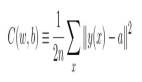神经网络是有史以来发明的最优美的编程范式之⼀。在传统的编程⽅法中,我们告诉计算机做什么,把⼤问题分成许多小的、精确定义的任务,计算机可以很容易地执行。相比之下,在神经网络中,我们不告诉计算机如何解决我们的问题。相反,它从观测数据中学习,找出它自己的解决问题的办法。
从数据中自动学习,听上去很有前途。然而,直到 2006 年,除了用于一些特殊的问题,我们仍然不知道如何训练神经⽹络去超越传统的⽅法。2006 年,被称为 “深度神经网络” 的学习技术的发现引起了变化。这些技术现在被称为 “深度学习”。它们已被进⼀步发展,今天深度神经网络和深度学习在计算机视觉、语音识别、自然语言处理等许多重要问题上都取得了显著的性能。
笔者从一年前接触深度学习,惊叹于AlphaGo所取得的成绩,任何雄心于建模领域的数据管理者,不管你现在是否还在自己建模,或者正领导着一只团队向前走,都有必要去理解一下深度学习到底是什么,如果你还敢说自己是数据方面的专业人士的话,但任何媒体上的关于深度学习的介绍,其深度都是及其有限的,几乎可以说,对一个数据管理者的学识提升没有什么帮助。
即使你已经知道了TensorFlow这类引擎,甚至已经安排开始安装这里引擎,依样画葫芦的去完成一个深度学习的过程,也仅仅是术上的一个追求,如果你想要了解今后⼏年都不会过时的原理,那么只是学习些热⻔的程序库是不够的,你需要领悟让神经⽹络⼯作的原理。技术来来去去,但原理是永恒的。
笔者曾经写过一篇《我如何理解深度学习?》的微信公众号文章,那个是及其简单的一个浅层次理解,对于构建一个真正的深度学习神经网络没有指导作用,因为神经网络本质上属于机器学习的一类,其难点在于如何构建一个可用的多层神经网络,而不是说深度神经网络是个什么东西,那个其实没有啥秘密可言。
牛逼的深度学习专家肯定是网络架构、参数调优的高手,而不是简单的反复说深度学习是啥东西,笔者一直没勇气去深入的理解神经网络最核心的东西-参数,导致我一直游离在这门实践学科之外,这次斗胆看了些书,网上找了些文章,多了点理解,对于神经网络的参数有了一些基本的概念,这些都是打造一个深度学习价值网络的基础。
团队的同事最近自己在研究深度学习,说出来的结果比SVM差很多,我想,肯定是不懂参数和调试的方法吧。
笔者数学并不好,极大降低了学习的效率,我想很多人应该跟我一样,也不可能再有机会去重读一次高等数学,这是一个数学上的残疾人理解的深度学习,我能做的,就是当个知识的搬运工,用最通俗易懂的方式阐述我所理解的东西,让很多看似深奥的东西尽量平民化一点,从“道”的角度去理解一个深度网络,也许,还能有些生活的感悟呢。
由于理解深度学习的前提是理解神经网络,因此,笔者会试着写三篇文章,分别是启蒙篇,参数篇及总结篇,深入浅出的给出我的理解,所有的资料都来自网上电子书《Neural Networks and Deep Learning》,这本书写得实在太好了,我只是剪辑了下,吸出了其中的精髓,希望你坚持看完。
Part 1
感知器
这一节你能理解什么是感知器以及为什么要用S型(逻辑)感知器。
什么是神经网络?一开始,我将解释⼀种被称为“感知器”的人工神经元,感知器是如何⼯作的呢?⼀个感知器接受⼏个⼆进制输⼊,x1; x2;x3,并产⽣⼀个⼆进制输出:
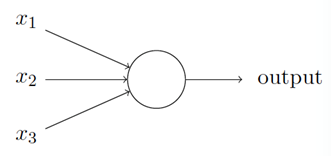
⽰例中的感知器有三个输⼊,x1; x2; x3。通常可以有更多或更少输⼊。Rosenblatt 提议⼀个简单的规则来计算输出。他引⼊权重,w1;w2……,表示相应输⼊对于输出重要性的实数。神经元的输出,0 或者1,则由分配权重后的总和Σj wjxj ⼩于或者⼤于⼀些阈值决定。和权重⼀样,阈值是⼀个实数,⼀个神经元的参数,⽤更精确的代数形式:
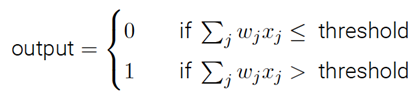
这是基本的数学模型。你可以将感知器看作依据权重来作出决定的设备。让我举个例⼦。这不是⾮常真实的例⼦,但是容易理解,⽽且很快我们会有根多实际的例⼦。假设这个周末就要来了,你听说你所在的城市有个奶酪节,你喜欢奶酪,正试着决定是否去参加。你也许会通过给三个因素设置权重来作出决定:
1. 天气好吗?
