在微信群里又聊到.NET可以救中国但是案例太少不深的问题,我说.NET玩爬虫简直就是宇宙第一,于是大神朱永光说,你为何不来写一篇总结一下?
那么今天就全面的来总结一下,在.NET生态下,如何玩爬虫。
关于爬虫
从搜索引擎开始,爬虫应该就出现了,爬的对象当然也就是网页URL,在很长一段时间内,爬虫所做的事情就是分析URL、下载WebServer返回的HTML、分析HTML内容、构建HTTP请求的模拟、在爬虫过程中存储有用的信息等等,而伴随着App的发展以及CS系统通讯方式的HTTP化,对服务接口特别是HTTP RESTFul接口的爬虫也开始流行。
爬虫的具体形式,包括模拟浏览器行为和模拟HTTP行为。在爬虫的发展过程中,也涌现出无数的工具和语言实践,而今天要说的就是,.NET生态是爬虫最好的伴侣,但是不要误会,我不是针对python,也不是针对nodejs,我是说除了.NET之外,所有玩爬虫的都是垃圾。
一、先谈一谈对于爬虫的理解
很多人在研究爬虫的初期,热衷于进行浏览器行为的模拟,包括使用一些语言中的WebBrowser控件或者类似PhantomJS这样的无头浏览器,来模拟真实Web行为,进行Dom元素的填写、按钮点击、滚动条操作等等。
虽然这样的做法更接近真实场景,但由于浏览器事件的复杂性,在批量高速的处理场景中,这样的做法稳定程度会大打折扣,我个人非常不赞同这样的理念。
我认为只有从本质上对Web行为进行HTTP的分析,才是关键,任何复杂的浏览器行为,最终都可以准确的拆分为JS逻辑和HTTP行为,所以想要掌握好爬虫技术,对HTTP的理解和分析至关重要。
二、那么第一个神器就登场了,Fiddler
(http://www.telerik.com/fiddler)
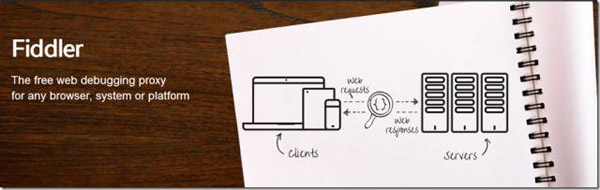
虽然不是最早一批诞生的嗅探器,但Fiddler得益于.NET框架的强大并且融合了一个基于JScript .NET的子系统,敏捷而全面嗅探的功能快速的获得了市场的认可,积累了大量用户,而在被.NET控件开发公司Telerik收购后,发展迅猛,更推出了脱离UI的跨平台库FiddlerCore,可以将嗅探行为融入到大型搜索网络和爬虫系统或者是外挂应用中。
Fiidler是.NET红利的下的优良产物,而一个好的爬虫开发工程师,首要学习目标就是对HTTP的嗅探分析,这时候Fiddler就必不可少了。在这里列举Fiddler几个常见的用法
1)HTTP行为捕捉。这是基本功能,打开Fiddler后,浏览器或者一般进程有任何通讯发生,都会记录下具体的HTTP请求和响应。并且根据Content-Type自动显示为具体的内容,当然了,我推荐直接分析RAW信息,直观明了也能更深刻的理解HTTP。本功能常用功能场景有,分析网页行为、分析应用程序行为、手工获取登陆Cookies等。
2)HTTPS支持。Fiddler在添加一个本地证书后,可以完整的支持对HTTPS链接的抓取。
3)手机应用抓包。现在很多手机应用都使用了RESTFul的后端接口,但在手机上抓取的难度和代价都较大,替代的解决方案是,在Fiddler里面,开启一个HTTP代理服务器,并设置端口,当手机的WIFI网络和Fiddler客户端网络在同一局域网网段时,设置手机的WIFI网络的代理地址为Fiddler的HTTP代理服务器地址,这样手机上任何App的HTTP通讯,都会被Fiddler抓取到。本功能常用功能场景有,手机App抓包、远程代理测试等。而这一用法也常常和安卓模拟器进行配合,可以在PC上完成全部手机应用的通讯行为的分析。
4)HTTP模拟器。Fiddler内置一个请求构造器(Composer),可以手工构建任何HTTP行为,本功能常用场景有,手工抓取与爬虫测试。
