R的诞生
1992年, 肉丝 (Ross Ihaka)和 萝卜特 (Robert Gentleman)两个人在S语言(贝尔实验室开发的一种统计用编程语言)的基础上开始构思一种新的用于统计学分析的开源语言,直到1995年第一个版本正式发布(和各位年龄相仿)。因为他们名字的第一个字母都是R,所以这门语言就被叫做R。这两个人都是统计学教授出身,再加上R语言的生父S语言,所以 R语言在统计学方面有着纯正的血统 !

如果你平时的工作会涉及到统计学,那么接触R语言实在是太正常不过了。
另外,关于R语言的开发者,看名字(Ross和Robert)部分人以为是伉俪,其实就是两个大老爷们。如图所示
R的发展
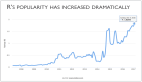
作为开源软件的R能够迅速发展,很大程度上取决于其活跃的社区。学习R,很大程度上也是学习各种R包的使用。截止目前(2017年2月25日),CRAN(Comprehensive R Archive Network)上已经有10162个可以获取的R扩展包,内容涉及各行各业,可以适用于各种复杂的统计。各地的CRAN镜像都是R网站的备份文件,内容完全一样,你可以选择离自己最近的去访问。
R的特长
在R官网有这样几句介绍
R provides a wide variety of statistical (linear and nonlinear modelling, classical statistical tests, time-series analysis, classification, clustering, …) and graphical techniques, and is highly extensible.
One of R’s strengths is the ease with which well-designed publication-quality plots can be produced, including mathematical symbols and formulae where needed.
- 因为R语言本身为统计而生,所以你能想到的所有统计相关的工作,R都可以非常简洁的用几行命令(甚至1行命令)帮你完成。
- R高度的可扩展性正是体现在它那1万多个包上,你想做的几乎所有事情都可以用现有的R包来辅助完成(当然,有些工作即便能完成但也不适合)。
- R另一个杀手锏就是其强大的绘图功能,正如上面的英文介绍所言,R可以画图,画各种各样的图,画各种各样高逼格的图,画各种各样高逼格可以直接出版的图。
- 完善的统计学功能再加上强大的绘图功能,就是你学习的最大理由。
- 对于生物相关的工作者而言,他们还有一个巨大的福利就是Bioconductor,这里面的一千多个R包都是用来解决生物(信息)问题的。
R应用示例
在这一部分,仅仅是给展示几个用R可以轻松完成的相对有趣的工作。
安装对应包后应该可以直接运行
示例1 ggplot2画图
#第一次使用,需要安装相应的包
#以后只需要调用即可
#install.packages("ggplot2")
library("ggplot2")
theta <- seq(0,24*pi, len=2000)
radius <- exp(cos(theta)) - 2*cos(4*theta) + sin(theta/12)^5
dd <- data.frame(x=radius*sin(theta), y=radius*cos(theta))
ggplot(dd, aes(x, y))+geom_path()+xlab("")+ylab("")
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
效果展示

示例2 词频分析及词云
# install.packages("wordcloud2")
library(wordcloud2)
wordcloud2(demoFreqC, size = 0.7, shape = 'diamond')
- 1.
- 2.
- 3.
效果展示

示例3 查看我国各地空气质量
#install.packages("rvest")
#install.packages("leafletCN")
#install.packages("rgeos")
Sys.setlocale("LC_CTYPE", "eng")
library(rvest)
library(leafletCN)
library(rgeos)
doc = read_html("http://www.pm25s.com/cn/rank/")
cities = doc %>% html_nodes(".cityrank a") %>%
html_text()
cities = iconv(cities, "UTF-8", "UTF-8")
AQI = doc %>% html_nodes("span[class^='lv']") %>%
html_text() %>% .[c(F,F,T)] %>% as.numeric
dat = data.frame(city = cities, AQI = AQI)
geojsonMap(dat, "city",
popup = paste0(dat$city,":",dat$AQI),
palette = "Reds", legendTitle = "AQI")
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
效果展示

如何尝试入门R语言
一开始这一部分的标题是 如何学好R语言 ,但是写这部分东西需要很强的功底,我知道自己根本谈不上学好。
后来又打算叫 如何入门R语言 ,但是每个人能付出的精力和能力又各不相同,而且因为平时我用R的地方不太多,只是最近担任助教才又开始继续学习。为了避免看了文章却没入门的朋友来吐槽,机智如我,干脆就叫 如何尝试入门R语言 。
学习路线
看到这篇文章的一部分人很可能是我担任助教这门课(生物统计学)的同学,而另一部分人很可能与生物信息学相关。
为了通过考试
如果你是前者而且仅仅是为了通过最后的考试,我建议你只需要在每节理论课后认真理解老师上课的内容,在每节讨论课后拿出两三天消化我们作业题中用到的R语言知识点就可以了。
- 大致了解一下R语言是什么,能干什么用(看完这篇文章,这部分就可以了)。
- 学习如何在R的官网下载R,如何在自己的电脑安装R并成功运行。
- 学习如何安装Rstudio,并且了解其基本的用法(这步可省略)。
- 学习如何查看R帮助文档(这步很重要)。
- 学习如何将作业中的数据(作业中通常是txt或者csv格式)正确地导入R。
- 了解R语言中的常见变量。
- 学习R语言一些最基本的命令,如安装包、调用包、读入写入文件、构造矩阵和基础绘图等。
- 学习在R中如何使用(课上提到的)统计学相关函数,了解其参数的含义。
- 能够独立完成最后几次作业和上一年的期末考试题。
生物信息学相关
- 了解R语言在生物信息学领域的应用。
- 理解R语言中的各种变量。
- 学习如何创建数据集、清洗数据和使用常见的统计分析方法。
- 能够对数据进行高级操作,对数据进行转换。
- 学习R语言的中高级绘图方法,能够使用ggplot2。
- 学习R中高级统计分析方法,如聚类、主成分分析和线性回归等。
- 学习并熟练使用自己研究领域相关的R包(通过bioconductor)。
个人感觉,如果能完成上述几条学习路线,那么R语言就算入门了。
入门的标准是什么呢?我想就是给你一份数据让你处理,你脑子里的第一反应是可不可用R做;如果给你一个任务,你能上手尝试用R去解决。