2. 你的男朋友或者⼥朋友会不会陪你去?
3. 这个节⽇举办的地点是否靠近交通站点?(你没有⻋)
你可以把这三个因素对应地⽤⼆进制变量x1; x2 和x3 来表⽰。例如,如果天⽓好,我们把x1 = 1,如果不好,x1 = 0。类似地,如果你的男朋友或⼥朋友同去,x2 = 1,否则x2 = 0。x3也类似地表⽰交通情况。
现在,假设你是个嗜好奶酪的吃货,以⾄于即使你的男朋友或⼥朋友不感兴趣,也不管路有多难⾛都乐意去。但是也许你确实厌恶糟糕的天⽓,⽽且如果天⽓太糟你也没法出⻔。你可以使⽤感知器来给这种决策建⽴数学模型。⼀种⽅式是给天⽓权重选择为w1 = 6 ,其它条件为w2 = 2 和w3 = 2。w1 被赋予更⼤的值,表⽰天⽓对你很重要,⽐你的男朋友或⼥朋友陪你,或者最近的交通站重要的多。最后,假设你将感知器的阈值设为5。这样,感知器实现了期望的决策模型,只要天⽓好就输出1,天⽓不好则为0。对于你的男朋友或⼥朋友是否想去,或者附近是否有公共交通站,其输出则没有差别。随着权重和阈值的变化,你可以得到不同的决策模型。例如,假设我们把阈值改为3 。那么感知器会按照天⽓好坏,或者结合交通情况和你男朋友或⼥朋友同⾏的意愿,来得出结果。换句话说,它变成了另⼀个不同的决策模型。降低阈值则表⽰你更愿意去。
这个例⼦说明了⼀个感知器如何能权衡不同的依据来决策,这看上去也可以⼤致解释⼀个感知器⽹络能够做出微妙的决定:
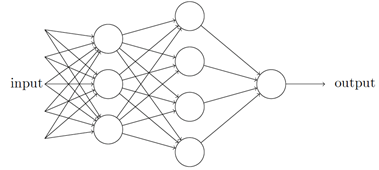
在这个⽹络中,第⼀列感知器—— 我们称其为第⼀层感知器—— 通过权衡输⼊依据做出三个⾮常简单的决定。那第⼆层的感知器呢?每⼀个都在权衡第⼀层的决策结果并做出决定。以这种⽅式,⼀个第⼆层中的感知器可以⽐第⼀层中的做出更复杂和抽象的决策。在第三层中的感知器甚⾄能进⾏更复杂的决策。以这种⽅式,⼀个多层的感知器⽹络可以从事复杂巧妙的决策。
假设我们有⼀个感知器⽹络,想要⽤它来解决⼀些问题。例如,⽹络的输⼊可以是⼀幅⼿写数字的扫描图像。我们想要⽹络能学习权重和偏置,这样⽹络的输出能正确分类这些数字。为了看清学习是怎样⼯作的,假设我们把⽹络中的权重(或者偏置)做些微⼩的改动,就像我们⻢上会看到的,这⼀属性会让学习变得可能,这⾥简要⽰意我们想要的。
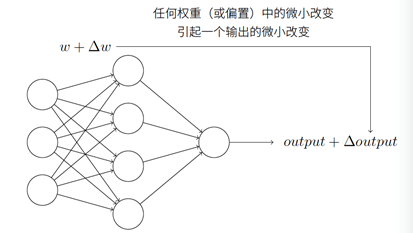
