作为系列文章的第六篇,本文将重点探讨数据处理层中数据仓库的建设。在第二篇运营数据系统一文,有提到早期的数据服务中存在不少问题,虽然在做运营Dashboard系统时,对后台数据服务进行了梳理,构建了数据处理的底层公共库等,但是仍然存在一些问题:
中间数据流失,计算结果没有共享。比如在很多数据报告中都会对同一个功能进行数据提取、分析,但是都是各自处理一遍,没有对结果进行共享。
数据分散在多个数据源,如MySQL、MongoDB、Elasticsearch,很难对多个源的数据进行联合使用、有效组织。
每个人都需要非常清楚产品业务逻辑才能正确地提取、处理数据,导致大家都将大量时间耗费在基础数据处理中。
于是,我们考虑建设一个适于分析的数据存储系统,该系统的工作应该包含两部分:***,根据需求抽象出数据模型;第二,按照数据模型的定义,从各个数据源抽取数据,进行清洗、处理后存储下来。虽然数据仓库的学术定义有很多版本,而且我们的系统也没有涉及到多部门的数据整合,但是符合上述两个特点的,应该可以归结到数据仓库的范畴了,所以请允许笔者将本文命名为“数据仓库的建设”。
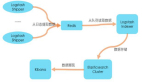
下图所示,为现阶段我们的数据仓库建设方案。数据主要来源于MySQL和MongoDB中的业务数据、Elasticsearch中的用户行为数据与日志数据;ETL过程通过编写Python脚本来完成,由Airflow负责任务流的管理;建立适于分析的多维数据模型,将形成的数据存入MySQL中,供数据应用层使用。可以看到,数据仓库本身既不生产数据也不消费数据,只是作为一个中间平台集中存储数据,整个系统实现的重点在于数据建模与ETL过程,这也是日常维护中的重点。
数据仓库的建设")
存储选型
将数据落地到哪里是首先要考虑的问题,笔者考虑的因素主要有这么几点:一是数据量大小和增长速度,二是要能实现SQL或者类SQL操作,有多表联合、聚合分析功能,三是团队技术栈。可选的技术方案有MySQL、Oracle和Hive,最终选择了基于MYISAM存储引擎的MySQL,部分原因如下:
要不要Hadoop? 生产业务数据库与用户行为数据增长均比较缓慢,预计在接下来的一年里数据仓库的总存储量不会超过500GB 。因此现阶段接入Hadoop的意义不大,强行接入反而会降低工作效率。而且团队主要技术栈是Python,使用Python操作Hadoop本身就会有性能损耗。
为什么是MySQL? 相比Oracle,团队对MySQL更加熟悉,所以笔者更多的考虑是选择MySQL的哪个存储引擎:Infobright vs. myisam vs. innodb。Infobright引入了列存储方案,高强度的数据压缩,优化的统计计算,但是目前已经没有社区版了,需要收费。抛开底层存储的区别,myisam与innodb在特性上的区别主要体现在三个方面:***,引用的一致性,innodb有外键,在一对多关系的表之间形成物理约束,而myisam没有;第二,事务,innodb有事务操作,可以保证一组操作的原子性,而myisam没有;第三,锁级别,innodb支持行锁,而myisam只支持表锁。对于外键与事务,并不是数据仓库需要的,而且数据仓库是读多写少的,myisam的查询性能优于innodb,因此myisam成为***。
数据建模
根据数据分析的需求抽象出合适的数据模型,是数据仓库建设的一个重要环节。所谓数据模型,就是抽象出来的一组实体以及实体之间的关系,而数据建模,便是为了表达实际的业务特性与关系所进行的抽象。数据建模是一个很宽泛的话题,有很多方法论值得研究,具体到业务上不同行业又会有不同的建模手法。这里主要结合我们的实践来简单地谈一些认识和方法。
目前业界有很多数据建模的方法,比如范式建模法、维度建模法等等。遵循三范式,我们在做业务数据库设计时经常会用到,这种方法对业务功能进行抽象,方便功能扩展,但是会额外增加分析的复杂度,因此笔者更倾向于维度建模法。维度建模法,是Kimball ***提出的概念,将数据抽象为事实表与维度表两种,而根据二者之间的关系将整体的模型划分为星型模型与雪花模型两种。这种建模方法的优势在于,根据各个维度对数据进行了预处理,比如按照时间维度进行预先的统计、分类等等,可以提高数据分析应用时的效率,是适于分析的一种方法。具体来看看几个概念:
维度表与事实表。维度表,描述的是事物的属性,反映了观察事物的角度。事实表,描述的是业务过程的事实数据,是要关注的具体内容,每行数据对应一个或多个度量事件。比如,分析“某地区某商品某季度的销量”,就是从地区、商品、时间(季度)三个角度来观察商品的销量,维度表有地区表、商品表和时间表,事实表为销量表。在销量表中,通过键值关联到三个维度表中,通过度量值来表示对应的销量,因此事实表通常有两种字段:键值列、度量值列。
星型模型与雪花模型。两种模型表达的是事实表与维度表之间的关系。当所有需要的维度表都直接关联到事实表时,看上去就是一颗星星,称之为星型模型;当有一个或多个维表没有直接关联到到事实表上,而是通过其他维度表连接到事实表上时,看上去就是一颗雪花,称之为雪花模型。二者的区别在于,雪花模型一定程度上降低了信息冗余度,但是合适的冗余信息能有效的帮助我们提高查询效率,因此,笔者更倾向于星型模型。
数据仓库的建设")
