












3月下旬,中国电信大数据技术团队邀请达观数据技术团队前去进行技术交流和互相学习。达观数据联合创始人文辉就“视频推荐技术”进行了详细的讲解,主要从达观推荐系统开发的概况、推荐系统的架构模块和达观推荐算法来阐述,并针对操作中出现的问题分享了自己的观点。
推荐系统概况
说了那么多遍的推荐系统到底是什么且如何运用?很高兴和大家分享下经验。我们今天主要从视频推荐技术来延伸学习。互联网技术和社会化网络发展加速度,每天有大量包括博客,图片,视频,微博等等的信息发布到网上。对于以视频为主要流量导向的企业越来越难以发现用户对信息的需求,原因有多种,用户很难用合适的关键词来描述自己的需求,又或是用户无法对自己未知而又可能感兴趣的信息做出描述。我们开发视频推荐引擎,也是以大数据技术帮用户获取更丰富,更符合个人口味和更加有意义的信息。
视频推荐系统会根据用户的观看记录和行为,利用机器推荐算法为用户推荐其感兴趣的视频。智能推荐系统是为了解决千人一面的问题,防止用户看到的推荐结果都是千篇一律的,真正实现千人千面的个性化推荐效果,给用户更好的体验,给平台更好的留存和收益。
达观视频智能推荐系统的研发目标集中在以下方面:
l 推荐结果相关性明显提升
l 推荐结果的多样性提升
l 推荐结果的时效性提升
l 新颖的推荐理由自动生成功能
以上研发目标都是为了使视频推荐效果更加准确、及时,现经不断优化已经完成所有目标,但系统还在持续优化升级。
从系统的效果上来看,我们要实现:
l 更完整的挖掘数据
l 多种优质推荐算法
l 完善的系统:可靠性,运算性能
l 更好的接口封装:支持多种终端的接入
从系统的组成上来看,系统主要包括以下几个方面,注意各个部分的功能不是单一和互斥的:
l 分布式推荐模块——用户点击行为挖掘
l 离线推荐模块——多个推荐算法合并
l 在线推荐模块——实时推荐请求和计算
l 个性化推荐模块——用户兴趣深度挖掘
l 推荐理由挖掘模块——多种形态的理由
达观视频推荐系统不同于其他企业的部分是,从类型上来看相当多样化,分为个性化推荐、相关视频推荐和热门视频推荐三种,每种类型对应了不同的业务场景。
个性化推荐“想你所想”
深入分析用户行为记录,挖掘用户的兴趣爱好,向用户推荐其感兴趣想看的视频,通常意义的推荐默认就是个性化推荐;
相关视频推荐“丰富扩展”
通过深入分析网站视频之间的内在相关性,根据当前被浏览的某个视频为用户推荐其视频;
热门视频推荐“广而告之”
为网站提供全站热门视频排行榜和分类热门视频排行榜
推荐系统的架构和模块
三层模型
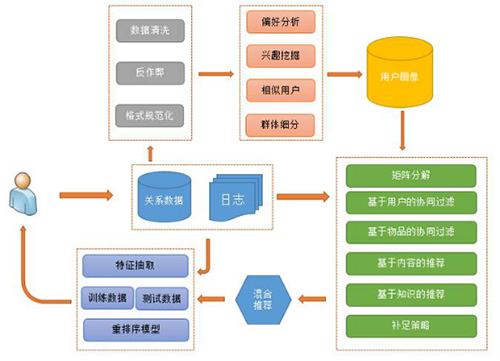
为了解决待推荐item数量巨大和优先的计算资源之间的矛盾,同时将更多的资源投入到热门item的深度挖掘,我们引入了三层模型:离线模块(offline)、近线模块(nearline)、在线模块(online)。离线模块利用分布式平台上进离线挖掘,候选推荐结果每日带入离线计算服务器;近线模块在近线端进行挖掘,结合用户实时行为和离线模型结果,生成用户的推荐结果;在线模块负责整合离线结果和近线结果为最终输出用户的结果。从时效性上来看,离线(天级)>近线(分钟级或者秒级)>在线(毫秒级),从效果上来看离线好于近线,近线好于在线。三层模型更好解决了新视频和新用户的无推荐结果的问题。