如果对权重(或者偏置)的微⼩的改动真的能够仅仅引起输出的微⼩变化,那我们可以利⽤这⼀事实来修改权重和偏置,让我们的⽹络能够表现得像我们想要的那样。例如,假设⽹络错误地把⼀个“9”的图像分类为“8”。我们能够计算出怎么对权重和偏置做些⼩的改动,这样⽹络能够接近于把图像分类为“9”。然后我们要重复这个⼯作,反复改动权重和偏置来产⽣更好的输出,这时⽹络就在学习。
问题在于当我们的⽹络包含感知器时这不会发⽣,实际上,⽹络中单个感知器上⼀个权重或偏置的微⼩改动有时候会引起那个感知器的输出完全翻转,如0 变到1,那样的翻转可能接下来引起其余⽹络的⾏为以极其复杂的⽅式完全改变。因此,虽然你的“9”可能被正确分类,⽹络在其它图像上的⾏为很可能以⼀些很难控制的⽅式被完全改变,这使得逐步修改权重和偏置来让⽹络接近期望⾏为变得困难,也许有其它聪明的⽅式来解决这个问题。但是这不是显⽽易⻅地能让⼀个感知器⽹络去学习。
我们可以引⼊⼀种称为S 型神经元的新的⼈⼯神经元来克服这个问题,S 型神经元和感知器类似,但是被修改为权重和偏置的微⼩改动只引起输出的微⼩变化。这对于让神经元⽹络学习起来是很关键的。
我们⽤描绘感知器的相同⽅式来描绘S 型神经元:
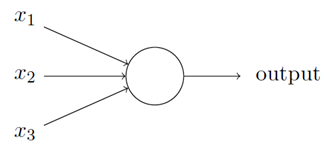
正如⼀个感知器,S 型神经元有多个输⼊,x1; x2; ……。但是这些输⼊可以取0 和1 中的任意值,⽽不仅仅是0 或1。例如,0:638 是⼀个S 型神经元的有效输⼊,同样,S 型神经元对每个输⼊有权重,w1;w2……,和⼀个总的偏置b。但是输出不是0 或1。相反,它现在是σ (w x+b),这⾥σ被称为S 型函数,有时被称为逻辑函数,⽽这种新的神经元类型被称为逻辑神经元,定义为:
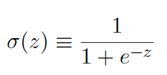
把它们放在⼀起来更清楚地说明,⼀个具有输⼊x1; x2;……,权重w1;w2; …..,和偏置b 的S型神经元的输出是:
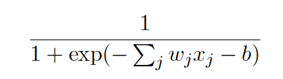
σ(z)图形如下所示:
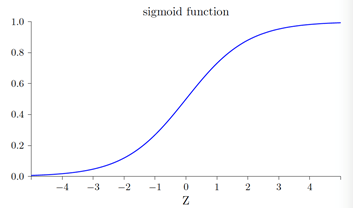
σ的平滑意味着权重和偏置的微⼩变化,即Δwj 和Δb,会从神经元产⽣⼀个微⼩的输出变化Δoutput。实际上,微积分告诉我们Δoutput 可以很好地近似表⽰为:
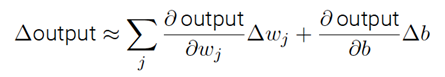
上⾯全部⽤偏导数的表达式看上去很复杂,实际上它的意思⾮常简单(这可是个好消息):Δoutput 是⼀个反映权重和偏置变化即Δwj 和Δb的线性函数。
Part 2
神经网络的架构
这一节告诉你神经网络长什么模样?