5)HTTP劫持。Fiddler可以拦截HTTP请求,并响应修改后的数据,这一用法常见于外挂软件的研发过程,在应用时,则多是FiddlerCore库在外挂系统中的使用。这里不得不补充一句,在这之前,最流行的是winpcap库(或者winpcap库的.NET封装Pcap.Net(https://github.com/PcapDotNet/Pcap.Net)、sharppcap(https://github.com/chmorgan/sharppcap)等),虽然winpcap的工作原理使得其应用范围更广,但FiddlerCore无疑已经成为了当前应用端最炙手可热的领域库。
三、接下来再说一下.NET对HTTP的操控能力

爬虫的主要逻辑部分,即是通过程序对HTTP进行操控,包括对目标URL的下载、对模拟HTTP请求的构造。有趣的是,即使只用System.Net下,WebClinet和HttpWebRequest这两个类,就已经能够满足99%的爬虫场景。下面列举一些常用的场景
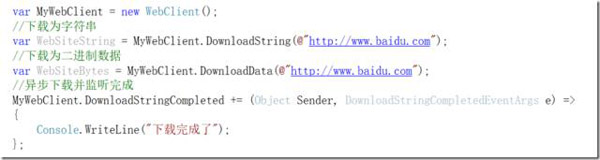
1)URL快速下载(上传)。使用WebClinet对URL进行浏览并下载,可以说代码清晰、支持丰富。包括编码格式、下载格式、异步下载、Form上传、参数拼接等等各种。
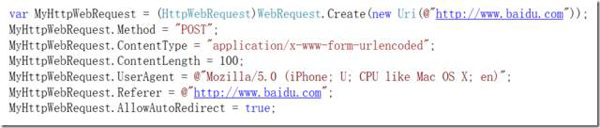
2)HTTP请求构造。在很多场景中,需要伪造Referer、UserAgent、ContentType等等,从一个语言的HTTP库对HTTP协议的支持细腻程度可以看出其是否亲爬虫,幸运的是,HttpWebRequest确实足够全面,能够满足所有的自定义需求。
3)Cookies处理。虽然Cookies已经逐渐淡出历史的舞台,但依然有大量的Web开发框架是以Cookie为支撑做Session体系的,所以Cookie的灵活操作也非常重要。

4)代理服务。有时候目标服务器会对IP访问做限制,这时候使用代理服务器以及不停的更换代理服务器就非常重要了,如下处理也很简洁

不过,也承认一下缺陷,Socks4或者Socks5代理也是会偶尔出现在爬虫处理中,而HttpWebRequest并不直接支持,而我之前用到过一个非常好的网络处理库(收费的,还有EMail处理等各种),有完整的Socks5支持,但是好多年了,记不得名字了,有知道的同学可以告诉我,我补充到这篇文章里。
当然了,得益于.NET语言的强大,除了WebClinet和HttpWebRequest这两个老古董外,还有不少好东西,比如
1)HttpClient。这是.NET4.5框架里带来的新东西,相比HttpWebRequest,HttpClient更像是一个无头浏览器,对异步的支持也更加完备,处理逻辑也更加合理,建议一直用HttpWebRequest做爬虫的同学可以迁移到HttpClient来。
2)其他基于.NET的第三方HTTP库或者知名HTTP的.NET实现。例如RestSharp,EasyHttp,Indy.Sockets等等,这些库对HTTP进行更加便捷方便的封装,有兴趣的同学也可以试一试,当然了,在这里我也提一个建议,不要沉迷于对HTTP请求便捷的封装,.NET也不例外,这会让你远离HTTP的本质,对爬虫能力的提升并无帮助。
四、内容处理也是.NET的强项
在做内容型爬虫时,会出现很多对下载后的内容进行处理的场景,主要也就是对文本的处理,这里又一次体现了.NET的优势,包括
1)String类及周边类。我们来看一张图
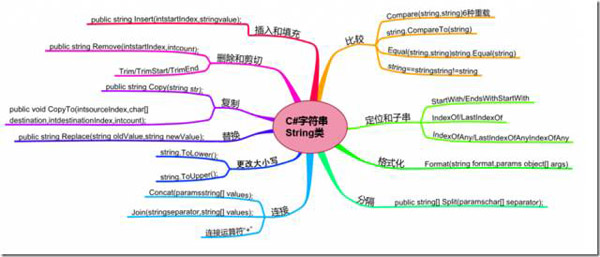
这里基本上涵盖了对字符串的所有处理方法,结构清晰、使用方便。除此之外,还有很多周边类,诸如Char、StringBuilder、Encoding等等,用过的都知道好!