分布式的挖掘模块,会生成一些推荐的候选集,其中包括热门挖掘模块、推荐理由挖掘模块、内容系统挖掘模块。这些离线系统生成的挖掘结果会响应的存入到hdfs或者db中;
离线计算模块,会对这个结果进行再次加工,包括合并、融合等,其中可能还有处理业务的逻辑。离线模块对这些结果进行再次加工之后,最终的推荐结果,会存到一个redis db中;
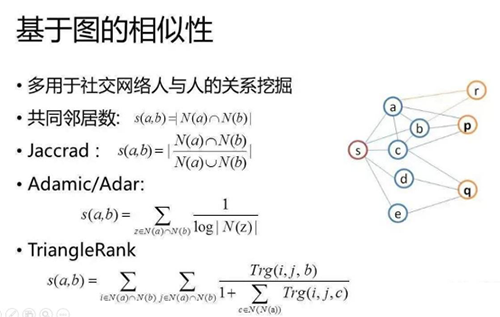
online模块就会直接从我们redis的是slaver中直接去读取推荐结果,快速返回推荐内容。
从接口层来看,推荐服务是以HTTP API的方式来提供服务,接口后端包括多机的负载均衡,并支持各终端通用(Web/Android/iOS…)各端接入,同时提供多种推荐类型:个性化推荐、相关推荐、热门推荐。
推荐候选池candidate模块会生成多种类型的推荐结果,比如使用标签去倒排中查出一部分的结果,协同过滤的结果、热门的一些结果,包括分类热门和编辑推荐结果,也会作为我们推荐的候选池。
正反馈数据是线上推荐结果的用户反馈,比如在推荐列表中,我们会发现某些排序在后的结果好于排序在前的结果,那么这部分结果也可以作为推荐候选。
推荐候选池就是最终生成推荐结果的候选池,最终的推荐结果就是从候选池中筛选得到的。
视频推荐相关视频模块,该模块的输入就是需要处理的一些视频ID队列,从输出来看就是每个视频的相关推荐结果。比如每个视频都预存了64个推荐结果,存储到redis中,当redis缓存不能***时,可调用online模块实时计算,解决冷启动的问题。
features模块其实就是一个正排找视频信息的功能,根据视频ID去获取其一些基本信息,包括标题、描述、标签、点击数、前后缀。
Ranking模块是权值计算和排序的模块,此模块是对候选结果视频权值进行再次计算,一些不合格的视频我们需要剔除。对于推荐视频的相关性,我们可能要进行加权,某些优质用户的视频也要进行加权。
Filtering视频过滤:UGC上传的视频时长很短,许多视频间标题又很类似,这就存在大量重复资源,所以我们推荐结果也要过滤推荐结果中相同的视频进行去重,去重会让用户的体验更加友好。
Reranking排序后处理,对返回给用户的推荐结果进行一个ranking,也就是说,我们给用户推荐的10个推荐视频的同时,还要保证视频质量和多样性。
Reranking具体策略包括从推荐理由、视频类别还有推荐效果各个方面把推荐结果顺序打散,不至于连续多个推荐结果都是通过某个标签推荐的。
实时用户行为反馈:特别针对一些新用户,我们会及时捕捉新用户的行为,随后更新用户的用户画像,然后去优化推荐效果。
如果一个用户点击了A视频和B视频,又看了C视频,在C视频的“猜你喜欢”推荐结果中,已使用了A、B视频的特征。虽然A、B、C这3个视频本身可能没什么关联,因为用户的喜好都不是单一的。
Feedback点击反馈:用户会对推荐结果会有点击或者其他行为,那么根据这些行为,就可以优化推荐结果的排序。但点击反馈也存在一些困难点,包括位置偏向、技术性点击作弊和感知相关性。其中,位置偏向问题比较普及。