下面这个⽹络中最左边的称为输⼊层,其中的神经元称为输⼊神经元,最右边的,即输出层包含有输出神经元,在本例中,输出层只有⼀个神经元,中间层,既然这层中的神经元既不是输⼊也不是输出,则被称为隐藏层。
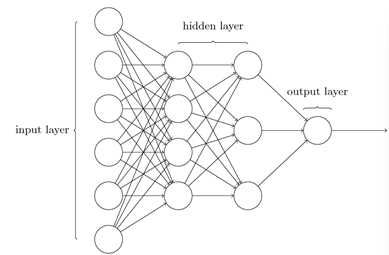
假设我们尝试确定⼀张⼿写数字的图像上是否写的是“9”,很⾃然地,我们可以将图⽚像素的强度进⾏编码作为输⼊神经元来设计⽹络,如果图像是⼀个64 * 64 的灰度图像,那么我们会需要4096 = 64 * 64 个输⼊神经元,每个强度取0 和1 之间合适的值。输出层只需要包含⼀个神经元,当输出值⼩于0.5 时表⽰“输⼊图像不是⼀个9”,⼤于0.5 的值表⽰“输⼊图像是⼀个9”。
定义神经⽹络后,让我们回到⼿写识别上来,我们将使⽤⼀个三层神经⽹络来识别单个数字:
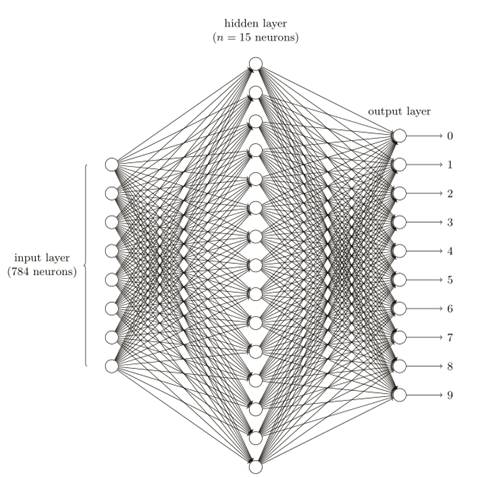
⽹络的输⼊层包含给输⼊像素的值进⾏编码的神经元,我们给⽹络的训练数据会有很多扫描得到的 28×28 的⼿写数字的图像组成,所有输⼊层包含有 784 = 28×28个神经元。为了简化,上图中我已经忽略了 784 中⼤部分的输⼊神经元。输⼊像素是灰度级的,值为 0.0 表⽰⽩⾊,值为 1.0 表⽰⿊⾊,中间数值表⽰逐渐暗淡的灰⾊。
⽹络的第⼆层是⼀个隐藏层,我们⽤ n 来表⽰神经元的数量,⽰例中⽤⼀个⼩的隐藏层来说明,仅仅包含 n = 15 个神经元,⽹络的输出层包含有 10 个神经元。如果第⼀个神经元激活,即输出 ≈ 1,那么表明⽹络认为数字是⼀个 0。如果第⼆个神经元激活,就表明⽹络认为数字是⼀个 1。依此类推。更确切地说,我们把输出神经元的输出赋予编号 0 到 9,并计算出那个神经元有最⾼的激活值。⽐如,如果编号为 6 的神经元激活,那么我们的⽹络会猜到输⼊的数字是 6。
为什么我们⽤ 10 个输出神经元,毕竟我们的任务是能让神经⽹络告诉我们哪个数字(0,1,2,...,9 )能和输⼊图⽚匹配。⼀个看起来更⾃然的⽅式就是使⽤ 4 个输出神经元,这样做难道效率不低吗?最终的判断是基于经验主义的:我们可以实验两种不同的⽹络设计,结果证明对于这个特定的问题⽽⾔,10 个输出神经元的神经⽹络⽐ 4 个的识别效果更好。
为了理解为什么我们这么做,我们需要从根本原理上理解神经⽹络究竟在做些什么。⾸先考虑有 10 个神经元的情况。我们⾸先考虑第⼀个输出神经元,它告诉我们⼀个数字是不是 0,它能那么做是因为可以权衡从隐藏层来的信息。隐藏层的神经元在做什么呢?假设隐藏层的第⼀个神经元只是⽤于检测如下的图像是否存在:

