定义:ABtest本身其实是物理学的“控制变量法”,通过只改变一个因素来确定其变化对cr或者收益的影响。其本身具备统计意义,而且具备实际意义。试想一下如果没有ABtest,那新项目上线后的收益如何排除季节因素、市场环境因素的影响,而且一个页面上如果同时做多处改动,如何评判是哪个改动造成的收益或损失?这对一个理性思维的人是不可接受的。
简单理解为将一群人分成两类,通过展示新旧版version A/B来测试哪种版本效果好,差异是多少。

ABtest流程
- ABtest数据流:APP启动时,公共框架会拉取所有线上abtest的试验号和对应版本(所有BU)存入本地,当用户进入机票频道时候,在特定场景触发本地实验号调用。比如往返实验,在用户首页点击往返搜索时,开发会从本地文件中查询160519_fld_round试验号该用户的对应版本,确定跳转新/旧版页面。在试验号接收到调用时,同时触发一个abtest的trace埋点o_abtest_expresult,该埋点会记录clientcode,sid,pvid,试验号及版本信息,最终经过ETL,BI会汇总一张AB实验表,将上述信息汇总,便于后续做关联计算。
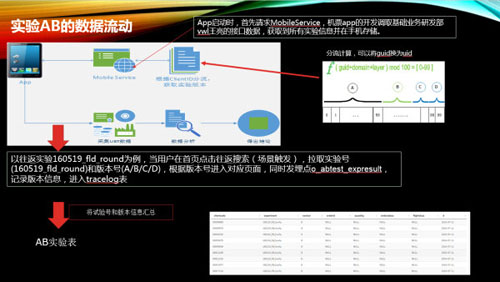
- 分流计算:每个设备在刚启动的时候会根据设备号+试验号+随机数组成一串N位数,对100取模的余数从0-99,假设ABCD四个版本流量 10:70:10:10的情况下,则余数0-9为A版、10-79为B版、80-89为C版、90-99为D版。A版为默认版,如果尾数异常(Null或溢出),则走A版。
- 版本说明:如果仅有新旧两个版本的情况下,一般会设置ABCD四个版本,其中ACD为旧版,B为新版。(如果有多个迭代新版,则从EFG开始)。
AA测试:CD版同为旧版,且流量各为B版一半,在流量随机分配的情况,通过对比CD版的数据表现来验证旧版的状态是稳定的。
AB测试:在确保CD数据相对稳定的前提下,再对比B和ACD版本的数据,来对比新旧版的差异。
兜底版本A:BCD的剩余流量走A版,版本异常的情况下走A版
- 实验正交性:
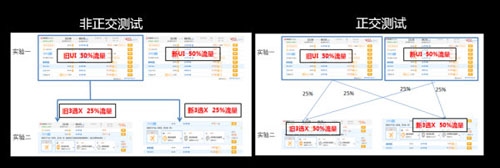
- 非正交实验,如左图展示,在旧版的基础上再做区分,会因为样本数量的问题而限制同时进行的实验个数,而且无法评估两个新版同时存在的影响。
- 正交试验:右图展示,不同实验流量完全打散随机分配,上一个实验与下一个实验理论上流量上没有关联,这样可以在一个页面同时进行多项实验。
这里再提一个Magic Number = 7,虽然理论上单页面上同时进行的正交试验数量没有上线,但是经过长期经验积累,单页面同时线上实验不要超过7,否则会造成难以捉摸的幺蛾子异常。
- 埋点下线机制:
像ABtest里面的埋点触发场景埋点还是由开发控制的,也还是会存在埋点不准确的情况,比如说往返的实验,触发场景是在首页点击往返搜索,理论上去程列表页的UV应该是参与式样的样本数抑制。实际情况是,去程列表页30W的UV,但ABT的报表显示每天样本为50W,经过sql验算两者交集为20W,就说明有10W人是在往返流程但并没有参与实验(数据经过脱敏处理,但不改变相对位置)。
所以基于这样的幺蛾子,在ABT结束后,既要删除代码,又要实验流量全开100%
- 流量调整100%目的:将历史版本的客户端旧版规避,需要操作100%流量。
- 下线代码:保证appのsize不会过度冗余,同时因埋点场景的问题,有些时候虽然流量全切100%,但仍有部分流量走旧版(非常诡异),所以将客户端代码下掉是非常必要。
其他说明:
- 在任何情况下,分析的基础条件就是流量随机分配,如果质疑这件事情,则整个abtest就失去意义.