2)正则处理。老实说,正则的学习成本往往会高于使用成本,有时候简单的场景用一些基本的算法和字符串处理比正则要方便的多,但作为顶级爬虫玩家,正则处理是一门必须掌握的技能,而一旦你深入而且熟练的掌握了正则处理方法,那么对字符串的查找、重复数据的处理的效率将会迈上新的台阶。.NET下正则的处理在System.Text.RegularExpressions命名空间里。
3)Javascript模拟。正如前面所说,所有复杂的浏览器行为,最终都可以准确的拆分为JS逻辑和HTTP行为,很多复杂逻辑或者加密的页面,直接下载到的数据还需要经过一些JS处理,才能够变成有用的数据,这个时候Microsoft.JScript命名空间的作用就凸显了,可以快速方便的模拟一些Javascript的内置方法,特别是时间类、数学类、加密类的一些古怪方法,避免走弯路。
4)序列化与反序列化(JSON、XML处理)。很多新应用的通讯格式多为XML或者JSON,对于此类内容的处理,会涉及到很多JSON、XML序列化反序列化,其中也以JSON序列化居。
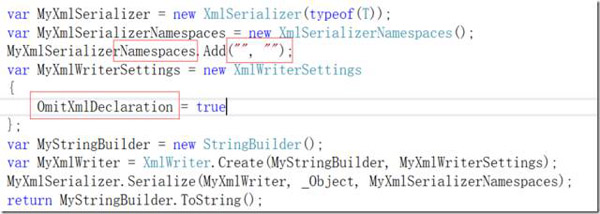
首先是XML的处理,.NET中有System.Xml.Serialization命名空间或者System.Runtime.Serialization.DataContractSerializer等。而对XML处理的关键,在于能够灵活的自定义符合XML标准的内容,例如如下代码:
然后是JSON的处理,虽然JSON标准并没有XML那么复杂,但想要灵活处理,也需要好的框架和工具支撑,在.NET里面,有下面几个好东西推荐
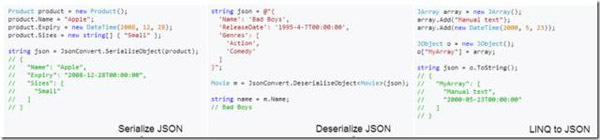
第一个推荐的是Json.NET,这是一个非常流行的JSON处理工具,具体用法不细说,贴几个官方的介绍代码
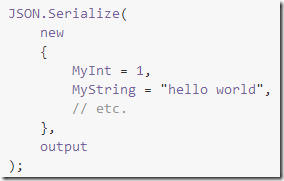
第二个推荐的是Jil,这是一个速度更快、更加敏捷且细粒度更高的JSON处理库,与.NET动态语言特性配合,能够写出如下优雅且实用的代码

总之一句话,这样科班而正统的序列化处理体系,不仅能力强大,更让人心情舒畅!