为了达到这个⽬的,它通过对此图像对应部分的像素赋予较⼤权重,对其它部分赋予较⼩的权重,同理,我们可以假设隐藏层的第⼆,第三,第四个神经元是为检测下列图⽚是否存在:

就像你能猜到的,这四幅图像组合在⼀起构成了前⾯显⽰的⼀⾏数字图像中的 0:

如果所有隐藏层的这四个神经元被激活那么我们就可以推断出这个数字是 0,当然,这不是我们推断出 0 的唯⼀⽅式,假设神经⽹络以上述⽅式运⾏,我们可以给出⼀个貌似合理的理由去解释为什么⽤ 10 个输出⽽不是 4 个,如果我们有 4 个输出,那么第⼀个输出神经元将会尽⼒去判断数字的最⾼有效位是什么,把数字的最⾼有效位和数字的形状联系起来并不是⼀个简单的问题,很难想象出有什么恰当的历史原因,⼀个数字的形状要素会和⼀个数字的最⾼有效位有什么紧密联系。
这个启发性的⽅法通常很有效,它会节省你⼤量时间去设计⼀个好的神经⽹络结构,笔者很喜欢这种试图从道的层面解释神经网络的方法,它让我们对于神经网络的认识能更深一点,而不是人云亦云。
Part 3
使⽤梯度下降算法进⾏学习
这一节你能理解神经网络到底要计算什么?为什么要这么计算?
现在我们有了神经⽹络的设计,它怎样可以学习识别数字呢?我们需要的第⼀样东西是⼀个⽤来学习的数据集 —— 称为训练数据集。我们将使⽤ MNIST 数据集,其包含有数以万计的连带着正确分类器的⼿写数字的扫描图像,MNIST 数据分为两个部分。第⼀部分包含 60,000 幅⽤于训练数据的图像。这些图像扫描⾃250 ⼈的⼿写样本,他们中⼀半⼈是美国⼈⼝普查局的员⼯,⼀半⼈是⾼校学⽣,这些图像是28 × 28 ⼤⼩的灰度图像,第⼆部分是 10,000 幅⽤于测试数据的图像,同样是 28 × 28 的灰度图像,我们将⽤这些测试数据来评估我们的神经⽹络学会识别数字有多好。
我们将⽤符号 x 来表⽰⼀个训练输⼊。为了⽅便,把每个训练输⼊ x 看作⼀个 28×28 = 784维的向量,每个向量中的项⽬代表图像中单个像素的灰度值。我们⽤ y = y(x) 表⽰对应的期望输出,这⾥ y 是⼀个 10 维的向量。例如,如果有⼀个特定的画成 6 的训练图像,x,那么y(x) = (0,0,0,0,0,0,1,0,0,0) T 则是⽹络的期望输出。注意这⾥ T 是转置操作,把⼀个⾏向量转换成⼀个列向量。
我们希望有⼀个算法,能让我们找到权重和偏置,以⾄于⽹络的输出 y(x) 能够拟合所有的训练输⼊ x。为了量化我们如何实现这个⽬标,我们定义⼀个代价函数,也叫损失函数或目标函数:
![]()
这⾥ w 表⽰所有的⽹络中权重的集合,b 是所有的偏置,n 是训练输⼊数据的个数,a 是表⽰当输⼊为 x 时输出的向量,求和则是在总的训练输⼊ x 上进⾏的。当然,输出 a 取决于 x, w和 b。