开源技术:使用hadoop或spark等分布式计算平台进行离线数据挖掘,采用HBase进行视频信息和用户行为存储,使用redis来存储推荐结果,利用Redis的主从同步技术实现多机高可用方案,还有采用Tornado作为Http Interface的接口调用API。
推荐算法
1
热门算法门算法
最简单是对item的单一维度的评分,比如视频播放数、视频上传时间、视频评论数,接着会对单一维度进行升级,便会考虑多个维度的综合评分。比如多个维度的线性加权得出分后再进行排序,同时在计算这些评分过程中,需要考虑这些物品的时间因素,对一些时效性较强的item,会根据它的时间新旧进行筛减。
按照点击率进行排名时,还需要考虑它的置信度。比如说同样是1%的点击,10000次展现里的100次点击的物品,它的1%的点击率自信度肯定要大于100次展现里的仅有1次点击的item的置信度。可以考虑用威尔逊区间的方法对这些物品的ctr进行降权。***则要防止马太效应,要考虑推荐多样性和效果平衡。
2
内容算法
根据视频类的标题,基于文本挖掘技术,挖掘出视频的关键标签。比如短视频标题:“美国泥瓦匠辣舞走红网络摆臂扭臀电力十足”,通过达观文本挖掘技术可以自动提取出此视频最主要的两个标签,“泥瓦匠”和“辣舞”,作为这个视频的Top2标签。这里要注意视频的属性特征不仅仅包括标签,还包括系列视频、作者账号,视频类别等。
内容算法如何应用于相关推荐和个性化推荐?
在相关视频推荐这部分,我们得到视频的特征向量,比如视频的作者、类别、标签之后,就可以用这些特征去我们倒排索引中进行搜索和匹配,那么查出来的结果就能作为相关推荐的结果。

内容算法应用于个性化推荐,会比相关推荐多一走步。我们会生成用户的profile向量,就是用户模型的向量。这个向量会计算用户对类别、标签、作者的一个偏好,通过用户的向量和视频的向量,计算这两个向量的(余弦)相似度,那么就可以得到用户对视频的得分。
3
协同过滤算法
协同过滤算法利用群体智慧为用户进行推荐,对于视频来说就是看了又看。
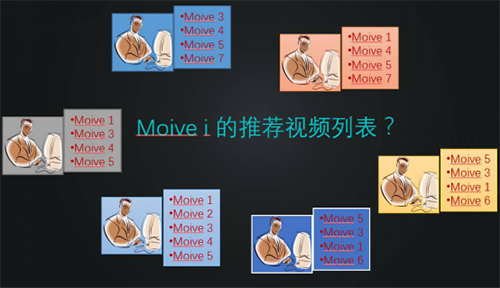
比如上图,我们可以看到1号视频和5号视频,会经常同时出现在很多用户的观看记录中,那么用户在观看了1号视频后,为其推荐5号视频则会是非常合理,也非常容易让用户进行点击。
协同过滤算法的输入是用户的播放行为日志,需要注意的是对日志的预处理。比如一个用户对一个视频有多次播放记录的话,则需要进行排重,只保留一个用户对一条视频的唯一一条播放记录。
协同过滤算法具体的计算流程:
比如:计算A视频和B视频,包括两个视频播放的单天频次、历史频次、单天共现(单天同被观看的就是单天共现,也就是说都被同一个人所点击所观看的用户数。)、历史共现(历史贡献是指历史上A视频、B视频都被同一个用户所观看的用户数),计算出此4个指标后,就可以计算出A视频和B视频的关联度、相似度。
同时在计算相似度的时候,我们还需要考虑时间因子,需要对历史共现的数据和历史频次的数据进行降权,要更加侧重于新数据的影响力。
4
用户建模
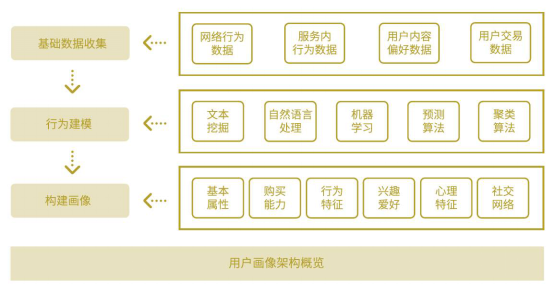
