













我已经在学术界和工业界进行了许多年的机器学习建模工作,在看了一系列讨论“大数据”实用性问题的优秀视频 Scalable ML 后,我开始思考总结一些在学习机器学习时,我希望能够尽早明白的事情。视频来源于 Mikio Braun,介绍了 Scala 和 Spark 相关的知识。
我希望在学习机器学习时能够尽早明白的事情有三项:
将模型应用到产品中并不是一件简单的小事;
在课本中我们很难学习到真正的特征选择和特征提取技巧;
模型评估阶段非常重要。
下面让我一个一个地介绍它们。
1. 将模型应用到产品中并不是一件简单的小事
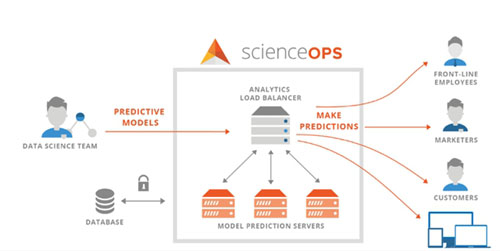
我在 Data-Product 上有一场介绍如何将常微分方程应用到产品中的演讲。之后我花了好一段时间才意识到,自己一个人来处理包括模型衰退、产品中模型评价、开发与运维沟通等事务是多么的困难。Yhat 的 ScienceOps 是针对这个问题的一个解决方案。一开始我并没有意识到它有多棒,现在我发现我很难在市场中找到该产品的直接竞争者,我真的觉得他们正在解决这个非常重要的问题。渐渐地,我意识到我没有聪明到可以处理运维成员负责的事务——所以我很乐意将这项工作外包。
2. 在课本中我们很难学习到真正的特征选择和特征提取技巧
特征选择和提取方法和技巧常常无法从课本中学习。这些技巧只能从像 Kaggle 竞赛或现实世界中的项目中学习,甚至有时候需要实际应用这些技巧和方法才能学会它们。而这些工作在整个数据科学项目流程中占据了相当一部分比重。
3. 模型评估阶段非常重要
除非你已经将模型应用到测试集数据上了,否则你都不能说已经进入到预测分析阶段。像交叉验证、评估指标等评估技巧都是非常宝贵的,因为它们只需将你的数据分离成测试集和训练集。但是实际生活通常并不会将已经定义好测试集、训练集的数据给你,所以将真实世界中的数据划分为测试数据和训练数据,是一项充满创造性的工作,其中可能包含许多情感因素。在 Dato 上有许多讨论模型评估的优秀文章。
我认为 Mikio Braun 对训练集和测试集的解释值得一读。我也很喜欢他画的图并将其包含在文中,方便不熟悉训练集和测试集概念的读者理解。
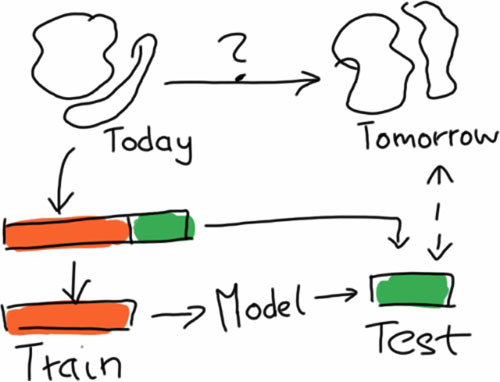
我们在论文、会议甚至在讨论我们解决问题时所用的方法的时候,经常忽略了模型评价。“我们在其中使用了 SVM ”这句话并没有告诉我任何信息,这没有告诉我你的数据来源,你选择的特征,你的模型评估方法,你如何将其应用到产品中,以及你在其中如何使用交叉验证或模型查错。我认为我们需要更多关于机器学习中这些“肮脏”的方面问题的讨论。
我的朋友 Ian 在 Data Science Delivered 上有一个很好的笔记,适合需要为真实情况建立机器学习模型的任何层次的人员阅读。同时也适合希望雇佣数据科学家的招聘人员或者与数据科学团队打交道的经理阅读——如果你正在找人询问“你是如何处理这些肮脏的数据的”。
