我们把 C 称为⼆次代价函数;有时也称被称为均⽅误差或者 MSE。观察⼆次代价函数的形式我们可以看到 C(w,b) 是⾮负的,因为求和公式中的每⼀项都是⾮负的。此外,代价函数 C(w,b)的值相当⼩,即 C(w,b) ≈ 0,精确地说,是当对于所有的训练输⼊ x,y(x) 接近于输出 a 时,因此如果我们的学习算法能找到合适的权重和偏置,使得 C(w,b) ≈ 0,它就能很好地⼯作,因此我们的训练算法的⽬的,是最⼩化权重和偏置的代价函数 C(w,b),换句话说,我们想要找到⼀系列能让代价尽可能⼩的权重和偏置,我们将采⽤称为梯度下降的算法来达到这个⽬的。
为什么要介绍⼆次代价呢?毕竟我们最初感兴趣的内容不是能正确分类的图像数量吗?为什么不试着直接最⼤化这个数量,⽽是去最⼩化⼀个类似⼆次代价的间接评量呢?这么做是因为在神经⽹络中,被正确分类的图像数量所关于权重和偏置的函数并不是⼀个平滑的函数,⼤多数情况下,对权重和偏置做出的微⼩变动完全不会影响被正确分类的图像的数量,这会导致我们很难去解决如何改变权重和偏置来取得改进的性能,⽽⽤⼀个类似⼆次代价的平滑代价函数则能更好地去解决如何⽤权重和偏置中的微⼩的改变来取得更好的效。
这就是选择MSE的原因,我们又有了一些悟道。
我们训练神经⽹络的⽬的是找到能最⼩化⼆次代价函数 C(w,b) 的权重和偏置,但是现在它有很多让我们分散精⼒的结构 —— 对权重 w 和偏置 b 的解释,晦涩不清的 σ 函数,神经⽹络结构的选择,MNIST 等等,事实证明我们可以忽略结构中⼤部分,把精⼒集中在最⼩化⽅⾯来理解它。
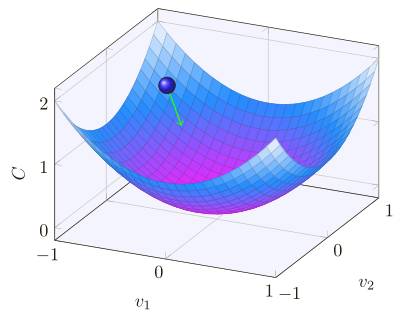
好了,假设我们要最⼩化某些函数,C(v),它可以是任意的多元实值函数,v = v 1 ,v 2 ,...。注意我们⽤ v 代替了 w 和 b 以强调它可能是任意的函数 —— 我们现在先不局限于神经⽹络的环境。为了最⼩化 C(v),想象 C 是⼀个只有两个变量 v1 和 v2 的函数:
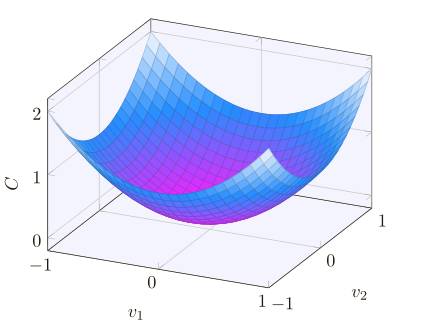
我们想要的是找到 C 的全局最⼩值,当然,对于上图的函数,我们⼀眼就能找到最⼩值,那意味着,也许我展⽰的函数过于简单了!通常函数 C 可能是⼀个复杂的多元函数,看⼀下就能找到最⼩值可是不可能的。
找到最⼩值可是不可能的。⼀种解决这个问题的⽅式是⽤微积分来解析最⼩值。我们可以计算导数去寻找 C 的极值点。运⽓好的话,C 是⼀个只有⼀个或少数⼏个变量的函数,但是变量过多的话那就是噩梦,⽽且神经⽹络中我们经常需要⼤量的变量—最⼤的神经⽹络有依赖数亿权重和偏置的代价函数,极其复杂,⽤微积分来计算最⼩值已经不可⾏了。