用户建模架构图主要包括三个部分,用户数据的采集和预处理,数据统计和特征提取、智能挖掘分析。
***部分包括用户行为数据的采集,同时对不合法的数据、爬虫数据等进行过滤等,形成基础数据;第二个部分为数据统计和特征抽取模块,会从基础数据里对用户的行为特征进行抽取,还有一些基础特征、统计特征,对这些特征抽取完毕之后,有一个智能挖掘分析模块对这些特征数据进行深入的挖掘,利用机器学习分类技术预测用户的人口统计学属性、挖掘用户长期偏好、短期偏好。
用户偏好挖掘,也就是对用户兴趣的挖掘,包括用户对视频作者、视频类别和视频标签的偏好。在计算这些偏好时,我们也要同时考虑它的支持度和置信度。比如一个用户在最近一周内看了10个关于足球的视频,同时在这一周内,我们所有的用户平均观看足球视频的个数只有0.5个,那么可以明显看出这个用户对足球类别的偏好远远超出平均水平。
5
多策略融合
融合策略会在所有算法生成推荐结果后,比如内容算法、协同过滤、矩阵分解等单算法结果,对所有结果进行策略合并,可能也会考虑一些业务逻辑规则。
机器学习重排序的方法可以对这些推荐结果进行重排,使用系统的正反馈和负反馈的数据去进行训练。训练完毕后,我们会预测用户对推荐结果的概率,排序后生成最终展现给客户的视频推荐列表,经过一系列算法融合后的推荐列表,用户对推荐视频的点击率会比之前提升3倍。
在接入我们视频推荐的客户当中,推荐视频的点击率是达到翻倍甚至3倍以上效果,这都跟我们以上讲的所有框架、算法息息相关,实践是检验真理的唯一标准,我们多年的实践开发,实践应用,都说明了达观开发的系统能在推荐领域得以很好的应用,我们也将一直在推荐领域不断学习巩固。
Q&A
Q:视频推荐系统的应用场景?
A:类似于酷六、今日头条视频页面,由UGC上传的短视频或长视频,以视频信息流方式或个性化信息流展示的方式,都可以应用视频推荐系统。
Q:位置偏向问题是指什么?
A:是指一个排在前面视频的点击率高于排在后面视频的点击率,并不一定是指是前面视频推荐效果好于后面视频,而只是因为位置的关系。因此,在用点击行为对推荐结果进行反馈时,要考虑位置偏向问题。
Q:Tornado是什么意思?
A:python版的http server,它支持异步,不仅轻量而且性能很好。
Q:协同过滤算法中,历史数据和新数据如何计算权重?
A:可以进行线上的A/B测试,比如人工先设置某个值,然后在线上的测试中看效果,进行人工调参。这个权重原则上是可以根据业务调整的,比如对于短视频强调时效性,那么历史数据的权重就可以小些;比如对于小说时效性不强,历史数据的权重就可以大一些,一般新数据的权重都是1,历史数据的权重在(0,1)之间。
Q:能否分享下多年的推荐系统相似工作经验?
A:做数据挖掘、做推荐系统好多年,一些经验告诉我们要有效提升,基本上百分之五十的精力都在做数据预处理,但是数据预处理的工作都是属于脏活累活,但要把数据预处理做好,后面这些算法效果才能事半功倍的,拿到数据后去重、去燥,然后清洗、结构化等等。
还需要很多工作,像自然语言处理,它在很多项目推荐系统跟用户画像里都起到非常重要的作用。而用户画像又分为静态用户画像和动态用户画像,动态用户画像比静态用户画像更直接一些。这些都需要认真专业的团队去研究不断开发。












