看到这个题目,可能有些人会觉得奇怪——Object不是JS的基本数据类型么,有什么实现不实现的呢?如果你这么想的话,说明你没有接触过其它语言,一直都是在和JS打交道,编程世界那么大,你没有出去看一看。C/C++/Java等语言是没有这种json的数据类型的,其它一些有的:如在Pthyon里面叫做字典,在Ruby/Perl里面叫散列表,当然这只是个名称而已,本质上可以当作json类型。而C是“万物之母”,C里面没有的,就得通过某种方式实现。
并且JS里面的Object是如何查找属性的,这个问题有人说是通过遍历key的字符串查找的,也有人说是通过哈希查找的。究竟它是怎么存储和查找的,能不能把Object当作一个map来使用?如果无法从源码的角度实际地看一下浏览器的实现,你的观点可能就站不住脚,只能人云亦云。
Chrome自行开发了V8引擎,并被Node拿去当解析器。本文将通过V8的源码尝试分析Object的实现。
1. V8的代码结构
v8的源码位于 src/v8/src/ ,代码层级相对比较简单,但是实现比较复杂,为了能看懂,需要找到一个切入点,通过打断点、加log等方式确定这个切入点是对的,如果这个点并不是关键的点,进行到某一步的时候就断了,那么由这个点出发尝试去找其它的点。不断验证,***找到一个最关键的地方,由这个地方由浅入深地扩展到其它地方,***形成一个体系。
以下,先说明JS Object的类图。
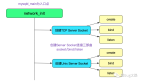
2. JS Object类图
V8里面所有的数据类型的根父类都是Object,Object派生HeapObject,提供存储基本功能,往下的JSReceiver用于原型查找,再往下的JSObject就是JS里面的Object,Array/Function/Date等继承于JSObject。左边的FixedArray是实际存储数据的地方。

3. 创建JSObject
在创建一个JSObject之前,会先把读到的Object的文本属性序列化成 constant_properties ,如下的data:
- var data = {
- name: "yin",
- age: 18,
- "-school-": "high school"
- };
会被序列成:
- ../../v8/src/runtime/runtime-literals.cc 72 constant_properties:
- 0xdf9ed2aed19: [FixedArray]
- – length: 6
- [0]: 0x1b5ec69833d1
- [1]: 0xdf9ed2aec51
- [2]: 0xdf9ed2aec71
- [3]: 18
- [4]: 0xdf9ed2aec91
- [5]: 0xdf9ed2aecb1
它是一个FixedArray,一共有6个元素,由于data总共是有3个属性,每个属性有一个key和一个value,所以Array就有6个。***个元素是***个key,第二个元素是***个value,第三个元素是第二个key,第四个元素是第二个key,依次类推。Object提供了一个Print()的函数,把它用来打印对象的信息非常有帮助。上面的输出有两种类型的数据,一种是String类型,第二种是整型类型的。
FixedArray是V8实现的一个类似于数组的类,它表示一段连续的内存,上面的FixedArray的length = 6,那么它占的内存大小将是:
- length * kPointerSize
因为它存的都是对象的指针(或者直接是整型数据类型,如上面的18),在64位的操作系统上,一个指针为8个字节,它的大小将是48个字节。它记录了一个初始的内存开始地址,使用元素index乘以指针大小作为偏移,加上开始地址,就可以取到相应index的元素,这和数组是一样的道理。只是V8自己封装了一个,方便添加一些自定义的函数。
FixedArray主要用于表示数据的存储位置,在它上面还有一个Map,这个Map用于表示数据的结构。这里的Map并不是哈希的意思,更接近于地图的意义,用来操作FixedArray表示的这段内存。V8根据 constant_properties的 length,去开辟相应大小空间的Map:
- Handle map = ComputeObjectLiteralMap(context, constant_properties,
- &is_result_from_cache);
把这个申请后的Map打印出来:
- ../../v8/src/heap/heap.cc 3472 map is
- 0x21528af9cb39: [Map]
- – type: JS_OBJECT_TYPE
- – instance size: 48
- – inobject properties: 3
- – back pointer: 0x3e2ca8902311
- – instance descriptors (own) #0: 0x3e2ca8902231
从第4行加粗字体可以看到,它的大小确实和我们算的一样。并且它还有一个叫做descriptors表示它的数据结构。descriptor记录了每个key-value对,以及它们在FixedArray里面的index. 后续对properties的操作基本上通过descriptor进行。
有了这个map的对象之后,用它来创建一个JSObect:
- Handle boilerplate =
- isolate->factory()->NewJSObjectFromMap(map, pretenure_flag);
重新开辟一段内存,把map的内容拷过去。
由于map只是一段相应大小的内存空间,它的内容是空的,所以接下来要设置它的properties:
- for (int index = 0; index < length; index += 2) {