基本的维度建模思路。维度建模的基本思路可以归纳为这么几点:***,确定主题,即搞清楚要分析的主题是什么,比如上述的“某地区某商品某季度的销量”;第二,确定分析的维度,准备从哪几个角度来分析数据;第三,确定事实表中每行的数据粒度,比如时间粒度细化到季度就可以了;第四,确定分析的度量事件,即数据指标是什么。
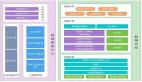
举个例子,业务场景是:一款做连锁企业招聘工作的产品,比如为麦当劳的所有连锁门店招聘员工,现在要分析“每家门店的招聘情况如何?”。结合具体业务,我们引入六个维度:时间维度、地区维度、品牌维度、门店维度、职位维度、申请渠道;数据指标上,主要有申请工作人数、申请工作次数、聘用人数、拒绝人数,每个指标分别有增量值和总量值两种;数据粒度上,时间维度细分到以小时为单位,地区维度细分到市一级。下图所示便是相应的星型模型,有三点值得一提:
可以看到我们只建立了四张维度表,地区维度和渠道维度是直接以字符串的形式放到事实表中的。这是维度设计中经常遇到的一个问题:如果这个维度只有一个属性,那么是作为单独的一张表还是作为事实表的一部分?其实并没有完全对与错的答案,只有是否适合自己的答案。这里,城市与渠道的信息并不会发生变化,所以放入事实表中可以避免联合查询。
建立了统一的时间维度,可以支持各种时间统计方案,避免在查询时进行时间值运算。
在品牌维度、门店维度、职位维度三张表中,都有prod_xxxx_id的字段,其值是产品业务数据库中相应数据的id,作用是为了与业务数据库中的信息进行同步。当业务数据库中的相关信息发生变化时,会通过ETL来更新数据仓库中的信息,因此我们需要这样的一个字段来进行唯一标识。
数据仓库的建设")
ETL
ETL这块,由于前期我们做了不少工作来构建底层数据分析公共库,能有效的帮助我们进行数据抽取与处理,因此,现阶段还没有引入诸如Kettle这样的开源工具,主要采用编写Python脚本来实现。这里主要谈谈增量更新机制与任务流管理两个问题的策略。
1. 增量更新机制
增量更新的背景是这样的:***,上面有提到,对于可变的维度表,我们添加了prod_xxxx_id字段来唯一标识,实现信息覆盖更新。对于事实表,为了反映历史状态,表中的数据通常是不可逆的,只有插入操作,没有删除或者修改操作,表示在过去一段时间内完成的事实业务数据,更新的方法就是插入新的数据。第二,ETL通常是近实时的,需要依赖schedule触发更新,因此每次需要更新的信息就是上一次更新时间与当前时间之间的变化数据。笔者采用的策略是:
- 建立一张temp表,表中有last_update_time与etl_name两个字段;
- 每次更新时,首先查询出相应的etl_name的最近一条记录,取其中的last_update_time作为起始时间,取当前时间为结束时间;
- 抽取数据源中在这段时间内变化的数据,作为ETL过程的输入,进行处理;
- 更新成功时,插入一条数据,last_update_time为当前时间。
2. Airflow任务流管理系统
在早期数据服务中,我们主要依靠crontab来运行各个任务,随着业务增多,任务的管理变得越来越吃力,体现在以下几方面:
- 查看任务的执行时间和进展不方便。每次需要查看某个任务的执行情况时,都要登录到服务器上去查看命令行的执行时间、log在哪里,通过ps来查看当前进程是否在运行等等。
- 任务跑失败后,没有通知与重试。
- 任务之间的依赖关系无法保证,完全靠预估,然后在crontab里设定执行时间间隔,经常出现上游还没有处理完,下游就启动了,导致脏数据的产生。
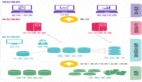
于是,我们开始考虑引入一个任务流管理系统,基本想法是:***,要能解决上述的问题;第二,***能与Python友好的兼容,毕竟团队的主要技术栈是Python。经过调研,发现Airflow是当前最适合我们的。Airflow是Airbnb公司开源的一款工作流管理系统,基于Python编写,兼容crontab的schedule设置方法,可以很简单的描述任务之间的逻辑与依赖,并且提供了可视化的WebUI用于任务管理与查看,任务失败时可以设置重试与邮件通知。这里贴一张官方的截图来一睹其风采。
数据仓库的建设")
Airflow有三个重要的概念:DAG、Task和Operator。DAG(directed acyclic graphs),有向无环图,用来表示任务的依赖结构;Task表示一个具体的任务节点;Operator表示某个Task的执行体是什么,比如BashOperator是执行一个Bash脚本,PythonOperator是执行一段python代码等等。使用Airflow,首先要编写对应的任务脚本,通常脚本需要做三件事:***,描述DAG的属性(比如schedule、重试策略等),第二,描述Task属性(比如Operator是什么),第三,描述Task的依赖情况。进一步的认识可以参考官方文档。
数据仓库的建设")
以上便是现阶段我们的数据仓库发展与建设方法,虽然比较简单,但是目前基本能满足需求。随着数据规模的增长和业务的复杂化,未来还有很多路要走:如何合理的建模?如何有效的利用数据?如何提高数据分析效率?期待更多的挑战!
点击查看:
创业公司做数据分析(一)开篇
创业公司做数据分析(二)运营数据系统
创业公司做数据分析(三)用户行为数据采集系统
创业公司做数据分析(四)ELK日志系统
创业公司做数据分析(五)微信分享追踪系统