机器学习已经被广泛应用,教程、文章、开源代码到处都是,有些时候只需要你对机器学习算法稍有了解就可以在实际中很好的应用。
但是机器学习还是非常难:
- 推动机器学习研究进步的科学本身很困难,需要创新、实验和坚持;
- 把已知的机器学习模型应用到实际工作中也是一件困难的事情;
- 市场上的机器学习工程师比普通的软件工程师也要昂贵一些。
困难并不是来自于数学,因为机器学习的相关实现并不要求很高的数学基础。困难来自于:
1.选择什么样的机器学习工具
这要求对每个算法和模型的优劣势都了如指掌,这个技能可以通过学过这些模型(课程、教程、Paper等)来获得。当然这类知识构建的困难是计算机所有领域都存在的,不仅仅是机器学习。
2.机器学习很难调试
这种困难表现在两方面:
1)算法不work;
2)算法work,但并未足够好。
机器学习独有的特征是:查找上面问题的原因是“指数”难度的。通常,机器学习算法的Debug都需要很长的时间,很多bug用小数据量很难重现,而且往往在迭代的后期才能出现。很少有算法可以一次成功,所以更多的时间花在调模型上。
指数级困难的调试
在标准的软件工程范畴中,当一个解决方案不如期望时,通常考虑两个方面的出错:算法和实现。
用以下简单的递归算法为例:
- def recursion(input):
- if input is endCase:
- return transform(input)
- else:
- return recursion(transform(input))
当算法不如预期好时,我们可以枚举所有失败的case,这个例子中的网格搜索(Grid Search)如下图所示:
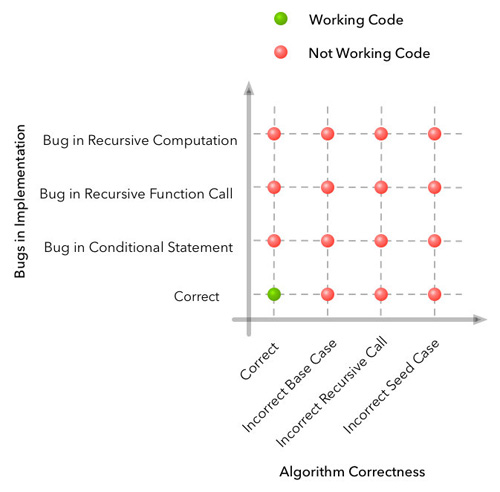
横轴是一些算法设计可能出问题的case,纵轴是算法实现上可能出问题的case。接下来的debug过程就是组合你对这个bug收集到的信号,比如编译器错误、程序输出以及你的直观认识等。这些信号和先验知识帮助在上图上进行剪枝。
在机器学习范畴中,还有额外两个维度:真正适用的模型、数据。为了图示这两个维度,使用随机梯度下降(Stochastic Gradient Descent,SGD)训练逻辑回归(Logistic Regression,LR)是最简单的例子:
- 算法的正确性包括梯度下降更新等式;
- 实现的正确性包括特征和参数更新的正确计算;
- 数据中的bug包括噪声标注,预处理中的错误,没有选对特征,或者没有足够的数据。
- 模型中的bug可能是模型的描述能力不足,例如你选择了线性分类器来处理非线性问题。
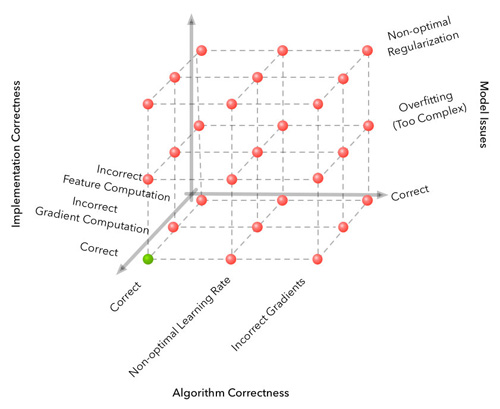
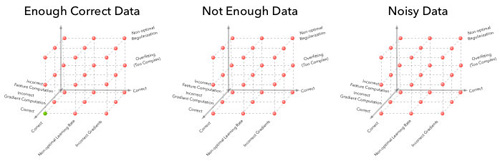
我们的Debug过程从二维网格扩展到了四维超立方体(上图为了清晰,只画了其中三维),第四维数据维可以可视化为下面的立体序列(注:一个正确的解答只有一个立方体)。
指数级难度的说法是指在2D空间,可能的错误方式数量是![]() ,而在4D空间,则为
,而在4D空间,则为![]() 。因此根据手头已有信息分析哪里出错的直觉成为机器学习基本功。幸运的是,机器学习算法有更多的信息可供使用,例如:训练集合和测试集合上的Loss分析,应用数据上的真实输出,算法中间输出的统计分析。
。因此根据手头已有信息分析哪里出错的直觉成为机器学习基本功。幸运的是,机器学习算法有更多的信息可供使用,例如:训练集合和测试集合上的Loss分析,应用数据上的真实输出,算法中间输出的统计分析。
延迟的Debug周期
机器学习Debug难的第二个因素是Debug周期很长。通常需要花费几十个小时甚至几十天来实现一个潜在的bug fix以及通过实际的输出判断是否成功。自动更新在机器学习领域往往不太现实,因为在训练集上跑一次的时间很长,Deep Learning模型尤其如此。Debug周期太长使得机器学习不得不采用并行模式,从而需要接触软件开发者并不熟悉的指令并行之类。
机器学习***目标往往落在建立直觉上,这种直觉是说根据现有信息能很快判断哪里出了问题,有什么办法可以改进等。这是你不断参与机器学习项目实践积累的最关键技术:你开始将一些信息与Debug空间中的疑似问题建立关联。
在原作的工作中,有很多这样的例子,例如,训练神经网络时碰到的早期问题周期性地反映在Loss函数中,Loss本来应该下降,但每次都跳回到一个更高的值,经过反复实验,最终学到这是因为数据集没有很好随机化,当你使用小batch SGD时这是个问题。
总之,快速有效Debug是现代机器学习中的必备技能。