- Handle<Object> key(constant_properties->get(index + 0));
- Handle<Object> value(constant_properties->get(index + 1));
- Handle<String> name = Handle<String>::cast(key);
- JSObject::SetOwnPropertyIgnoreAttributes(boilerplate, name,
- value, NONE);
- }
通过上面的代码,把properties设置到map的FixedArray里面,并且可以通过index用descriptors迅速地取出key-value。由于这个过程比较复杂,细节不展开讨论。
在设置properties的同时,会初始化一个searchCache,这个cache支持哈希查找某个属性。
4. 字符串哈希查找
在设置cache的时候,会先进行查找是否已存在相同的属性名,如果已经有了就把它的value值覆盖掉,否则把它添加到cache里面:
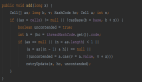
- int DescriptorArray::SearchWithCache(Isolate* isolate, Name* name, Map* map) {
- DescriptorLookupCache* cache = isolate->descriptor_lookup_cache();
- //找到它的index
- int number = cache->Lookup(map, name);
- //如果没有的话
- if (number == DescriptorLookupCache::kAbsent) {
- //通过遍历找到它的index
- number = Search(name, number_of_own_descriptors);
- //更新cache
- cache->Update(map, name, number);
- }
- return number;
- }
如上代码的注释,我们先来看一下这个Search函数是怎么进行的:
- template <SearchModesearch_mode, typename T>
- int Search(T* array, Name* name, int valid_entries, int* out_insertion_index) {
- // Fast case: do linear search for small arrays.
- const int kMaxElementsForLinearSearch = 8;
- if (valid_entries <= kMaxElementsForLinearSearch) {
- return LinearSearch<search_mode>(array, name, valid_entries,
- out_insertion_index);
- }
- // Slow case: perform binary search.
- return BinarySearch<search_mode>(array, name, valid_entries,
- out_insertion_index);
- }
如果属性少于等于8个时,则直接线性查找即依次遍历,否则进行二分查找,在线性查找里面判断是否相等,是用的内存地址比较:
- for (int number = 0; number < valid_entries; number++) {
- if (array->GetKey(number) == name) return number;
- }
因为name都是用的上面第三点设置Map的时候传进来的name,因此初始化的时候相同的name都指向同一个对象。所以可以直接用内存地址进行比较,得到FixedArray的索引number。然后用key和number去update cache:
- cache->Update(map, name, number);
重点在于这个update cache。这个cache的数据结构是这样的:
- static const int kLength = 64;
- struct Key {
- Map* source;
- Name* name;
- };
- Keykeys_[kLength];
- int results_[kLength];
它有一个数组keys_的成员变量存放key,这个数组的大小是64,数组的索引用哈希算出来,不同的key有不同的哈希,这个哈希就是它在数组里面的索引。它还有一个results_,存放上面线性查找出来的number,这个number就是内存里面的偏移,有了这个偏移就可以很快地定位到它的内容,所以放到results里面.
关键在于这个哈希是怎么算的。来看一下update的函数:
- void DescriptorLookupCache::Update(Map* source, Name* name, int result) {
- int index = Hash(source, name);
- Key& key = keys_[index];
- key.source = source;
- key.name = name;
- results_[index] = result;
- }
先计算哈希索引index,然后把数据存到results_和keys_这两个数组的index位置。这个Hash函数是这样的:
- int DescriptorLookupCache::Hash(Object* source, Name* name) {
- // Uses only lower 32 bits if pointers are larger.
