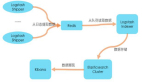
作为系列文章的第五篇,本文重点探讨数据采集层中的微信分享追踪系统。微信分享,早已成为移动互联网运营的主要方向之一,以Web H5页面(下面称之为微信海报)为载体,利用微信庞大的好友关系进行传播,实现宣传、拉新等营销目的。以下图为例,假设有一个海报被分享到了微信中,用户A与B首先看到了这个海报,浏览后又分享给了自己的好友,用户C看到了A分享的海报,浏览后继续分享给了自己的好友。这便形成了一个简单的传播链,其中蕴含了两种数据:
微信分享追踪系统")
- 行为,指的是用户对微信海报的操作,比如打开、分享。
- 关系,指的是在海报传播过程中,用户之间形成的传播关系,比如用户A将海报传播给C。
微信分享追踪系统")
这样的数据的意义在于:***,统计分析各个渠道的海报的传播效果;第二,对传播贡献较大的用户发放微信红包奖励,提高用户的分享积极性。微信分享追踪系统,便是完成对这两种数据的采集和存储。在过去的一年里,受到公司业务和运营推广方向的影响,这部分数据驱动了近一半的推广业务。
熟悉微信开发的朋友应该知道,***,每个微信用户在某个公众号下都拥有一个唯一的open_id,打开微信海报时,可以通过OAuth2静默授权在用户无感知的情况下拿到其open_id;第二,通过微信JS-SDK,我们可以捕捉到用户对海报页面的分享事件;第三,拿到用户在公众号下的open_id后,便可以对该用户发放微信红包了。基于这三点,我们便可以实现相关的数据追踪和分享奖励了,本文主要是总结我们在微信分享追踪上的方案演进。
首先要说一点的是,其实微信分享追踪系统本身并不复杂,但是与复杂的产品业务结合到一起,就变得越来越复杂了。如何做到将数据逻辑与产品业务逻辑剥离开,以不变应万变,就是这里要说的方案演进了。
1. 早期服务
早期的微信分享追踪系统,笔者曾经在浅谈微信公众号营销背后的技术一文中介绍过,其时序图如下所示。基本流程是:***,用户打开海报时,通过OAuth2授权,将open_id加入到页面链接中;第二,前端上报浏览事件,需要带上open_id和传播链信息;第三,用户分享时,需要在分享出去的链接中加上传播链信息,所谓传播链信息,就是每个分享过的用户的open_id组合,比如“open_id_1;open_id_2”;第四,上报用户的分享事件,需要带上open_id和传播链信息。后端收到上报数据后,根据不同的功能需求,将数据保存到不同的数据表中,用于后期消费。随着业务的发展,这个系统暴露出一些问题:
随着推广活动的调整,统计和奖励政策也随之变化,比如有的依据一度分享者的分享次数进行奖励,有的依据一度、二度分享者带来的浏览量进行奖励等等,还有需要根据上报的参数不同做不同的处理。所有逻辑都在上报的API请求中处理,来一个需求加一段逻辑,导致该请求的功能不断膨胀,而且一些推广活动已经下线了,相关的逻辑也没有清理掉。
参数比较混乱,页面URL中携带了不同的参数,包括微信相关参数、产品相关参数,前端上报时需要携带不同的参数,而前端页面太多,经常搞错。
微信分享追踪系统")
2. neo4j的尝试
于是,我们思考,有没有可能在后端直接构建完整的传播信息,后期使用时直接根据条件就可以查询出所需的数据,前端上报时也不用携带传播链信息,我们想到了图形数据库存储技术。
图形数据库是一种非关系型数据库,它应用图形理论存储实体之间的关系信息。在文章开头的那张传播图中,用户的行为数据其实可以归结为用户与海报之间的关系数据,这样,这个系统其实就包含两种实体:用户、海报,三种关系:用户打开海报、用户分享海报、用户之间的传播。在诸多图形数据库中,我们决定选择比较成熟、文档相对丰富的neo4j来做DEMO。采用neo4j的查询语法,很简单的就可以查询出所需数据,简单示例一下。
微信分享追踪系统")
下图呈现基于neo4j存储的新系统时序图,在OAuth2授权的重定向过程中,建立User和Poster节点信息,以及二者之间的OPEN关系信息,并且对页面URL计算hash值(去除无用参数信息),然后将用户open_id和URL的hash值加到页面URL中返回给前端。用户分享时,把该用户的open_id作为parent字段值,加到分享链接中,新用户打开该链接时,会根据该值来建立User与User节点之间的SPREAD关系信息。在用户分享的事件中,做一次数据上报,携带open_id和页面URL的hash值即可,后端拿到信息后,便可以建立User与Poster之间的FORWARD关系信息。如此,便可以建立完整的微信分享追踪数据了。
微信分享追踪系统")
然而,一切并非预期的那么***,在DEMO过程中,我们发现有两点问题不能很好的满足我们的需求:
无法根据时间条件快速查询信息,比如查询出昨天的一度分享者。
在查询用户间的关系时,会发生误判。比如在下图所示的传播关系中,UserA和UserC的传播关系是发生在海报PosterA上的,在PosterB上并没有,但是当我们尝试查询二度分享者时,会将UserA->UserC->PosterB误判为二度分享。
微信分享追踪系统")
虽然这些问题可以想办法绕过去,比如根据时间建立不同的实体节点等等,但是这样会把数据存储做复杂化,经过权衡,我们暂时搁置了这个方案。
3. 基于用户行为数据采集系统的方案
在创业公司做数据分析(三)用户行为数据采集系统一文中,曾经提到早期的数据采集服务是分散在各个业务功能中的,后来我们重新构建了统一的用户行为数据采集系统。在完成这个系统后,我们开始考虑将上述的微信分享追踪系统并入其中,主要工作有:
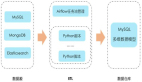
数据上报的流程与早期的系统一致,但是更换原有的上报方式,采用用户行为数据采集系统的方案统一上报微信分享的数据;
数据接入Kafka后,一方面直接将原始数据存储到Elasticsearch,另一方面,以worker的形式来消费数据,根据相应的业务需求提取出所需的数据存入格式化数据表中,用于统计和奖励活动。当某个推广活动结束后,将其所属的worker停掉即可。
微信分享追踪系统")
通过这样的改进,我们暂时解决了前端上报混乱和后端业务逻辑膨胀的问题,将数据上报和业务需求隔离开。数据方面,实时数据流在Kafka中,历史数据也在Elasticsearch中有存储;业务需求方面,来了一个新的需求后,我们只需添加一个新的worker来实现消费逻辑,活动结束后停掉worker。
点击查看:
创业公司做数据分析(一)开篇
创业公司做数据分析(二)运营数据系统
创业公司做数据分析(三)用户行为数据采集系统
创业公司做数据分析(四)ELK日志系统
创业公司做数据分析(六)数据仓库的建设