- 实验分流一般采用设备号clientcode,但是也可以根据uid来,但情况较少
- 对于实验的显著性指标P值一般使用较少且不易理解,就不做过多解释(一年也没怎么用这个指标)
- 分流调节机制,新版流量不要忽上忽下,特别是涉及到核心页面的时候,否则可能会造成用户看到的页面反复变化,增加适应时间和学习成本以及影响用户体验。
分析数据
ABT的目的:
abtest是希望通过如何改进新版优于旧版,而不是通过abtest证明新版弱于旧版而下线实验,所以需要有效地分析数据。
如何看图表:
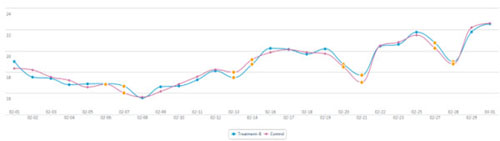
图表反映时间趋势,在abtest中表现为新旧版本两条折线图,且一般会出现交叉的情况,那我们就需要判断这些交叉是有随机性波动还是实验的效果,我在实践中总结简单易用的一条原则是:“抓大放小”。
- 抓大放小(个别表现不影响整体趋势):当你遮住有限个点的时候,不影响整体的差异。比如下图,当你遮住2-11和2-13两天的数据时,会发现蓝色B版优于红色旧版。(当然遮住点的数量因人而异,一般不超过总量10%)
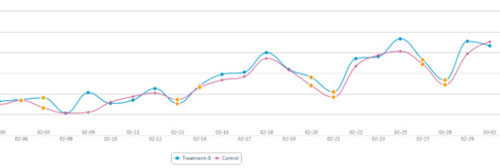
这张图就很难用抓大放小的方式来判断差异,无法证明是新版好还是旧版好,这时候需要分解这个指标来继续分析。
机票的核心指标是转化率CR(conversion rate)和收益(revenue),通常他们之间的关系如下图所示。
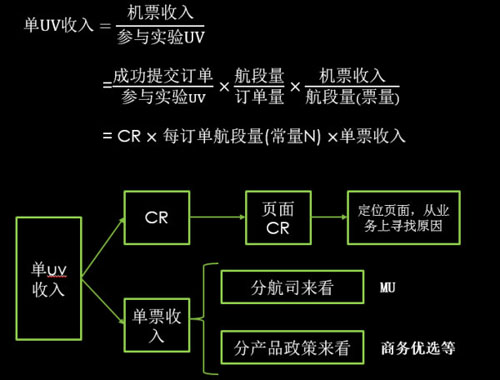
携程机票前台以scrum Team的形式迭代,每个team对于需求的评审是以roi(投入产出比,return on investment)来决定项目的优先级,而return可能是cr的提升,也可能是单票收入的提升。
对于上线实验数据跟踪,也是以当初roi的预期来进行判断实验效果,尤其在没有达到预期的情况下,寻求解决方案。(这其中还有诸多限制条件,比如收益类项目,如果CR有明显下降需要重点关注。)
分析思路
这个分解公示也代表分析的思路,无论对于收益类项目还是CR类项目,都会先看单UV收入和CR(一般情况下,abtest不会改变每个订单的票量,这是基于整体订单估算的平均值,我们暂且认为TA是常量),当这两项都保持正向增长的情况下,那可以直接开大流量继续验证直至项目完美收官(这种案例比较少)。更多的情况是,对于重大项目,即使结果是积极正向的实验,我们也会大概了解下改进点发生在哪个页面或者哪个产品,做到心中有数;
而当发生问题的时候,我们都会对CR和单票收入做分解:
- CR下降的情况,看主流程每个页面的CR,是哪个页面下降,从页面的来源去向和点击来看,是否有明显的异常,一般来讲,对业务足够熟悉的PM在这一步可以结合业务和这些数据大概会有一些预判,是哪些因素可能造成的影响,之后再请教bi专业人员或者自己拉sql来验证数据,从而进行改进。
- 利润下降的原因,继续分解指标,可以分产品、航司、利润构成等指标来分解,找到新旧版的gap,然后结合业务场景做一些预判,进行找数据来支持这个想法,继续迭代新版。
之前的状态是PM对于AB实验的数据有一大坨报表,但是并不知道如何使用,也不知道怎么看报表,不知道怎么分解指标,但其实对于整体进行了解之后,具备简单的分析能力,关键是有业务背景知识的情况下,这样的几个公式的八股文的分析可以解决80%的问题,对于实在无法定位的问题,可以找bi寻求帮助。
总结
ABtest其实核心在于如何定位问题解决问题,但是限于身份不能通过数据来进行举例说明。但其实分析思路应该是一致,比如机票场景下指标分解的核心公式来解决80%的问题,在每个行业应该都会有这样的公式,可以根据特定业务背景自己总结运用。
PM如能够掌握这些基本的指标分析、能够看懂图表、这里面就能够自助解决80%的问题,这样的abtest效率其实已经是非常高的。
【本文为51CTO专栏作者“李宁”的原创稿件,转载请通过51CTO联系作者获取授权】