五、.NET下,敏捷地存储数据会是一个好帮手
爬到的数据不可能总是在内存里操作,大部分时候,也需要存为临时文件或者数据库数据。而.NET在这里的优势依然非常明显。
1)保存到文本文件。.NET提供了很多类,可以方便的操作文本文件,例如下面这样的超敏捷文本文件操作。

除此之外,还有FileStream、StreamReader等强大的文件操作类可供使用。
2)保存到数据库。爬虫程序对目标进行一系列处理后,有用的数据会存入数据库,如果说在.NET下对SQL Server、MySQL、Oracle、SQLite等数据库的全面支持是一辆性能十足的跑车,那Linq语法糖加上两个ORM框架(Linq To SQL、ADO.NET Entity Framework)则是给这个跑车加了个涡轮增压。可以让我们用最敏捷漂亮的方式,将爬虫数据存入到数据库中,简洁到窒息

如果有大批量数据快速插入需求,同样也有Z.EntityFramework.Extensions这样的第三方扩展组件可供使用。
凡此种种,只为让数据处理不要成为爬虫研发的累赘和束缚
六、.NET生态数不胜数的优秀特性让爬虫开发变得优雅
除了以上这些和爬虫直接相关的内容,.NET还有无数的优秀的特性,可以让爬虫开发如虎添翼,我列举几个
1)WinForm开发。.NET的WinForm开发,应该是自Delphi后,效率最高的桌面UI开发方式了,虽然和爬虫没太大关系,但是如果能够熟练用好WinForm,完全可以替代控制台应用,来进行爬虫研发,提高研发效率,谁都别装逼(特别是Linuxer、Macer等),毕竟,复杂可视化比控制台样方便多了。
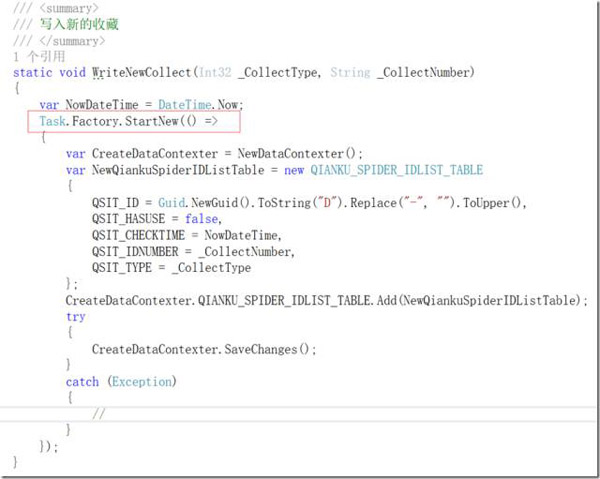
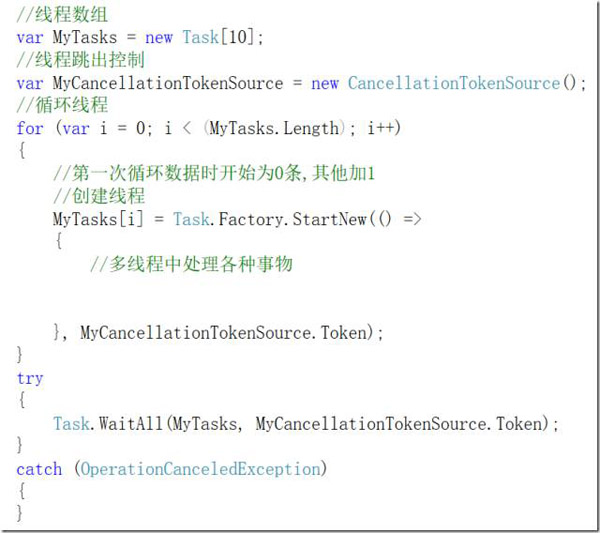
2)多线程处理。即使是在.NET 2.0时期,委托相关机制,便已革新了Win32的多线程API使用方式,而进入到Task并行库时代后,更是优美到飞起,例如下面这两种常见的多线程处理方式
同步语句,异步处理
线程并发,灵活跳出
我想,事已至此,其他所有的语言(.NET体系除外),都是望尘莫及吧。
4)定时处理。定时处理在很多爬虫场景里面都会用到,这里也简单提一下,在.NET里处理定时可以采用两种方式,1、是编写WIndows Service服务来进行定时任务的控制,2、是用定时云服务(阿里云监控、腾讯云拨测等)唤醒一个IIS托管的ASP.NET Web Application。特别是第二种方式,思路新颖,经我实践也非常稳定可靠,有兴趣的同学可以试一试。
5)其他优秀特质。.NET架构和.NET体系语言因Anders Hejlsberg的伟大而伟大,数不胜数的优秀语言特质,在任何一个聪明的开发人员面前,都是宝藏,诸如泛型、扩展方法、动态语言特性、Lamada表达式、反射等等,到底对爬虫的开发有何帮助,只待大家去慢慢体验和挖掘咯
七、规模化、系统化的爬虫,.NET下的软件工程
当出现庞大目标、复杂策略的时候,客观上下载器就要升级为下载系统、多线程处理扩充了队列处理、定时程序就也演变为任务体系,这个时候,爬虫程序就升级成了规模化的爬虫系统,变成了一个软件工程的问题,正如上面所说,.NET很强,但实践太少,能够深刻理解.NET人也很少。
.NET处理爬虫很强,可问题是,.NET处理哪个领域不强?都非常强!.NET的软件工程,还有待各位不断的去探索,去发扬!
