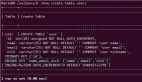
什么是HBase?
HBase(Hadoop Database)是Apache的Hadoop项目的子项目,是一个分布式的、面向列的开源数据库,就像Bigtable利用了Google文件系统(GFS)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。
为什么采用HBase?
HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库,HBase是介于Map Entry(key & value)和DB Row之间的一种数据存储方式,有点类似于现在流行的Memcache,但不仅仅是简单的一个key对应一个 value,你还可以根据需要存储多个属性的数据结构,但没有传统数据库表中那么多的关联关系,这就是所谓的松散数据。
简单来说,你在HBase中创建的表可以看做是一张很大的表,而这个表的属性可以根据需求去动态增加,在HBase中没有表与表之间关联查询。你只需要告诉你的数据存储到HBase表的哪个column families 就可以了,不需要指定它的具体类型:char,varchar,int,tinyint,text等等。但是你需要注意HBase中不包含事务此类的功能。
Apache HBase 和Google Bigtable 有非常相似的地方,一个数据行拥有一个可选择的键和任意数量的列。表是疏松的存储的,因此用户可以给行定义各种不同的列,对于这样的功能在大项目中非常实用,可以简化设计和升级的成本。
HBase与传统RDBMS的区别

应用场景
有时候了解软件产品的***方法是看看它是怎么用的。它可以解决什么问题和这些解决方案如何适用于大型应用架构,能够告诉你很多。因为HBase有许多公开的产品部署,我们正好可以这么做。本章节将详细介绍一些人们成功使用HBase的使用场景。
注意:不要自我限制,认为HBase只能解决这些使用场景。它是一个初生的技术,根据使用场景进行创新正驱动着系统的发展。如果你有新想法,认为可以受益于HBase提供的功能,试试吧。社区很乐于帮助你,也会从你的经验中学习。这正是开源软件精神。
互联网搜索应用
BigTable,和模仿出来的HBase,为这种文档库提供存储,BigTable提供行级访问,所以爬虫可以插入和更新单个文档。搜索索引可以基于BigTable 通过MapReduce计算高效生成。
捕获增量数据
数据通常是细水长流,累加到已有数据库以备将来使用,例如分析,处理和服务。许多HBase使用场景属于这个类别—使用HBase作为数据存储,捕获来自于各种数据源的增量数据。例如,这种数据源可能是网页爬虫(我们讨论过的互联网搜索应用问题),可能是记录用户看了什么广告和多长时间的广告效果数据,也可能是记录各种参数的时间序列数据。
半结构化或非结构化数据
对于数据结构字段不够确定或杂乱无章很难按一个概念去进行抽取的数据适合用HBase。例如,当业务发展需要存储用户的email,phone,address信息时RDBMS需要停机维护,而HBase支持动态增加。
记录非常稀疏
RDBMS的行有多少列是固定的,为null的列浪费了存储空间。HBase为null的Column不会被存储,这样既节省了空间又提高了读性能。
多版本数据
根据Row key和Column key定位到的Value可以有任意数量的版本值,因此对于需要存储变动历史记录的数据,用HBase就非常方便了。比如用户表的address是会变动的,业务上一般只需要***的值,但有时可能需要查询到历史值。
超大数据量
当数据量越来越大,RDBMS数据库撑不住了,就出现了读写分离策略,通过一个Master专门负责写操作,多个Slave负责读操作,服务器成本倍增。
随着压力增加,Master撑不住了,这时就要分库了,把关联不大的数据分开部署,一些join查询不能用了,需要借助中间层。
随着数据量的进一步增加,一个表的记录越来越大,查询就变得很慢,于是又得搞分表,比如按ID取模分成多个表以减少单个表的记录数。经历过这些事的人都知道过程是多么的折腾。
采用HBase就简单了,只需要加机器即可,HBase会自动水平切分扩展,跟Hadoop的无缝集成保障了其数据可靠性(HDFS)和海量数据分析的高性能(MapReduce)。
【本文为51CTO专栏作者“朱国立”的原创稿件,转载请通过作者微信公众号“开发者圆桌”获取联系和授权】