IP 头部、TCP 头部和 TCP Payload。这些数据必要时可以做更详细的分析,但一般也不用关注。
一般来说一次请求的数据包会非常大,可能会有上千个,如何找到自己感兴趣的请求呢,我们可以使用之前提到的过滤功能。WireShark 的过滤使用了一套自己定义的语法,不熟悉的话需要上网查一查或者借助自动补全功能来“望文生义”。
由于是要查看 HTTP 请求的具体细节,我们先得找到请求的网址,然后利用 ping 命令得到它对应的 IP 地址。这种做法一般没问题,但也不排除有的域名会做一些优化,比如不同的 IP 请求 DNS 解析时返回不同的 IP 地址来保证***速度。也就是说手机上 DNS 解析的结果并不总是和电脑上的解析结果一致。这种情况下我们可以通过查看 DNS 数据包来确定。
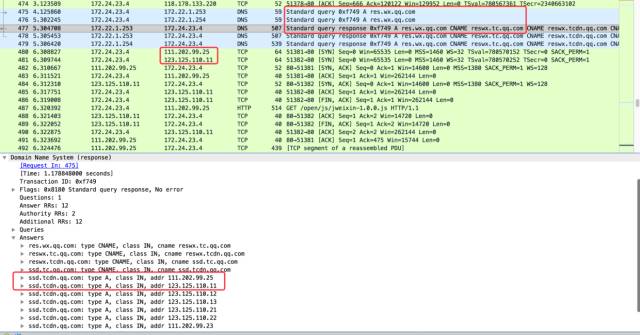
比如从图中可以看到 res.wx.qq.com 这个域名解析出了一大堆 IP 地址,而真正使用的仅有前两个。
解析出地址后,我们就可以做简单的过滤了,输入ip.addr == 220.194.203.68:

这样就只显示和 220.194.203.68 主机之间的通信了。注意红框中的 SourcePort,这是客户端端口。我们知道 HTTP 支持并发请求,不同的并发请求肯定是占用不同的端口。所以在图中看到的上下两个数据包,并非一定是请求与响应的关系,他们可能属于两个不同的端口,彼此之间毫无关系,只是恰好在时间上最接近而已。
如果只想显示某个端口的数据,可以使用:ip.addr == 220.194.203.68 and tcp.dstport == 58854。
如果只想看 HTTP 协议的 GET 请求与响应,可以使用 ip.addr == 220.194.203.68 and (http.request.method == "GET" || http.response.code == 200) 来过滤。
如果想看丢包方面的数据,可以用 ip.addr == 220.194.203.68 and (tcp.analysis.fast_retransmission || tcp.analysis.retransmission)
以上是笔者在调试过程中用到比较多的命令,仅供参考。有兴趣的读者可以自行抓包实验,就不挨个贴图了。
Case1: DNS解析
经过多次抓包后我开始分析那些长时间白屏的网页对应的数据包,果然发现不少问题,比如这里:
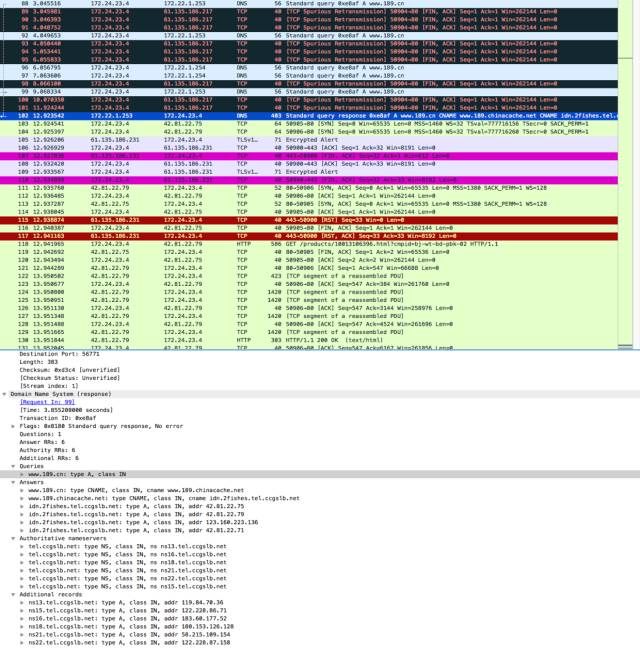
可以很明显的看到在一大串黑色错误信息,但如果你去调试这些数据包,那么就掉进陷阱了。DNS 是基于 UDP 的协议,不会有 TCP 重传,所以这些黑色的数据包必定是之前的丢包重传,不用关心。如果只看蓝色的 DNS 请求,就会发现连续发送了几个请求但都没有响应,直到第 12s 才得到解析后的IP 地址。
从 DNS 请求的接收方的地址以 172.24 开头可以看出,这是内网 DNS 服务器,不知道为什么卡了很久。
Case2: 握手响应延迟
下图是一次典型的 TCP 握手时的场景。同时也可以看到***张图中的 SYN 握手包发出后,过了一秒钟才接受到 ACK。当然了,原因也不清楚,只能解释为网络抖动。
![]()
随后我又在 4G 网络下抓了一次包:

这次事情就更离谱了,第二秒发出的 SYN 握手包反复丢失(也有可能是服务端没有响应、或者是 ACK 丢失),总之客户端不断重传 SYN 包。
更有意思的是,观察 TSval,它表示包发出时的时间戳。我们观察这几个值会发现,前几次的间隔时间是 1s,后来变成了 2s,4s 和 8s。这不禁让我想起了 RTO 的概念。
我们知道 RTT 表示的是网络请求从发起到接收响应的时间,它是一个随着网络环境而动态改变的值。TCP 有窗口的概念,对于窗口的***个数据包,如果它无法发送,窗口就不能向后滑动。客户端以接收到 ACK 作为数据包成功发送的标志,那么如果 ACK 收不到呢?客户端当然不会一直等下去,它会设置一个超时时间,一旦超过这个时间就认为数据包丢失,从而重传。
这个超时时间就被称为 RTO,显然它必须略大于 RTT,否则就会误报数据包丢失。但也不能过大,否则会浪费时间。因此合理的 RTO 必须跟随 RTT 动态调整,始终保证大于 RTT 但也不至于太大。观察上面的截图可以发现,某些情况下 RTT 会非常小,小到只有几毫秒。如果 RTO 也设置为几毫秒就会显得不太合理,这会加大客户端和沿途各路由器的压力。因此 RTO 还会设置下限,不同的操作系统可能有不同的实现,比如 Linux 上是 200ms。同时,RTO 也会设置上限,具体的算法可以参考这篇文章 和这篇文章。
需要注意的是,RTO 随着 RTT 动态变化,但如果达到了 RTO 导致了超时重传,以后的 RTO 就不再随着 RTT 变化了(此时的 RTT 无法计算),会指数增长。也就是上面截图中的间隔时间从 2s 变成 4s 再变成 8s 的原因。
同样的,我们发现了握手花费了 20s 这一现象,但无法给出准确原因,只能解释为网络抖动。
总结
通过 TCP 层面的抓包,我们不仅仅学习了 WireShark 的使用,也复习了 TCP 协议的相关知识,对问题的分析也更加深入。从最初的网络问题开始细化挖掘,得出了白屏时间过长、网页加载太慢的结论,最终又具体的计算出了有多少个 HTTP 请求,DNS 解析、TCP 握手、TCP 数据传输等各个阶段的耗时。由此看来,网页加载慢的罪魁祸首并非广告主网页的质量问题,而是网络的不稳定问题。虽然最终也没有得到有效的解决方案,但至少明确了问题的发生原因,给出了令人信服的解释。