- uint32_tsource_hash =
- static_cast<uint32_t>(reinterpret_cast<uintptr_t>(source)) >>
- kPointerSizeLog2;
- uint32_tname_hash = name->hash_field();
- return (source_hash ^ name_hash) % kLength;
- }
先计算map和key的hash,map的hash即source_hash是用map的地址的低32位,为了统一不同指针大小的区别,而计算key的hash即name_hash,最核心的代码应该是以下几行:
- uint32_tStringHasher::AddCharacterCore(uint32_trunning_hash, uint16_t c) {
- running_hash += c;
- running_hash += (running_hash << 10);
- running_hash ^= (running_hash >> 6);
- return running_hash;
- }
依次循环name的每个字符串做一些位运算,结果累计给running_hash.
source_hash是用map的内存地址,因为这个地址是唯一的,而name_hash是用的字符串的内容,只要字符串一样,那么它的hash值就一定一样,这样保证了同一个object,它的同个key值的索引值就一定一样。source_hash和name_hash***异或一下,模以kLength = 64得到它在数组里面的索引。
这里自然而然会有一个问题,通过这样的计算不能够保证不同的name计算出来的哈希值一定不一样,好的哈希算法只能让结果尽可能随机,但是无法做到一定不重复,所以这里也有同样的问题。
先来看一下,它是怎么查找的:
- int DescriptorLookupCache::Lookup(Map* source, Name* name) {
- int index = Hash(source, name);
- Key& key = keys_[index];
- if ((key.source == source) && (key.name == name)) return results_[index];
- return kAbsent;
- }
先用同样的哈希算法,算出同样的index,取出key里面的map和name,和存储的map和name进行比较,如果相同则说明找到了,否则的话返回不存在-1的标志。一旦不存在了又会执行上面的update cache,先调Search找到它的偏移index作为result,如果index存在重新update cache。所以上面的问题就可以得到解答了,重复的哈希索引覆盖了***个,导致查找***个的时候没找找到,所以又去重新update,把那个索引值的数组元素又改成了***个的。因此,如果两个重复的元素如果循环轮流访问的话,就会造成不断地查找index,不断地更新搜索cache。但是这种情况还是比较少的。
如何保证传进来的具有相同字符串的name和原始的name是同一个对象,从而才能使它们的内存地址一样?一个办法是维护一个Name的数据池,据有相同字符串的name只能存在一个。
上面的那个data它的三个name的index在笔者电脑上实验计算结果为:
- #name hash index = 62
- #age hash index = 32
- #-school- hash index = 51
有一个比较奇怪的地方是重复实验,它们的哈希值都是一样的。并且具有相同属性且顺序也相同的object,它们的map地址就是一样的。
如果一个元素的属性值超过64个呢?那也是同样的处理,后面设置的会覆盖前面设置的。学过哈希的都知道,当元素的个数大于容器容量的一半时,重复的概率将会大大增加。所以一个object的属性的比较优的***大小为32。一旦超过32,在一个:
- for(var keyin obj){
- obj[key] //do sth.
- }
for循环里面,这种查找的开销将会很大。
那为什么它要把长度设置成64呢,如果改大了,不就可以减少重复率?但是这样会造成更多的内存消耗,即使一个Object只有一个属性,它也会初始化一个这么大的数组,对于这种属性比较少的object来说就很浪费。所以取64,应该是一个比较适中的值。
同时另一方面,经常使用的那几个属性还是能够很快通过哈希计算定位到它的内容。并且这种场景还是很常见的,如获取数组元素的lengh.