微积分是不能⽤了。幸运的是,有⼀个漂亮的推导法暗⽰有⼀种算法能得到很好的效果。⾸先把我们的函数想象成⼀个⼭⾕,只要瞄⼀眼上⾯的绘图就不难理解,我们想象有⼀个⼩球从⼭⾕的斜坡滚落下来。我们的⽇常经验告诉我们这个球最终会滚到⾕底。也许我们可以⽤这⼀想法来找到函数的最⼩值?我们会为⼀个(假想的)球体随机选择⼀个起始位置,然后模拟球体滚落到⾕底的运动。我们可以通过计算 C 的导数(或者⼆阶导数)来简单模拟——这些导数会告诉我们⼭⾕中局部“形状”的⼀切,由此知道我们的球将怎样滚动。
注意,知道我们的球将怎样滚动这是核心。
为了更精确地描述这个问题,让我们思考⼀下,当我们在 v1 和 v2 ⽅向分别将球体移动⼀个很⼩的量,即 ∆v1 和 ∆v2 时,球体将会发⽣什么情况,微积分告诉我们 C 将会有如下变化:
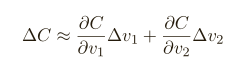
我们要寻找⼀种选择 ∆v 1 和 ∆v 2 的⽅法使得 ∆C 为负;即,我们选择它们是为了让球体滚落,为了弄明⽩如何选择,需要定义 ∆v 为 v 变化的向量,∆v ≡ (∆v1 ,∆v2 ) T ,T 是转置符号,我们也定义 C 的梯度为偏导数的向量,⽤ ∇C 来表⽰梯度向量,即:
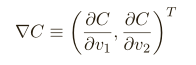
有了这些定义,∆C 的表达式可以被重写为:
![]()
这个表达式解释了为什么 ∇C 被称为梯度向量:∇C 把 v 的变化关联为 C 的变化,正如我们期望的⽤梯度来表⽰,但是这个⽅程真正让我们兴奋的是它让我们看到了如何选取 ∆v 才能让∆C 为负数,假设我们选取:
![]()
这⾥的η 是个很⼩的正数(称为学习速率,注意以后会经常见到它),我们看到
![]()
这样保证了∆C ≤ 0,即如果我们按照∆v方程这个规则去改变 v,那么 C 会⼀直减⼩,不会增加,这正是我们想要的特性,因此我们把∆v方程⽤于定义球体在梯度下降算法下的“运动定律”,也就是说我们⽤∆v方程计算∆v,来移动球体的位置 v:
![]()
然后我们⽤它再次更新规则来计算下⼀次移动。如果我们反复持续这样做,我们将持续减⼩C 直到—— 正如我们希望的 —— 获得⼀个全局的最⼩值。
总结⼀下,梯度下降算法⼯作的⽅式就是重复计算梯度 ∇C,然后沿着相反的⽅向移动,沿着⼭⾕“滚落”。我们可以想象它像这样:
你可以把这个更新规则看做定义梯度下降算法。这给我们提供了⼀种⽅式去通过重复改变 v来找到函数 C 的最⼩值。这个规则并不总是有效的 —— 有⼏件事能导致错误,让我们⽆法从梯度下降来求得函数 C 的全局最⼩值,这个观点我们会在后⾯的去探讨。但在实践中,梯度下降算法通常⼯作地⾮常好,在神经⽹络中这是⼀种⾮常有效的⽅式去求代价函数的最⼩值,进⽽促进⽹络⾃⾝的学习。