八、最后再补充一个附加题,就是超高速IPV4的代理IP扫描
这是我之前很深入研究过的一个课题,虽然和爬虫没有直接的关系,但结果(高匿名HTTP代理)和爬虫也有着密不可分的联系,况且处理过程也非常值得借鉴,所以分享出来
1)先说一下结果。借助.NET体系来处理代理IP的扫描,效率极高,产量惊人,实测单节点(100M电信家庭光纤接入)每天可以产生5万个有效的代理IP。下面说一下几个关键点
2)IP段资源和资源处理。优质的IP段(特别是机房IP段)以及IP段划分,都是重要的资源,3个关键操作包括, 对纯真等IP地址库存入数据库进行查询、将IP段以一定的模型存入数据库进行查询、建立分布式的IP段处理队列机制。
3)SYN高速扫描(S扫描器方式)。超高速IPV4的代理IP扫描的核心技术,就是利用TCP/IP漏洞的SYN半连接扫描,有一个使用C写的s.exe扫描器是最常见的用法,基于命令行执行模式,而在.NET中,则可以用System.Diagnostics下面的Process类进行完整的控制和处理,这又一次体现了.NET的价值。本方式下也有个缺陷,就是仅限Windows Server 2003以下操作系统使用。
4)SYN高速扫描(.NET封装SYN方式)。正如上文所说,.NET对于winacap有很多成熟的封装,可以做到在Windows 10操作系统下的SYN高速扫描,并控制扫描更加稳定(S扫描器高速但并不稳定),用于桌面级分布式代理IP扫描是绝佳配备。
5)代理IP验证。扫描到开放端口的IP地址后,只有验证成功了才能被我们所用,而往往成功率都在万分之一以下,所以验证的过程又是一个关键所在,幸好我们有.NET下的优秀的多线程处理,使得这一验证程序非常简洁和易重构。
如果对此话题有兴趣的同学,可以联系我寻求进一步的帮助,今天篇幅有限,只是简单略过
九、今天要说的差不多就结束了,下面是总结
总结1
今天讨论的东西不是爬虫而是.NET如何玩爬虫。也并不是在说.NET某个具体功能如何绝顶厉害,而是在说在.NET生态下的很多出色功能结合到一起后,就变成了一个非常美好亲爬虫的体系。
所以无论是从生态能力出发还是基于学习实践成本的考虑,做爬虫程序或是大规模爬虫系统,.NET一定是首选!
总结2
我试图告诉一些用其他语言正在研究爬虫的人们,你们走了一条邪路,以python比较有名的爬虫框架scrapy为例,这又是一群想建造轮子的忙碌不休的但却又智商不高的程序员所折腾出怪胎,试图统一爬虫的过程,构建模块化流程化的插件机制,但事实上,这种东西用的越多,越远离了爬虫的本质,越不能适应复杂的爬虫场景。
爬虫的本质是对目标WebServer页面行为和业务流程的精准分析,是对HTTP的深刻理解,是对正则、多线程等周边技术以及软件工程的灵活运用,爬虫场景稍微复杂变化一下,scrapy这样的爬虫就成了鸡肋,运用scrapy这样的工具,对程序员在爬虫领域的学习成长来说,不仅没有明显帮助,更显反智,我有遇到过相当多做爬虫的同学,连HTTP Header里面有些什么都说不出来说不清楚,却玩爬虫工具6的飞起,这无疑是可悲的。
切记先学会走路,再去跑步,而当你深刻的理解了爬虫的本质后,你就会发现,并没有所谓的爬虫语言或者爬虫框架,只有高效的语言和工具,而这时:
.NET生态就恰到好处的映入你眼前,让你流连忘返!