根据上面的讨论,将Object当作map来使用,并不是很合适,在如下的代码里面:
- var data = [10001, 10002/* 很多个元素 */];
- var keys = {
- "1000a": ''
- "1000b": ''
- /* 很多个属性 */
- }
- var exists = [];
- for(var i = 0; i < data.length; i++){
- if(typeof keys[data[i]] !== "undefined"){
- exists.push(data[i]);
- }
- }
由于在keys查找时,可能会存在大量没有的元素,这样就导致它哈希查找没有找到,然后需要进行线性查找/二分查找,结果也没找到。所以它和哈希map还是有很多的差别的。这样的效率虽然比不上直接使用一个哈希map,但至少它的效率要比写一个数组,然后一个个去比较来得高效,怎么说它还是用的内存地址进行二分查找。
这里就体现了ES6新增了Map/Set类型的价值,它是一个真正的哈希Map。如果不能使用ES6的map,那么自行实现一个或者使用第三方的库也是可取的。
在说Map之前,Object还有数字类型的属性没有讨论。
5. 数字索引哈希查找
假设data变成:
- var data = {
- name: "yin",
- age: 18,
- "-school-": "high school",
- 1: "Monday",
- 2: "Thuesday",
- "3": "Wednesday"
- };
把生成的data Object打印出来是这样的:
- ../../v8/src/runtime/runtime-literals.cc 105 boilerplate obj:
- 0x3930221af3a9: [JS_OBJECT_TYPE]
- – map = 0x6712e19cc41 [FastProperties]
- – prototype = 0x27d71d20f19
- – elements = 0x2e1e1a56b579 [FAST_HOLEY_ELEMENTS]
- – properties = 0x2c2a4d782241 {
- #name: 0x3930221aec51 (data field at offset 0)
- #age: 18 (data field at offset 1)
- #-school-: 0x3930221aecb1 (data field at offset 2)
- }
- – elements = {
- 0: 0x2c2a4d782351
- 1: 0x3930221aecf9
- 2: 0x3930221aed39
- 3: 0x3930221aed79
- 4-18: 0x2c2a4d782351
- }
那些key为数字的存放在elements的数据结构里面,elements和properties的区别在于——elements有独立的一个哈希表,并且它不是覆盖存放的,它会根据哈希值算元素的数组索引,判断如果当前索引已经存在元素,则一直找到下一个空的位置来存放它:
- uint32_tcapacity = Capacity();
- uint32_tentry = FirstProbe(hash, capacity);
- uint32_tcount = 1;
- // EnsureCapacity will guarantee the hash table is never full.
- while (true) {
- Object* element = KeyAt(entry);
- if (!IsKey(isolate, element)) break;
- entry = NextProbe(entry, count++, capacity);
- }
- return entry;
为什么数字的key要单独这么搞呢?如果把它当成一个字符串的key按上面字符串处理的逻辑也是行得通的。原因可能是一方面如果key是数字,那在在算哈希值可以做一个优化,另一方面数字的key可能会有很多个就像上面提的例子,使用者可能把object当作一个map来用,所以为它作一个优化。
可以说elements几乎是一个真正意义的哈希表。
然后再来简单看一下ES6的Map的实现
6. ES6 Map的实现
这里有一个比较有趣的事情,就是V8的Map的核心逻辑是用JS实现的,具体文件是在 v8/src/js/collection.js ,用JS来实现JS,比写C++要高效多了,但是执行效率可能就没有直接写C++的高,可以来看一下set函数的实现:
- function MapSet(key, value) {
- //添加一个log
- %LOG("MapSet", key);
- var table = %_JSCollectionGetTable(this);
- var numBuckets = ORDERED_HASH_TABLE_BUCKET_COUNT(table);
- var hash = GetHash(key);
- var entry = MapFindEntry(table, numBuckets, key, hash);
- if (entry !== NOT_FOUND) return ...//return代码省略
- //如果个数大于capacity的二分之一,则执行%MapGrow(this)代码略
- FIXED_ARRAY_SET(table, index, key);
- FIXED_ARRAY_SET(table, index + 1, value);
- }
第三行添加一个log函数,确认确实是执行这里的代码。%开头的LOG,表示它是一个C++的函数,这个代码写在runtime.h和runtime.cc里面。这些JS代码***会被组装成native code。在V8里,除了Map/Set之外,很多ES6新加的功能,都是用的JS实现的,如数组新加的很多函数。
上文介绍了Object是如何实现的,重点分析了V8是如何存储一个Object的属性,并用了一个真正的Map作为参照。***的结论是Object属性主要是通过哈希查找的,但是它不太适合拿来当作哈希Map使用,特别是当key很多并且都是字符串的时候。
其它的浏览器引擎可能会有不同的实现,但是至少不会笨到直接用key的字符串进行遍历。笔者将尝试在下一篇介绍Array的实现,特别是分析一下它的操作函数是如何实现的。